Unleash your data sources with Data Server



Tableau Server has many data governance features to promote exploration, collaboration, and security. You can take advantage of them using Data Server, a powerful, but often underutilized collection of features in Tableau Server. Data Server lets you share data sources, manage extracts, consolidate access, and control security.
Answer these questions to find out how Data Server can save you time and increase productivity:
- Are you struggling to manage and update many large extracts while reducing duplication?
- Do you have many workbooks that use the same data source, and want them to update automatically when the data changes?
- Do you want to provide centralized management of your metadata with standardized definitions for each field? e.g. The ability to author a calculation once and share it with everyone.
- Are you tired of having to deploy and update database drivers on each user’s local machine?
- Do you want to simplify how your users access data stored in your databases, and centralize credentials?
- Are your data sets complex and large? Could you benefit from server hardware running the queries?
If you found yourself replying "yes" to any of these questions, then it’s time to unleash the Data Server.
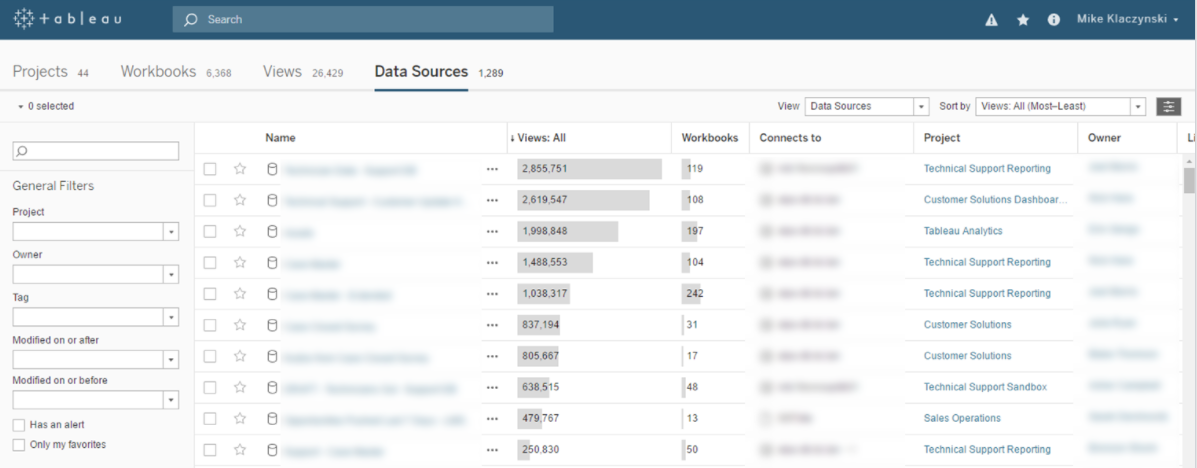
Tableau Server lets you publish data sources so they can be shared with other users and their workbooks. This allows you to reuse data extracts, consolidate database connections, and share calculations and field metadata. Any changes you make to the shared data source—calculated fields, parameters, aliases, or definitions—can be saved and are instantly accessible by others. This lets everyday users build on the work of data stewards and database administrators (DBAs), while ensuring that certified data sources are secure, centrally managed, and standardized.
Publishing is as simple as right-clicking on your data source, selecting "Publish to Server" in Tableau Desktop, entering credentials, and specifying user permissions. Connecting to a shared data source is just like connecting to any other database: Choose "Tableau Server" from the connection list, authenticate, and select the published data source. Data connections can be administered, modified, or deleted by accessing “Data Sources” in Tableau Server.
Create a single source of truth with a data repository
Tableau Server acts as a centralized repository for data and data connections, reducing the proliferation of duplicate data sources and helping clarify a single source of truth. New and existing workbooks that connect to Data Server automatically update when the original data sources update.
Scheduling automatic refreshes of extracts allows everyone to have the most up-to-date data sets, and saves space by eliminating the need for duplicate extracts. By having users connect to a single shared extract, you reduce the number of queries made to the original database, resulting in fewer API calls and lower service costs—particularly when connecting to services that charge for API access, like Salesforce.
Run queries on server hardware
Queries against large data extracts are run directly by the server’s hardware, resulting in shorter processing times and eliminating the need to transfer the extract to each user’s computer. Imagine million row extracts, several gigabytes in size, that no longer need to be copied to each local machine. Instead, all processing is completed by the server's dedicated multi-core hardware. In addition, shared caching significantly speeds up query execution as the results are cached locally and instantly accessible by future users.
Credentials for live database connections can be embedded into published data sources, allowing Data Server to act as a proxy without requiring each user to authenticate to the original database.
Consolidate database drivers
Install a single set of database drivers on the server to handle all database connections for all users, eliminating the need for each user to install and update drivers on their local machines. This saves time for organizations with large desktop deployments.
Preserve valuable metadata
Published data sources are more than just connections to databases. They contain metadata and serve as a curated semantic layer for everyone. Hide unimportant fields, organize fields into folders, create calculations, aggregations, parameters, sets, groups, predefined joins between tables—all serving as a single shared semantic layer for all users and their workbooks.
This encourages self-service, as analysts reuse trusted models while enhancing them with their own calculations and descriptions. The published data source shields users from physical layer churn: If any changes are made to the data's underlying structure, the DBA can make those modifications and they will transparently propagate to all workbooks using that data source.
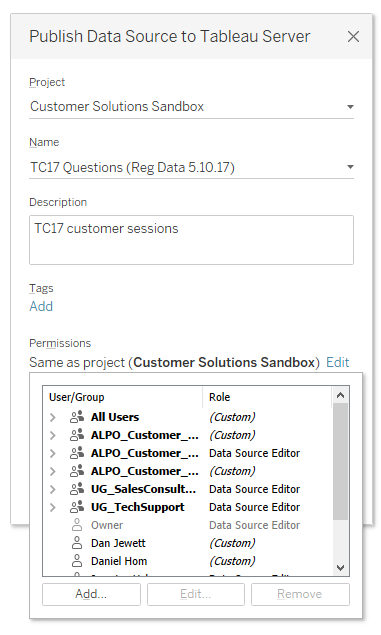
Ensure data integrity and set permissions
In addition to maintaining the metadata for a data source, admins can create restrictions based on permissions and user level filters to better control each user's visibility of portions of the data. This means storing a single data connection or extract without the need to create unique data sets for each user.
Permissions for editing data source metadata can be limited to a few named users responsible for data integrity and administration. This way, business users can trust the insights they are deriving from the data without having to understand the underlying database structure, proper field definitions, or questioning data integrity.
Learn more
Explore how Data Server can help automate and standardize your organization's data sources by acting as a fast and secure proxy and extract repository with our Data Server training video.
To dive deeper, check out these topics in the Tableau Help:
Related Stories
How EMD Serono is improving patient care with personalized, AI-powered insights from Tableau
 September 30, 2024
September 30, 2024

Embedded Analytics: Should you build or buy?
 June 7, 2022
June 7, 2022
Data fabric’s value to the enterprise
 May 11, 2022
May 11, 2022