To See and Understand Queries



How does a Tableau visualization become a query? Via a compiler and query optimizer, but what is this compiler/optimizer, and how does one understand the resulting query expressions?
Query Graphs, our open-source query visualization library, was conceived to visualize these query expressions and understand their behavior. Developed in collaboration with Tableau engineers, the visualization library facilitates new query features, debugging, and query performance analysis. The library has also been used to illustrate federated queries in academic research and teach query compilation.
Thus, Query Graphs facilitates a mission similar to that of Tableau. Tableau helps people to see and understand data by fusing graphics and databases, following the principles of visual understanding, and facilitating the cycle of visual analysis. Similarly, Query Graphs creates visual and interactive representations of query expressions using accepted visualization techniques for exploring large, complex, directed acyclic graphs, such as pan and zoom, multiple levels of detail, and color.
Query Graphs is available for external use, either as a stand-alone visualizer, embedded within the open-source Tableau Log Viewer, or integrated as a JupyterLab extension. The library supports visualization of PostgreSQL query plans as well as generic XML and JSON. Supported Tableau formats include Logical Query XML and Hyper Query Plan JSON. Committers may easily add additional database systems and formats.
The technical innovations facilitating Tableau’s mission begin with VizQL, representing the user’s drag-and-drop actions as a visual query. The visual query is compiled and optimized in Tableau’s Data Pipeline for execution as one or more SQL statements. This SQL is tailored for execution in Tableau’s Hyper Data Engine or as a live query to other data systems. It is further compiled into a native query execution plan.A Tableau Logical Query expression or Hyper Query Plan of execution is represented as a Directed Acyclic Graph (DAG) of query nodes, e.g., reading data [Extract], projecting data [project], filtering data [select], performing calculations [project/aggregate], and joining data [join]. These query nodes are connected by edges that determine how data flows from node to node.
For example, the following drag-and-drop specification for a bar chart in a Tableau worksheet computes the sum of arrival delay in minutes by airline name from data on flights and airports.
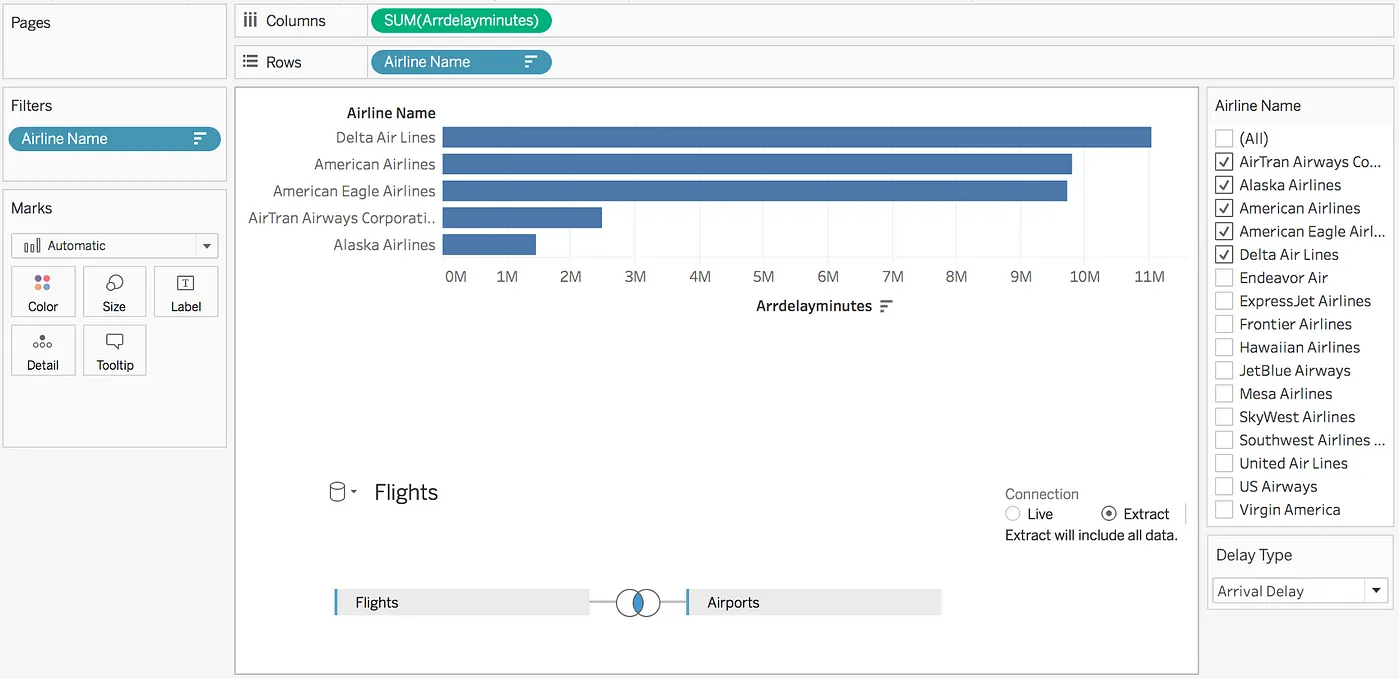
The worksheet ultimately emits a SQL query for the underlying data — this SQL query results from compiling and optimizing the VizQL query specification using the Logical Query DAG.
<

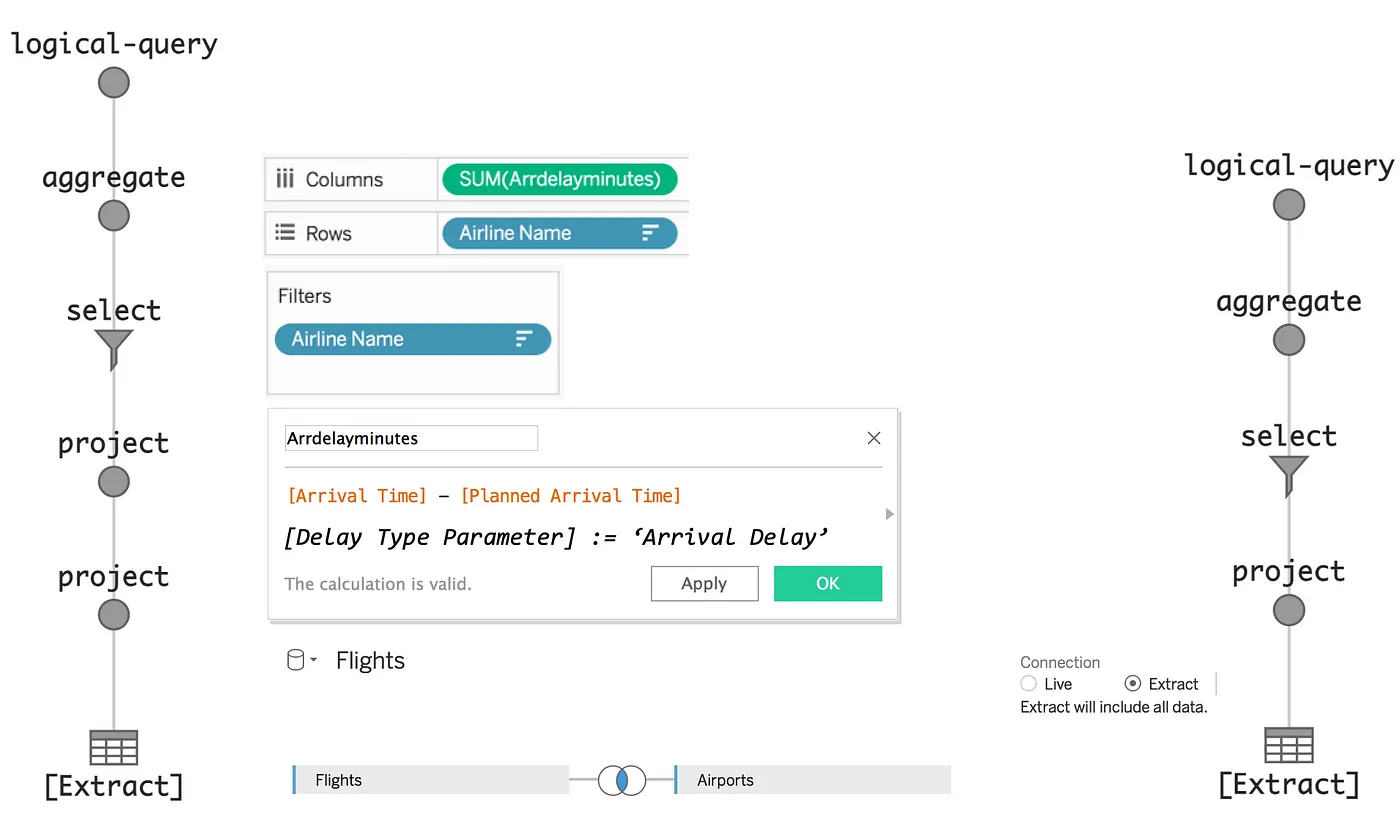
In the following image, the optimized Logical Query (on the right) has one less project node than the unoptimized version (on the left) after substituting the [Delay Type] parameter specifying ‘Arrival Delay’ rather than ‘Departure Delay’ into a conditional calculation that may compute one or the other type of delay. (For additional optimization details of this and other use cases, see the Tableau Conference talk “Show me the queries!”.)
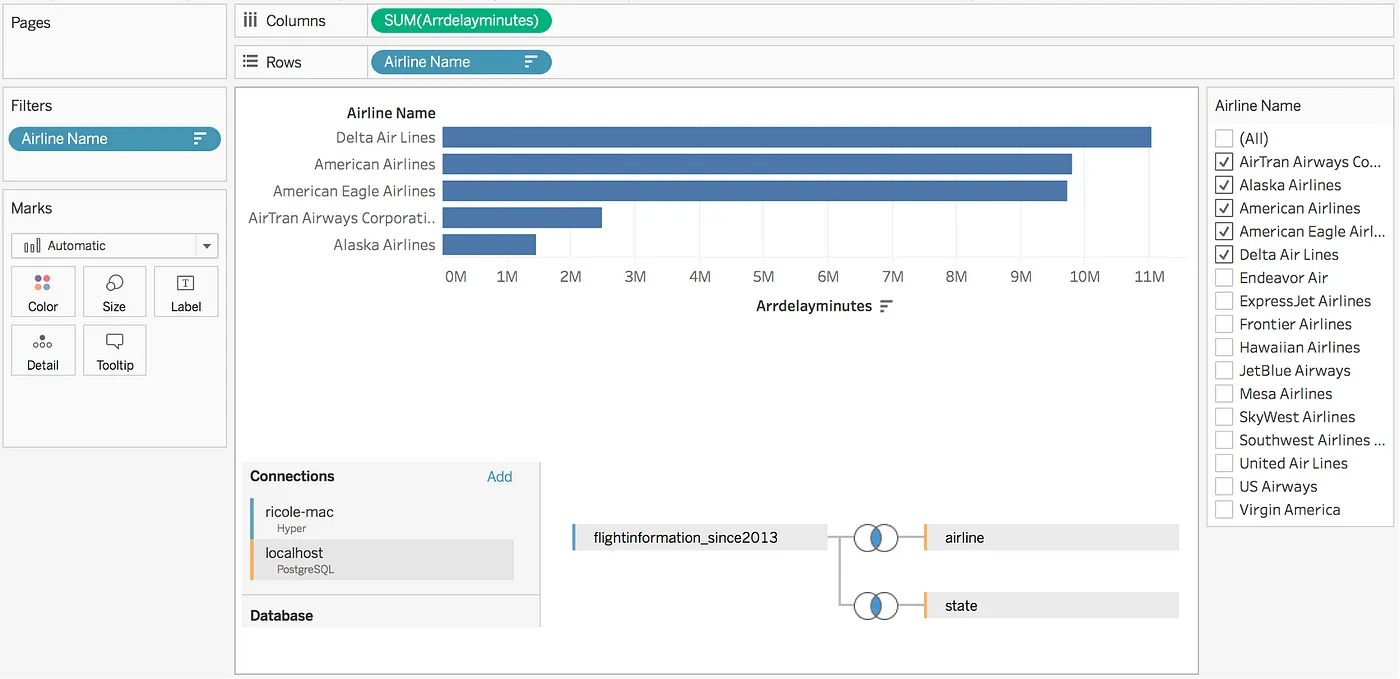
The next bar chart is similar; however, the three data sources (bottom right of the image) come from two different connections or systems (bottom left of the image). The Tableau Data Pipeline must orchestrate data movement from the remote systems to a common location to be joined.
The data orchestration is made clear in the following Logical Query. The flight information, airline, and state data are accessed via three different (blue and orange) subqueries on the right side of the diagram and returned in three temporary tables at the top. These tables are then consumed and joined by the (green) subquery on the left. This particular image capture comes from the aforementioned Tableau Log Viewer via interaction with a federate-query log record, one of many associated with the worksheet's queries and data.
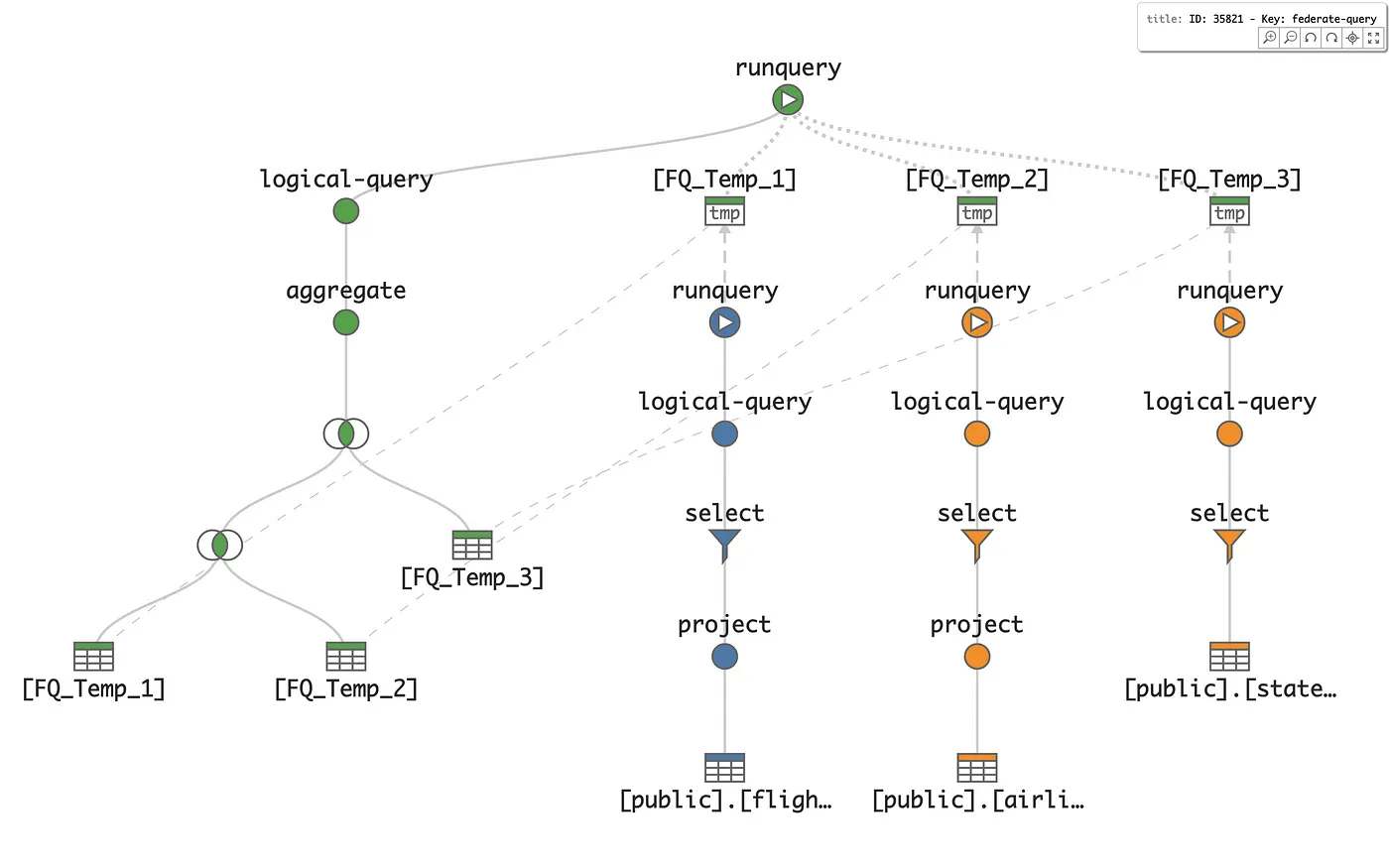
A similar interactive version of this Logical Query visualization is hosted on tableau.github.io as Federated Query, where one may pan (left click + drag) and zoom (mouse wheel) the visualization. Additional interactions include node level properties and crosslinks between nodes (mouse hover) and details such as schema information and filters (left click).
Tableau developers use these visualizations to develop new product features, such as federated queries, aka cross-database joins in Tableau 10. Such visualizations are also a key requirement for query debugging. Analysis of query performance is also enhanced, as we will see below.
The query visualizations themselves are interactive so that details do not overwhelm our understanding of query processing. Nodes support extensive hover text and may also be expanded to show additional details, for example, detailed calculations represented by their own subgraph. These graphs use accepted visualization techniques for exploring large, complex, directed acyclic graphs, such as pan and zoom, multiple levels of detail, metric annotations, and scented widgets.
The following PostgreSQL query plan’s visual focus is the metric annotations on the links between nodes. The two comma-separated numbers represent the number of intermediate rows flowing between nodes as estimated by the PostgreSQL query optimizer, followed by the actual number of rows processed during query execution. They are highlighted when they differ by more than an order of magnitude, a common cause of poor query performance. For example, the optimizer may choose a preferred join order if accuracy were improved by updating or refining statistics using database facilities.
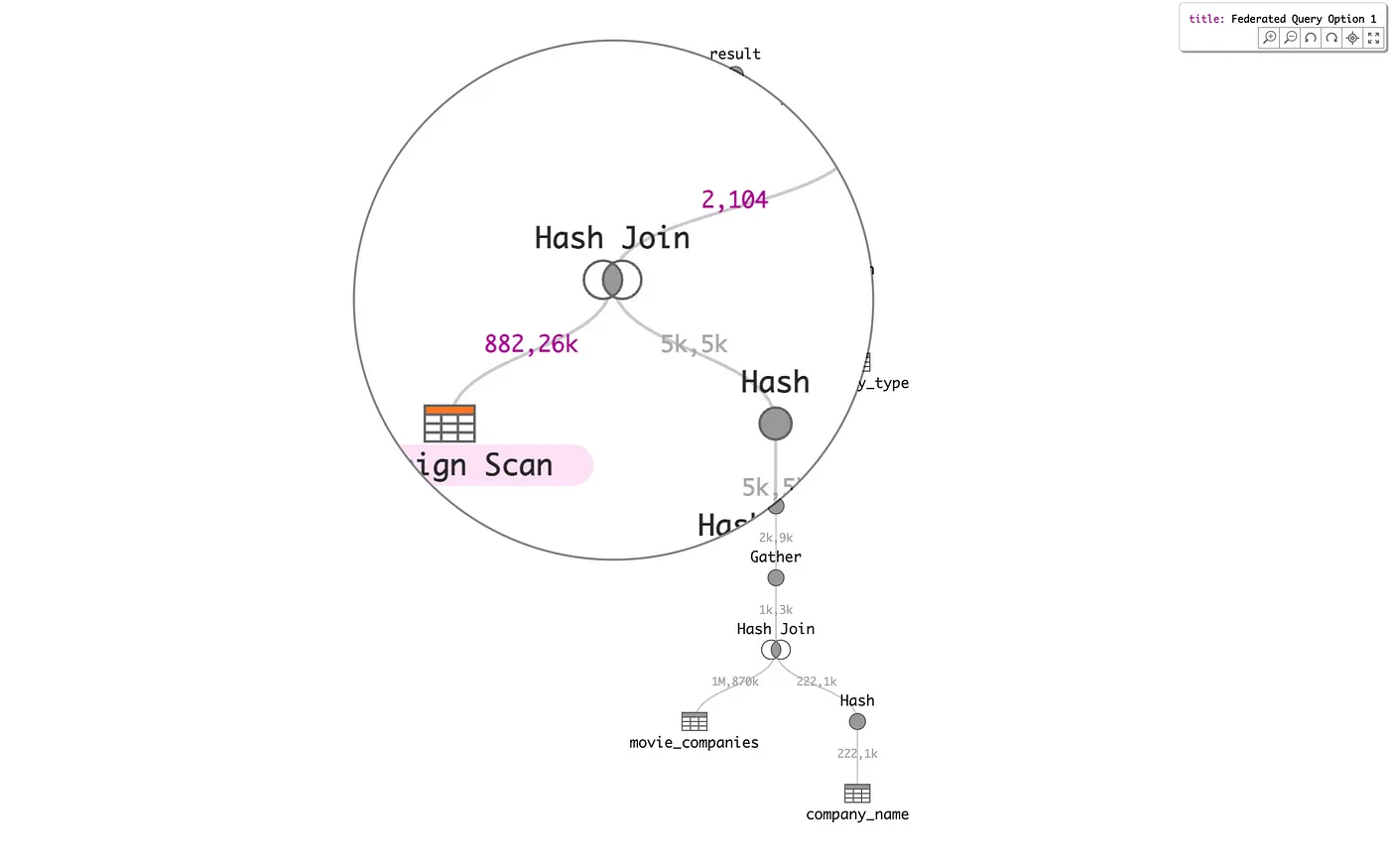
Next, the focus is on a node widget scented via color map according to the system on which it is executed (red table symbol) and a large amount of time spent executing that node relative to the overall plan execution time (dark violet pill). These highlighted nodes may indicate performance bottlenecks. Redistributing the data may mitigate this particular hotspot.
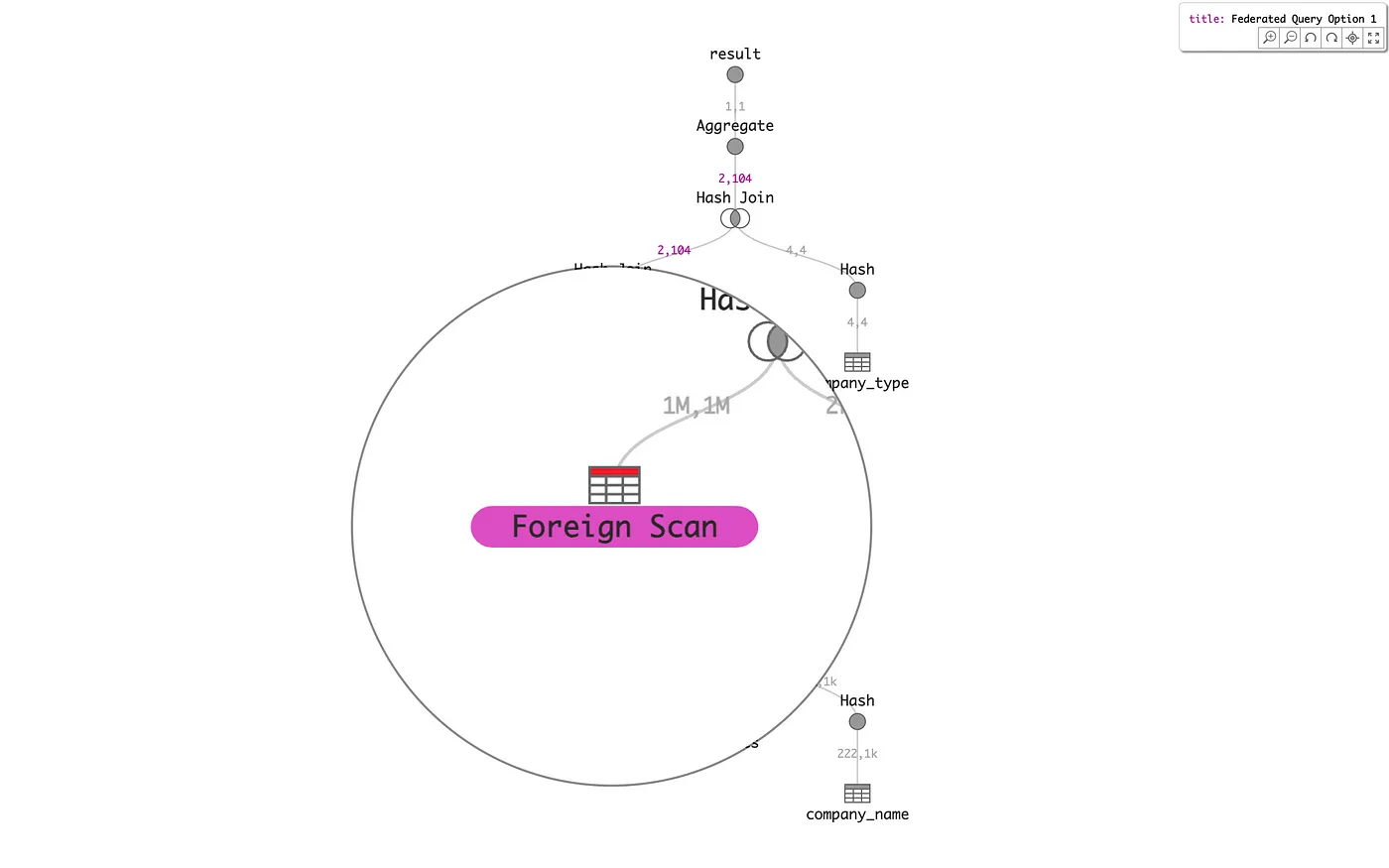
Finally, consider the overall shape and composition of a single federated PostgreSQL query, from Learning to Optimize Federated Queries, represented here by the following three alternative query plans. These three plans differ by their locus of execution, i.e., on which of three systems is the distributed data joined. The Option 2 query plan has the lowest Execution Time, which is 10x less than the worst-case Option 1. It is easy to see via the scented node color map that Option 2 distributes execution time more evenly between nodes than Option 1 or Option 3.
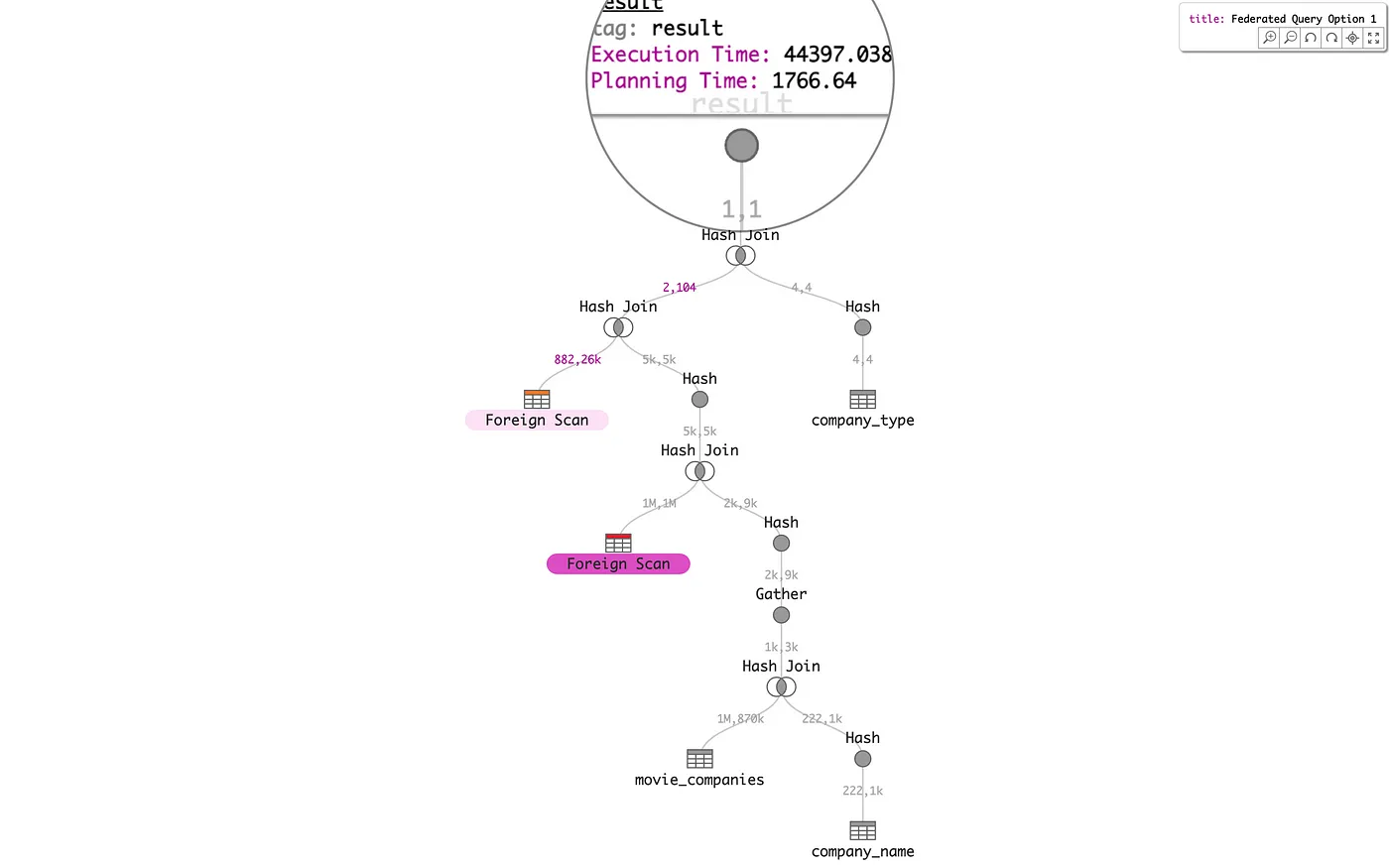
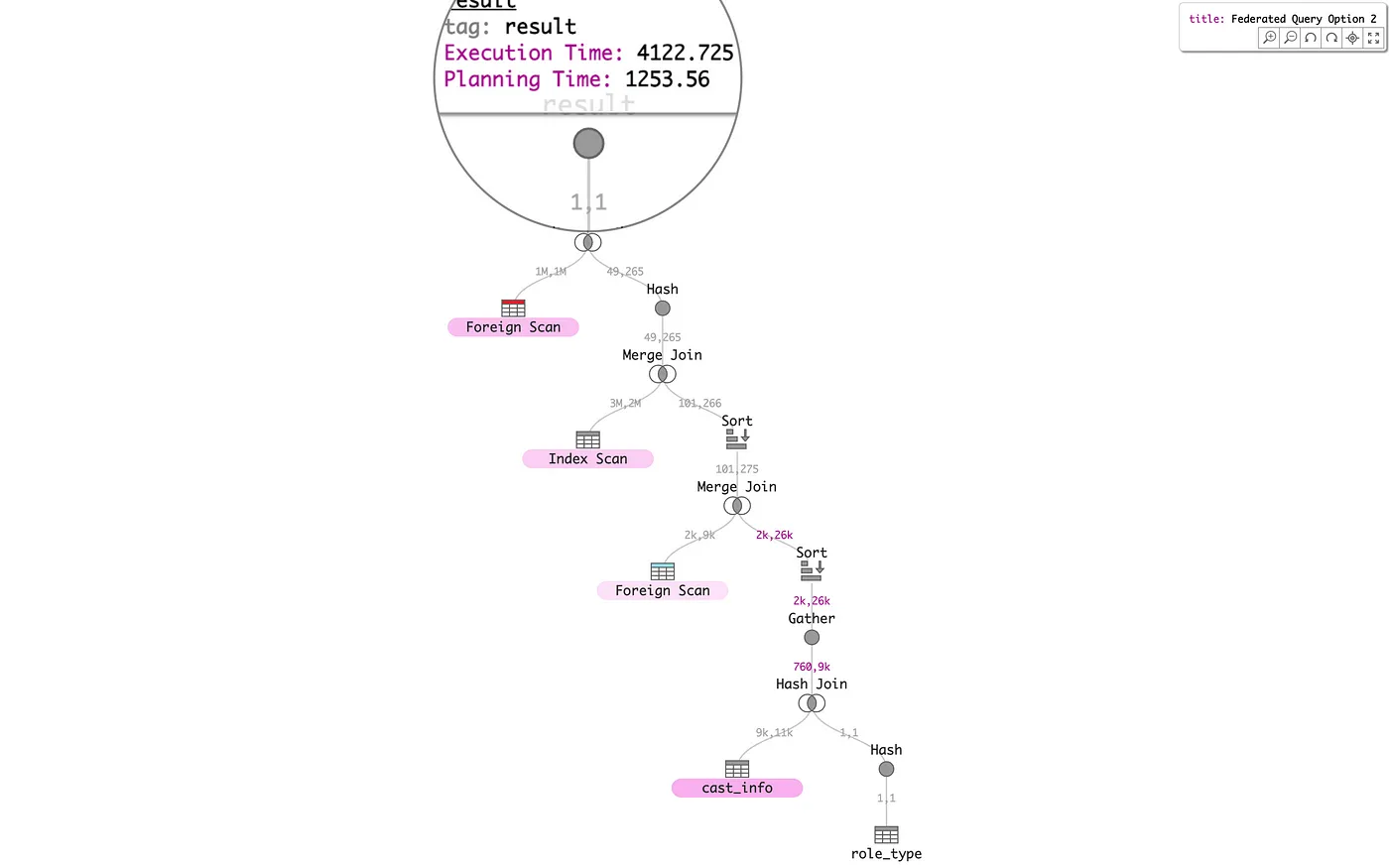
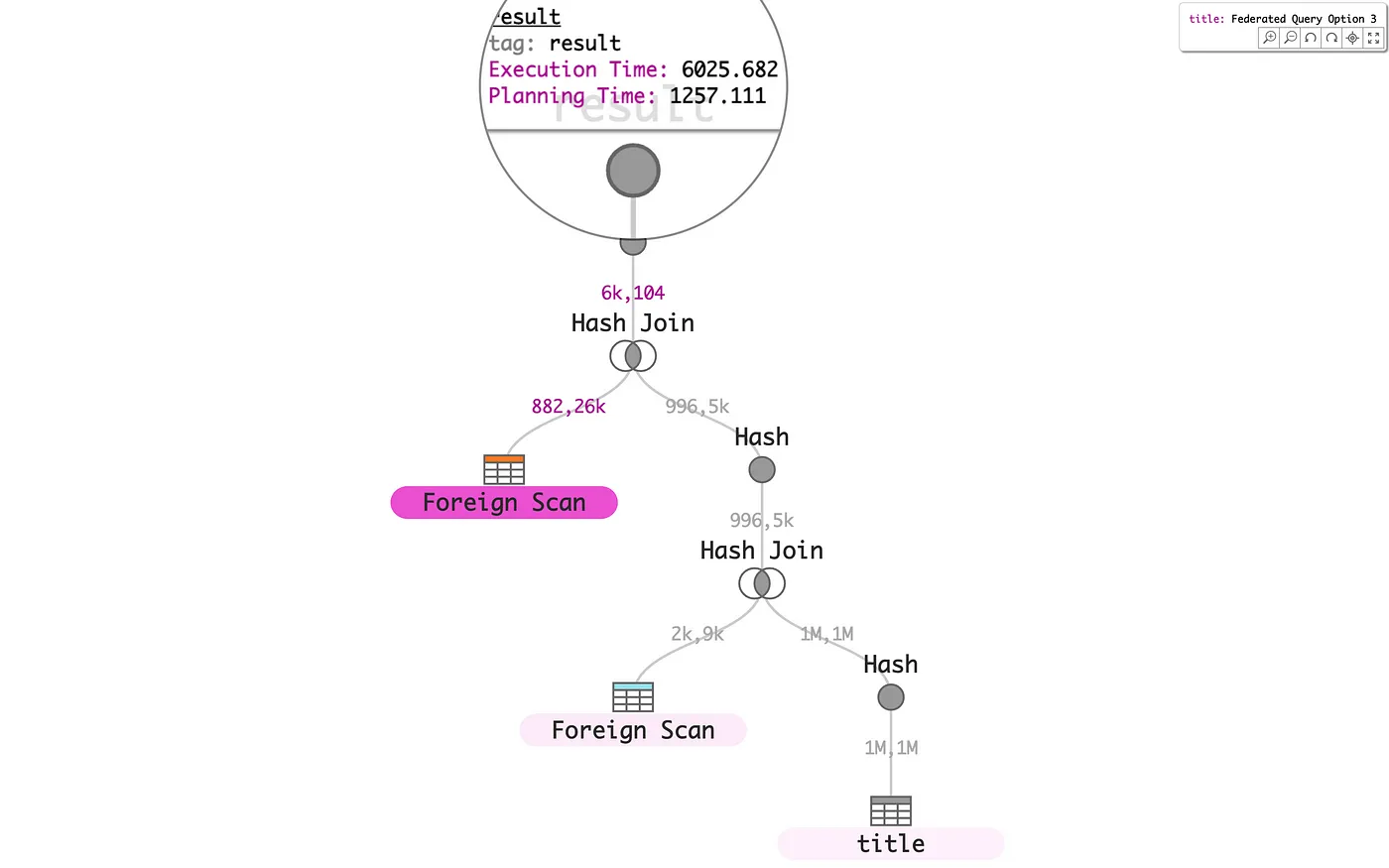
Interactive versions of these alternative query plans are also available on tableau.github.io as Federated Query Option 1, Option 2, and Option 3.
To see and understand queries via interactive visualizations is aligned with Tableau’s mission of “see and understand” for query expressions emitted by Tableau’s user interface and various database systems. Users of Query Graphs (e.g., Tableau developers) gain query insight supporting the development of new query processing features (e.g., new window functions) and query optimizations (e.g., outer join reduction and join elimination), improving query debuggability (e.g., suboptimal filter placement), and clarifying query performance (e.g., identifying bottlenecks).
We plan to continue Query Graphs development: supporting new database systems; visualizing the lineage of query expressions from the user interface to the database system; adding interactive visual features such as node expansion, graph summarization, and graph comparisons; and expanding the notebook interface functionality. We look forward to contributions in these and other areas.
Related Stories

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 April 14, 2026
April 14, 2026
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 April 10, 2026
April 10, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 June 8, 2025
June 8, 2025