Cost Sensitive Classifiers for Better Machine Learning Decision-Making



The basic template for many machine learning (ML) systems is simple: consume data, learn the patterns within it, and use these to predict future events. A fraud detection system may be used to either identify potentially malicious users might freeze an account, or simply mark it for review.
Each application has costs associated with false positives (interpreting a nominal account as malicious), and false negatives (interpreting a malicious account as nominal). But the costs differ wildly by application: incorrectly freezing accounts may be more costly than incorrectly marking an account for review. I want to introduce cost-sensitive classifiers as an alternative design for multi-purpose ML solutions.
Classifying Submission Failures
For Tableau engineers, a submission kicks off several builds across different products and operating systems. Submission failures are difficult problems to address. Our developers at Tableau often don’t know whether they should debug their changelist, or whether something went wrong within the external build system. We’ll call the former failure category My Fault (MF), and the latter Not My Fault (NMF).
We have built a classification model for submission failures, which is still in the early stages, but has achieved an accuracy of 80%. I will use this model to discuss the cost-sensitive classifiers, and will argue that they provide an interesting way to promote separation of concerns, especially when paired with explicit cost-benefit analyses.
Cost Sensitive Classifications
Our team decided to build a probabilistic classifier. Rather than providing a boolean output IsNMF, these classifiers produce a plausibility score ProbNMF. Here is a histogram of our model output.
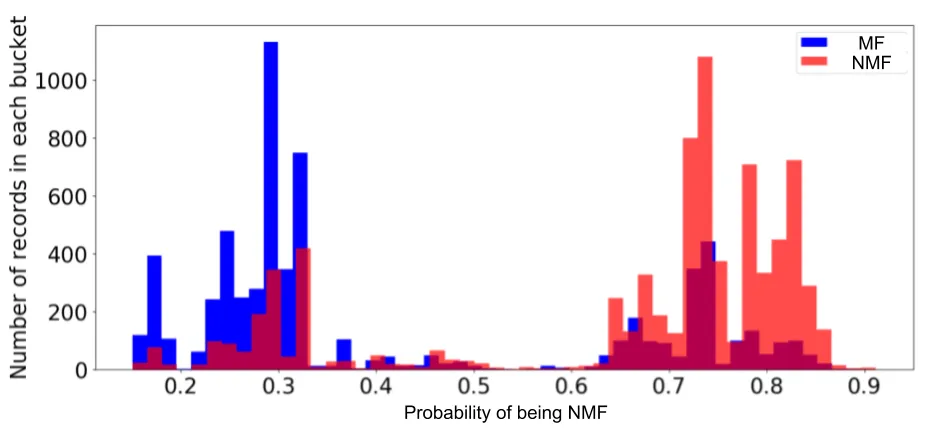
Note that these predictions are often not well-calibrated. If a model tells you a particular submission is 40% likely to be NMF, that does not necessarily mean 40% of those predictions are correct. If you or your customers have reason to prefer calibrated probabilities, there are ways to do this in scikit-learn.
In order to connect these scores with predictions, you need to add thresholding logic. With a 50% threshold, for example, a submission with a score of 30% becomes MF, 70% turns into NMF. But other thresholds beyond 0.5 are possible. In essence, a probabilistic classifier is a family of classifiers: the threshold lets you pick a specific binary classifier from this family.
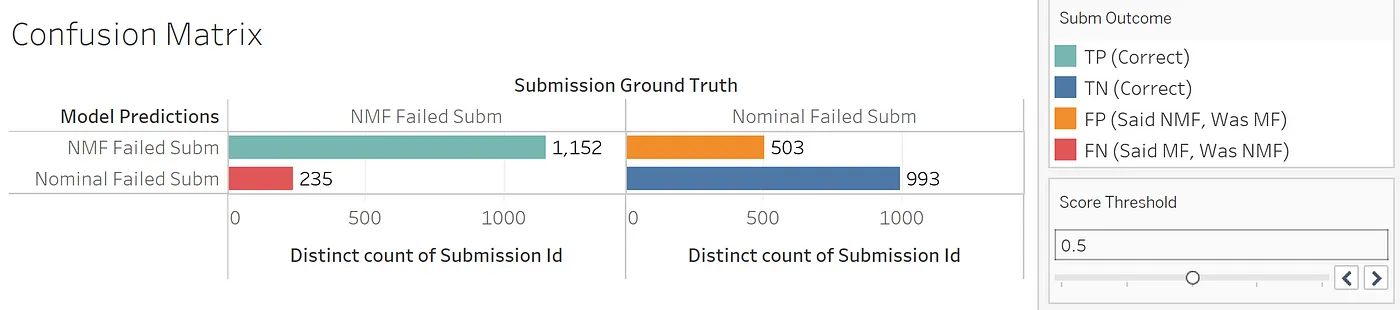
When model predictions are compared to reality, four prediction outcomes are possible:
- True Positive (TP). Model correctly says it’s NMF.
- False Positive (FP). Model erroneously says it’s NMF, but it’s actually MF.
- False Negative (FN). Model erroneously says it’s MF, but it’s actually NMF.
- True Negative (TN). Model correctly says it’s MF.
We can visualize model performance in Tableau with what’s known as a confusion matrix:
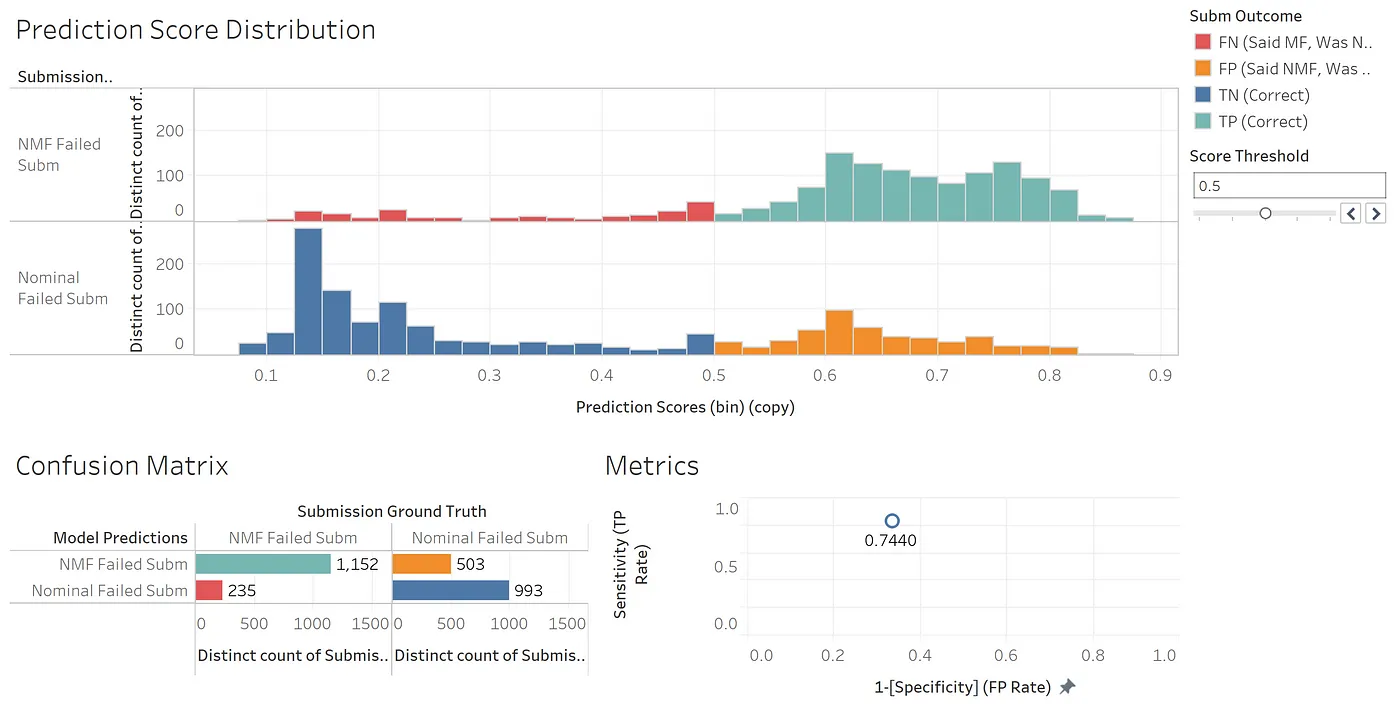
We can also show the model’s probabilistic output before the threshold is applied:
Custom Thresholds
Let’s imagine this classifier will be used to auto-lock branches. If our model reports many consecutive false negatives, the branch may be erroneously locked. If our model erroneously thinks an incoming wave of failures are developer-caused (i.e., my fault), we may fail to lock the branch when we otherwise should. Explicit cost-benefit analyses have shown us that, in this case, FPs (in orange) hurt more than FNs (in red).
Should we raise the threshold to reduce the number of false positives? While the model accuracy may degrade, the value delivered to developers would increase.
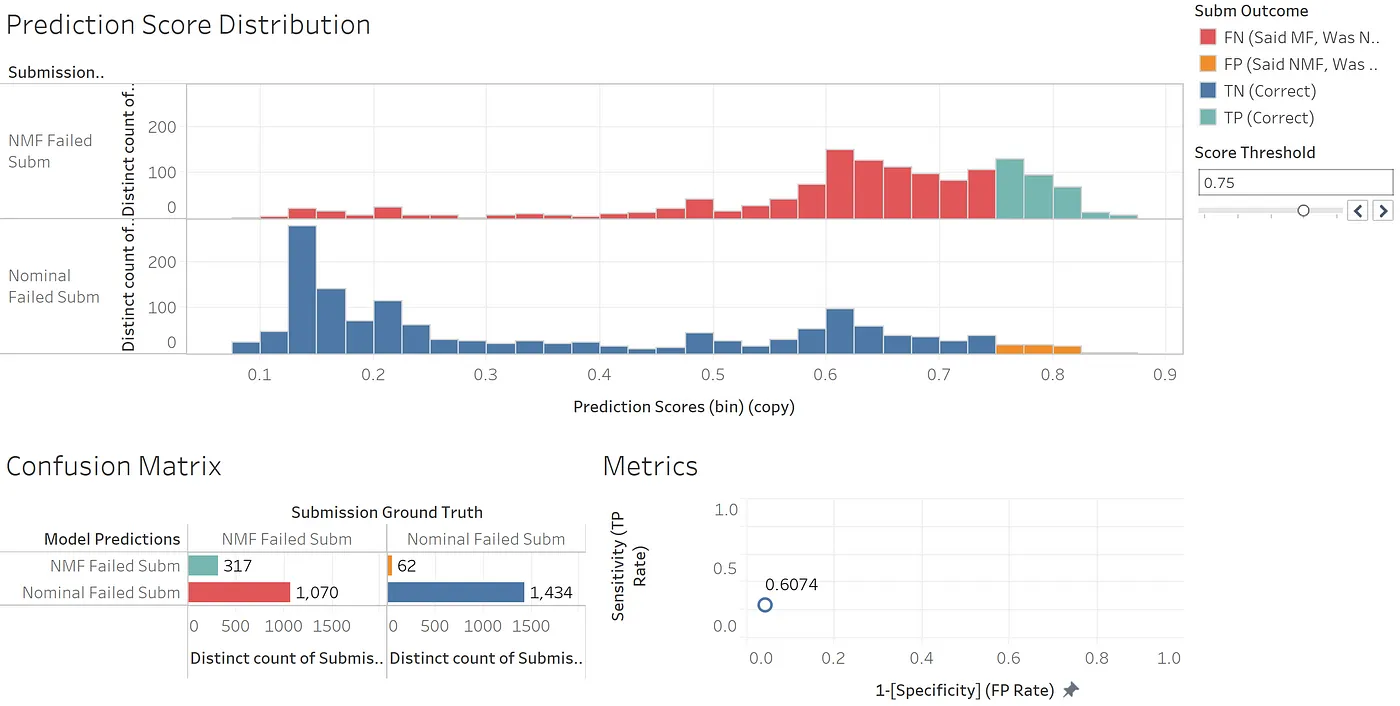
Using the above threshold (0.75), very few false positives occur. You can see this in the bottom-right sheet which shows a very low false positive rate (x-axis).
Next, let’s consider dev notifications, where developers are told when our model believes their submission failure is MF, and thus worthy of investigation. In this case, FN results (erroneous calls to investigate) cost more than FPs (erroneous all-clears). Our cost-benefit analysis suggested a low threshold (0.25) is thus more appropriate:

Classifier Metrics
Of course, we need to boil down these performance data into scalar metrics. Typical metrics are as follows:
- Accuracy: (TP + TN)/(TP+FP+FN+TN)
- Specificity (True Negative Rate): TN/Negatives = TN/(TN+FN)
- Sensitivity (True Positive Rate): TP/Positives = TP/(TP+FP)
For our auto-lock application, we envisioned setting a low threshold to minimize false positives. We would expect this application to have high sensitivity (few FPs), at the expense of high specificity (many FNs).
In the dev notification use case, we wanted to sett a high threshold to reduce false negatives. We would therefore expect this application to have high specificity (few FNs) at the expense of low sensitivity (many FPs).
We can graph these alternative parameterizations on what’s called a Receiver Operating Characteristics (ROC) curve. This allows us to visualize not just a couple thresholds, but in fact it captures model performance for all possible thresholds.
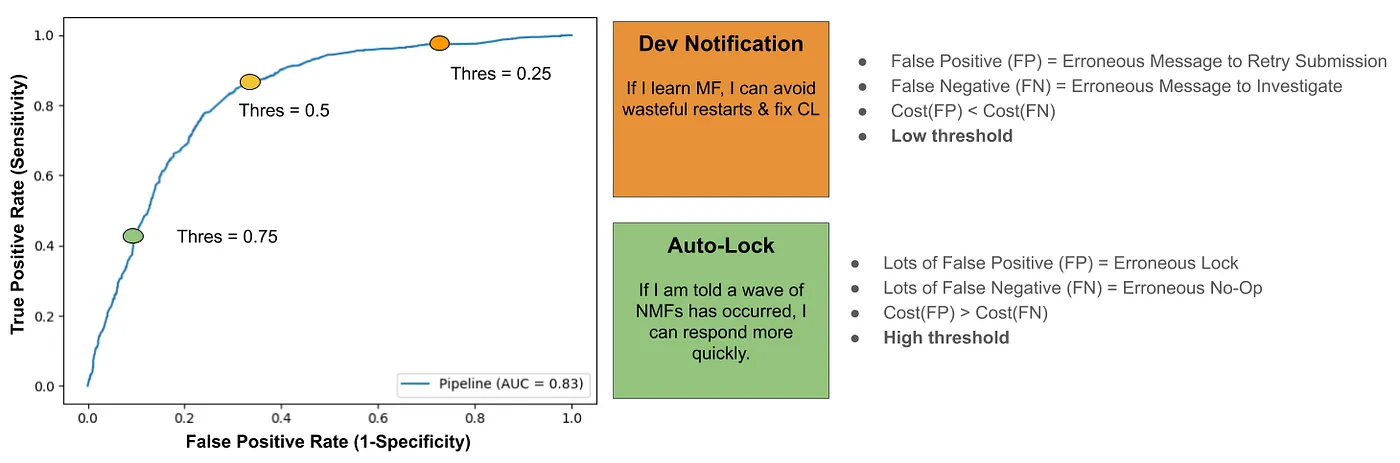
Most engineers I talk to want to know the model’s accuracy. However, accuracy changes with threshold value, and lower accuracy models may often be preferred (c.f. auto-lock vs dev notification). Accuracy is not the right metric to train a probabilistic classifier on, at least for cost structures this unbalanced.
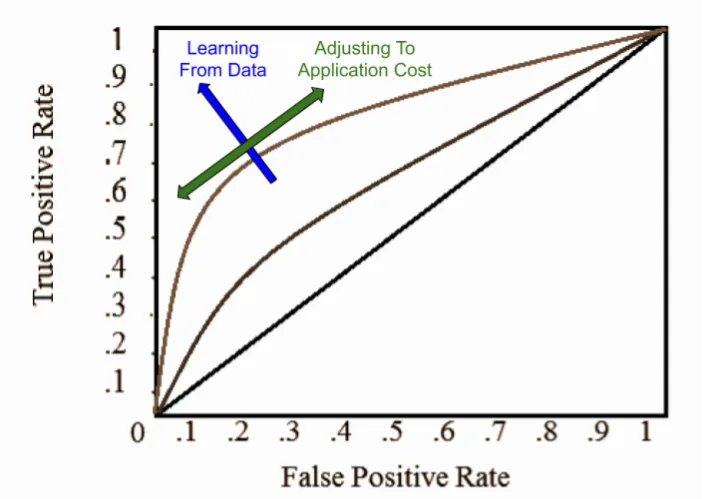
There is a better way to express model performance. What is perfect knowledge? It is 100% true positive rate, and 0% false positive rate: the top-left corner. We want our entire ROC curve to approach this ideal. We either strive to minimize the whitespace above the curve, or maximize the whitespace between us and ignorance (the bottom-right corner). The latter metric is accessible from a calculus-savvy python package: it is the Area Under the Curve (AUC).
Towards Separation of Concerns
This approach cannot be directly ported to all classification contexts. Our example was based on two outcomes (a binary classifier) with roughly equal numbers of MF and NMF events (no class imbalance). As a metric, AUC becomes less helpful for imbalanced data.
If your data is compatible with the above pattern, it does usefully decouple two processes:
First, the client team adjusts its consumption according to application cost. It can use rough heuristics or application-specific cost-benefit analyses to achieve these ends. This allows domain experts to adjust classification thresholds in response to changing business requirements.
Second, learning from data. The ML team optimizes against AUC with various feature engineering measures, and ensures the learning system is robust and highly available.
If the client team receives increasing complaints of erroneous “not your fault, please retry” dev notification messages which waste time, they could reduce the volume of these false positives by simply increase their threshold parameter from e.g., 0.25 to 0.35. Or some innovation dramatically reduces submission latency at no extra cost, they might reduce the threshold, to reduce the number of erroneous investigations (false negatives) in accordance with the new cost ratio.
The ML team can operate independently of these business concerns. They are freed to do more foundational work in the data layer. This may include building or routing new telemetry data. If the data generating process changes (e.g., updates to the submission architecture), they should be able detect and mitigate such events with concept drift monitoring.
Cost sensitive classifiers thus represent a powerful way to promote separation of concerns while maintaining services in a distributed environment.
Related Stories

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 April 14, 2026
April 14, 2026
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 April 10, 2026
April 10, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 June 8, 2025
June 8, 2025