Reflecting on a decade of data science and the future of visualization tools




Editor's note: This article originally appeared in the Tableau Engineering Blog.
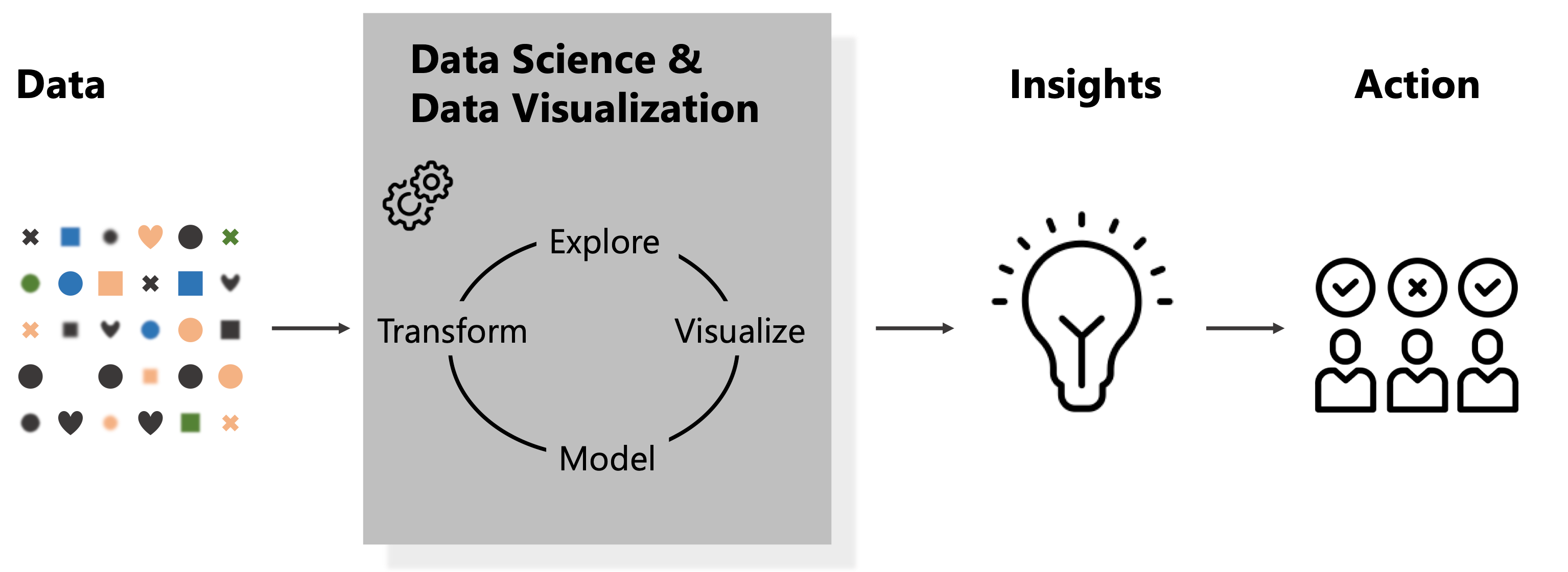
Data science has exploded over the past decade, changing the way that we conduct business and prepare the next generation of young people for the jobs of the future. But this rapid growth was coupled with a still evolving understanding of data science work, which has led to a lot of ambiguity toward how we can use data science to derive actionable insights from our piles of data. Having had my own career shaped by the growth of data science, I wanted to dig into the questions of what data science is, what data science work is, and who data scientists are. I looked across the research literature to pull on threads of various studies and analyses on data science and data scientists to weave together answers to these questions. I presented these results in a research publication entitled “Passing the Data Baton: A Retrospective Analysis on Data Science Work and Workers”.
Part of the motivation for this research was to serve as a foundation for research and development, so that I may identify areas where visual analytics tools might address an unmet need. However, another motivation was a personal reflection on a field that did not yet exist a little over a decade ago when I first began my advanced studies in computer science. In this blog post, I summarize several of the key takeaways from this research paper and share my thoughts on how its findings can help us build the next generation of data visualization tools for data science.
What is data science?
It turns out data science is different things to different people. To some individuals, data science is nothing new and is just the practical application of statistical techniques that have existed for a long time. To others, this view is too narrow as data science requires not only knowledge of statistical methods but also computation techniques to make the application of these methods practical. For example, it’s not enough that a data scientist understands linear regression, they also need to know how to apply it at scale to massive amounts of data—something that is not part of a traditional statistics education. Still, even those who would argue that data science is more than applied statistics might still hesitate to say that it is something new. The practice of gathering and analyzing data, even large amounts of data, has long been a part of scientific research, for example in biology or physics; many feel that data science is just an extension of what has already been happening in empirical science.

Three primary perspectives on what data science is.
But there is also a third perspective here, which is that data science really is something new and different both from statistics and also the approaches that scientists used when studying atoms and genes. Bringing together statistics and computer science with the necessary subject matter expertise has resulted in new challenges that are uniquely addressed by data science and that are tackled by data scientists. Moreover, the work carried out by data scientists is distinct from other types of data analysis, because it requires a wider breadth of multidisciplinary skills. Our research, and others’, takes this perspective that data science really is something new and different and from this we created a working definition that serves as the foundation of our work:
“Data science is a multidisciplinary field that aims to learn new insights from real-world data through the structured application of primarily statistical and computational techniques.”
This definition is important because it helps us to understand the challenges and unmet needs of data science workers, which primarily stem from the challenges of working with real, as opposed to simulated, data and the challenges that accompany the application of statistical and computation methods to these data at scale.
What is data science work?
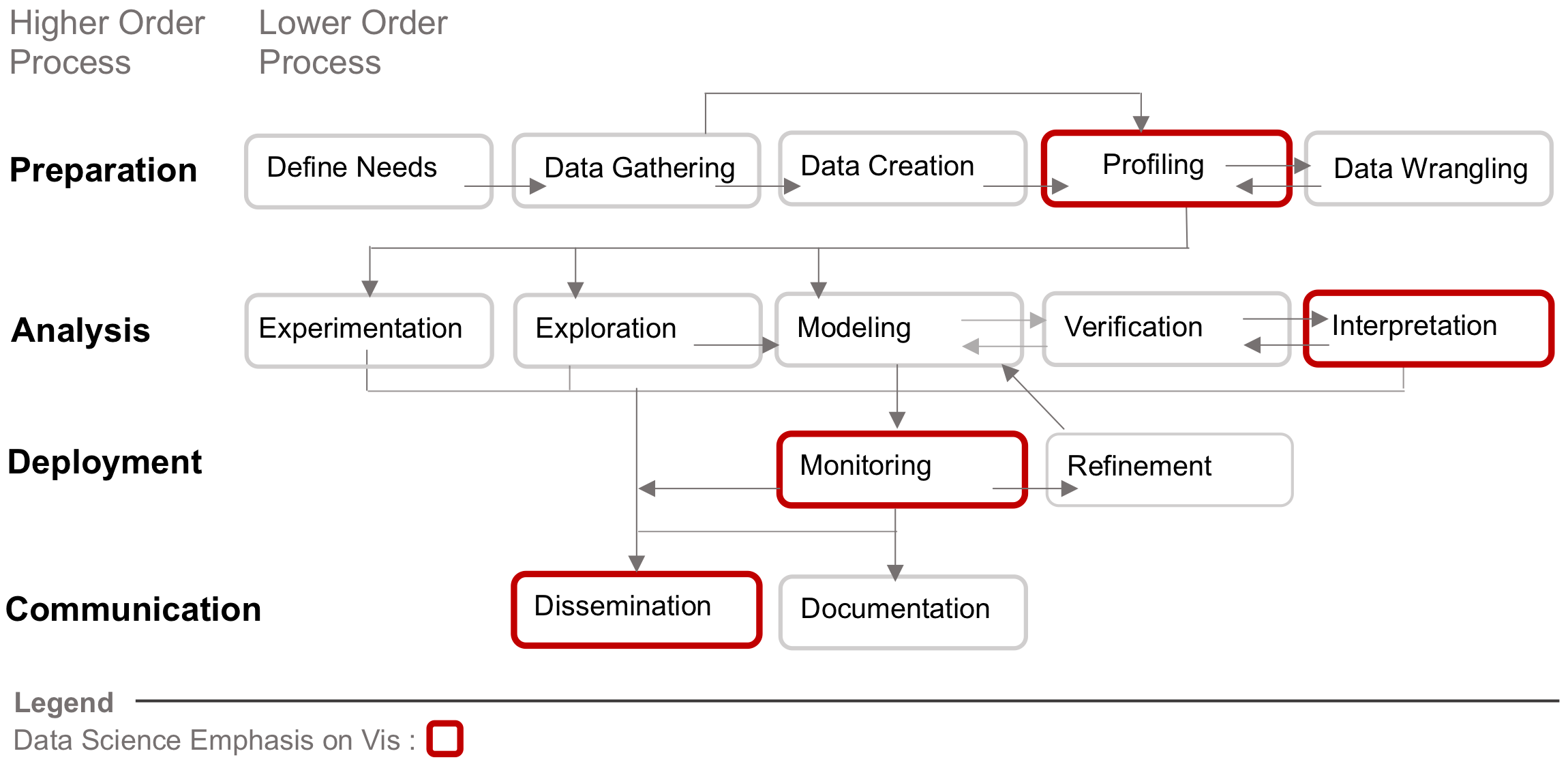 Distilling data science work into four higher order (Preparation, Analysis, Deployment, and Communication) and 14 lower order processes. The processes outlined in red are those where data visualization is predominately used, but this doesn’t preclude its use in other aspects of data science work.
Distilling data science work into four higher order (Preparation, Analysis, Deployment, and Communication) and 14 lower order processes. The processes outlined in red are those where data visualization is predominately used, but this doesn’t preclude its use in other aspects of data science work.Importantly, a working definition of data science narrows the scope of research. Instead of considering all possible types of data analysis that one may wish to conduct, we look closely at the types of analyses data scientists carry out. This distinction is important as the specific steps that, say, an experimental physicist takes to analyze data are different, even though they share commonalities, than the analytic steps a data scientist may take. Which leads to an important follow on: what exactly is data science work?
There have been several industry standards for breaking down data science work. The first was the KDD (or Knowledge in Data Discovery) method, that over time was modified and expanded upon by others. From these derivations, as well as studies that interview data scientists, we created a framework that has four higher order processes (preparation, analysis, deployment, and communication) and 14 lower order processes. Using the red stroke outline we also highlighted the specific areas where data visualization already plays a prominent role in data science work. In our research article we provide detailed definitions and examples of these processes.
Who are data science workers?
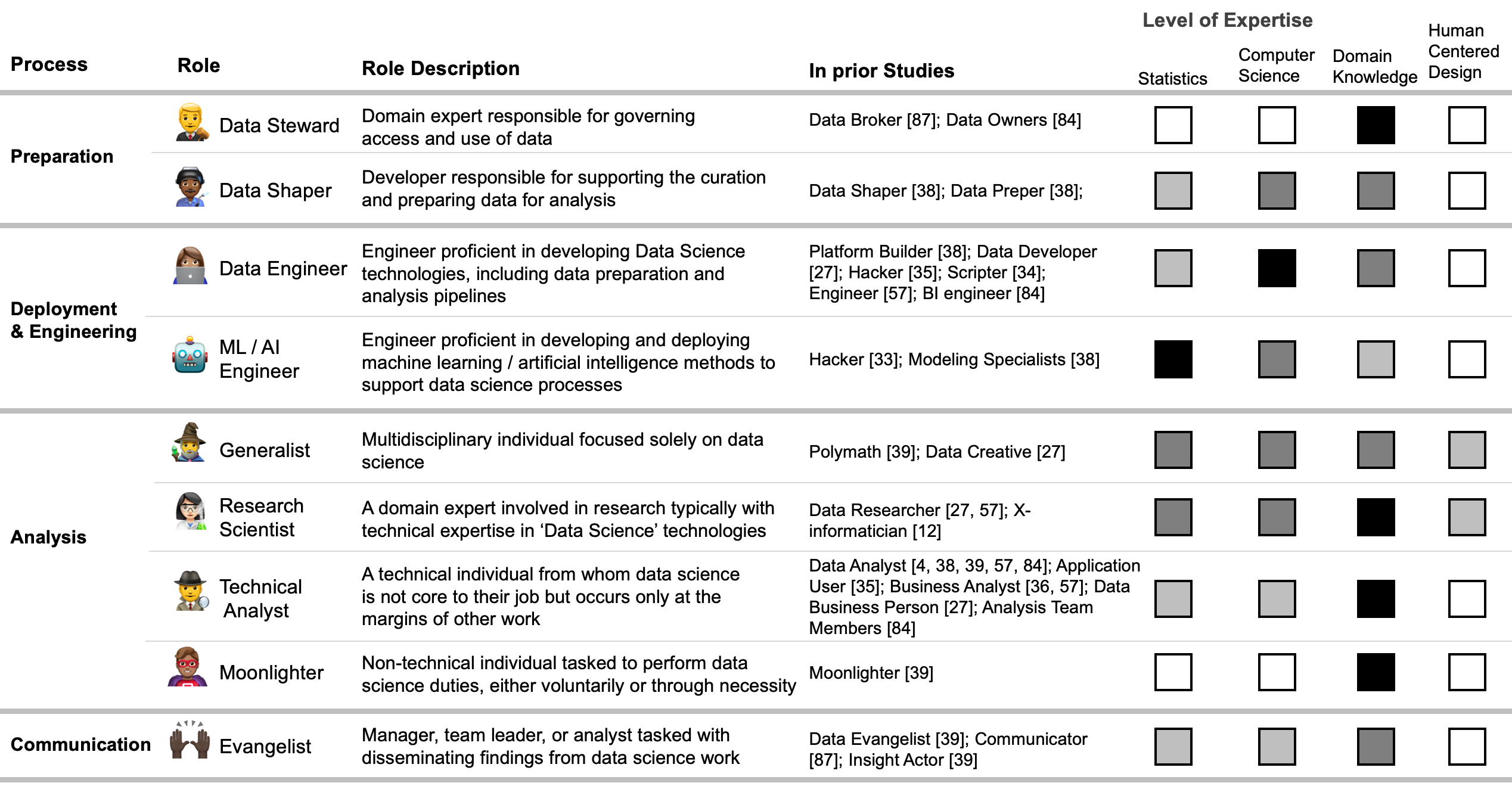
Nine Data Science roles that we found across twelve in depth studies with Data Scientists
Over they years, I have heard many different takes of what a data scientist is. One take I enjoy is that a data scientist is someone who is ‘better at software engineering than a statistician, and better statistics than a software engineer”. A more recent tongue in cheek take I’ve heard is that a data scientist is a “statistician on the west coast”.
However, as we dug into the existing studies on data scientists something that we did not expect to find, but that emerged as consistent and important, was how diverse ‘data scientists’ were and how their roles changed in relation to specific data science processes. You may have noticed the rise of the data engineer, for example, as a distinct but still adjacent data science role. As data science work grew in complexity, data scientists became less generalized and more specialized, often engaged in specific aspects of data science work. Interviews conducted by Harris et al. as early as 2012 already identified this trend, which has only accelerated over time. Astutely, they observed that this diversity among the data science role leads to “miscommunication between data scientists and those who would seek their help”.
We built upon the results of Harris work by examining twelve studies totaling thousands of individuals that identified as data scientists. From our meta analysis of these studies, we were able to identify 9 distinct data roles. These individuals had different skill sets and backgrounds, which we illustrated along an axis of statistics, computer science, and domain expertise. We also included human centered design in our characterization of data science skills, as considering the impact of data products, like a facial recognition application, is of growing importance. We want to emphasize that these roles are not absolute categories, there is fluidity in their boundaries as well as with the technical skill strength of these individuals that occupy these roles. Instead, these categories of roles are intended to serve as guideposts to help researchers, and others, get a lower granularity sense of who they’re talking to and what their background may be.
How does this change the way we build visualization and data analysis tools?
Of course, the most important consideration is how our definition of data science and our framework of Data Science work and workers can help us build better data visualization tools. First and foremost, it helps by making the diversity of data science work and workers explicit and grounded in evidence. Already we have used this framework to create crisper criteria for breaking down Tableau customer experiences in data science. We can pinpoint with greater precision exactly what they are trying to do and can ask more probing questions about those processes. Knowing that the role ‘data scientist’ itself included a great deal of diversity, we can better identify who is carrying out the work by classifying individuals we’re talking to into our nine data science roles. Such classification makes it easier to understand the tasks our visualization systems need to support and at what level. For example, a technical analyst and ML/AI engineer, which are two data science roles we characterized, can both be engaged in a common task of model building, but have drastically different needs; if we ignore those differences, we risk building the wrong tool for both roles.
But perhaps most importantly to me, this framework also helps me think about what’s missing in the current ecosystem of visual analytics tools. One concerning conclusion I drew was the narrow focus of existing tools toward visualizing machine learning models, and the lack of tools that support other critical aspects of data science work, such as data preparation, deployment, or communication. Not only does this lack of tooling add overhead to data science work, it also makes it more difficult for data scientists, in whatever role they hold, to have their work impact organizational decision making and practices. This research on data science work and workers has helped me surface these challenges and define opportunities for building better tools that help people see and understand their data.
Anamaria Crisan, Brittany Fiore-Gartland, and Melanie Tory (2020), Passing the Data Baton: A Retrospective Analysis on Data Science Work and Workers
Related Stories
VizQL Data Service from Tableau: Use Your Data, Your Way
 August 8, 2024
August 8, 2024

When and How to Use Multi-fact Relationships in Tableau
 August 1, 2024
August 1, 2024

Top data books of 2021
 December 12, 2021
December 12, 2021