
The Tableau Public Viz Gallery at Tableau Conference 2024
Explore the 2024 Viz Gallery featuring 31 captivating vizzes from global creators. Tableau Public
Tableau Public7 Ways to Stand Out and Secure Your Next Data Analytics Role
 Tips for getting hired, creating a free data visualization portfolio, connecting with other data enthusiasts, landing your dream data viz job, and more.
Tips for getting hired, creating a free data visualization portfolio, connecting with other data enthusiasts, landing your dream data viz job, and more.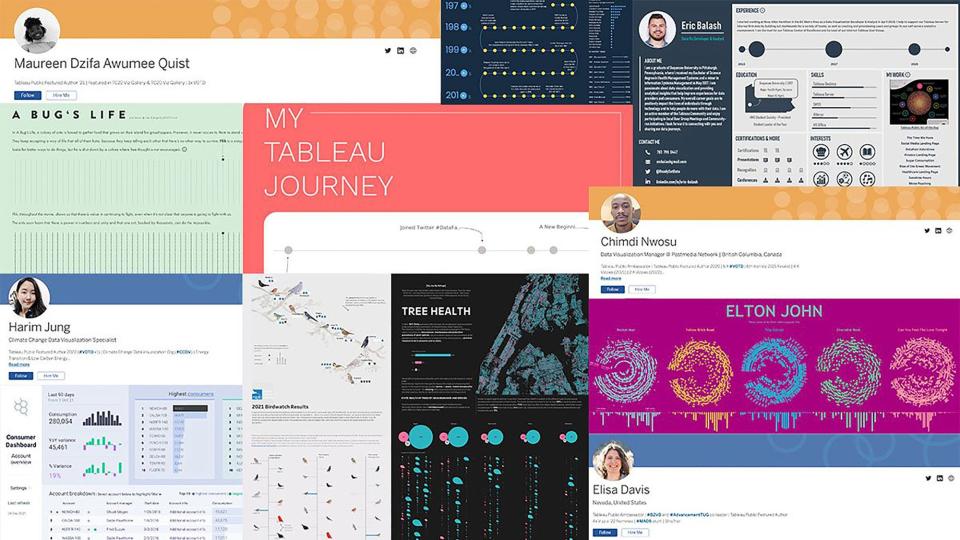 Tableau Public
Tableau PublicA Beginner's Guide to Tableau Public
 A step-by-step guide to get you started on your own data viz journey.
A step-by-step guide to get you started on your own data viz journey.
 Tableau Community
Tableau CommunityThe Vizzies at Tableau Conference 2024
 May 10, 2024
For the community, by the community. Join hosts Emily Kund and Matt Francis as they celebrate the 2024 Vizzie Award winners.
May 10, 2024
For the community, by the community. Join hosts Emily Kund and Matt Francis as they celebrate the 2024 Vizzie Award winners.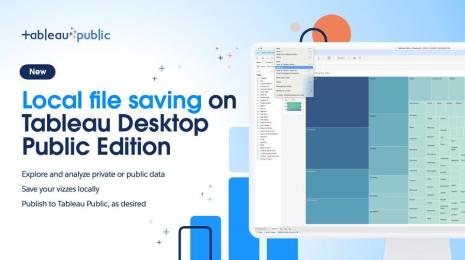 Tableau Public
Tableau PublicLocal File Save with Tableau Desktop Public Edition
 April 30, 2024
Local file saving is available for all Tableau Desktop Public Edition users for free.
April 30, 2024
Local file saving is available for all Tableau Desktop Public Edition users for free. Tableau Public
Tableau PublicThe Tableau Public Viz Gallery at Tableau Conference 2024
 April 29, 2024
Explore the 2024 Viz Gallery featuring 31 captivating vizzes from global creators.
April 29, 2024
Explore the 2024 Viz Gallery featuring 31 captivating vizzes from global creators.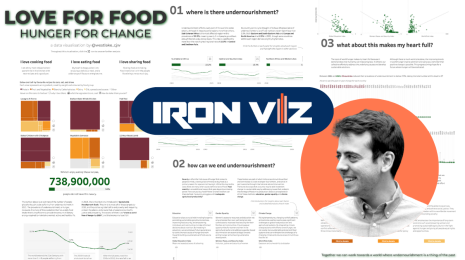 Iron Viz
Iron VizMeet Iron Viz 2024 Finalist Chris Westlake
 April 22, 2024
Chris Westlake has an insatiable appetite for data visualization and big love for the Tableau Community.
April 22, 2024
Chris Westlake has an insatiable appetite for data visualization and big love for the Tableau Community.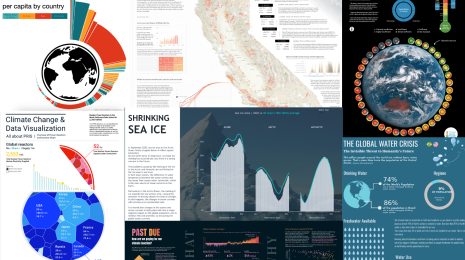 Tableau Public
Tableau PublicVisualizing Climate Change: Expert Tips from #TheSDGVizProject Leaders
April 22, 2024
Get expert guidance for visualizing climate data and inspiration from a curated gallery of data visualizations from the DataFam. Tableau Community
Tableau CommunityMeet Iron Viz 2024 Finalist Jessica Moon
April 15, 2024
Iron Viz finalist Jessica Moon picked a light-hearted topic for her qualifying viz but seriously impressed the judges. Tableau Community
Tableau CommunityMeet Iron Viz 2024 Finalist Pata Gogová
April 8, 2024
A qualifying viz dealing with the dark side of love propelled Pata Gogová to the Iron Viz finals at her first attempt. Tableau Community
Tableau CommunityStudent to BI Analyst, How Tableau Can Lead to a Successful Data Career
 March 20, 2024
This student harnessed the power of Tableau Public for data learning and networking to get her first job in business intelligence.
March 20, 2024
This student harnessed the power of Tableau Public for data learning and networking to get her first job in business intelligence. Visualizations
VisualizationsVisualizing Women's Impact to History Through Data Visualization
March 18, 2024
Recognizing and honoring women throughout history with 36 vizzes from the DataFam. Community Projects
Community ProjectsPractice and Grow Your Data Skills with Tableau Community Projects
March 5, 2024
Learn how skills-based data visualization challenges can help you skill up in data. Tableau Public
Tableau PublicBehind the Viz: Adrian Zinovei Helps You Design Your Next Dashboard
March 1, 2024
Get to know your fellow Tableau Public authors with Behind the Viz, a blog series where we explore the people and processes behind our featured vizzes. Tableau Public
Tableau PublicFeatured Authors: Black History Month Edition 2024
 February 15, 2024
Join in celebrating the achievements and impact of the African American Tableau Community throughout February.
February 15, 2024
Join in celebrating the achievements and impact of the African American Tableau Community throughout February.
Subscribe to our blog
Get the latest Tableau updates in your inbox.