Machine learning, natural language meet to understand intent




This article was originally posted on InformationWeek.
Machine learning and natural language processing promise to better translate human curiosity into pertinent answers. If true, these smart capabilities will broaden the use of analytics and reach people who are less comfortable dealing with data. It will all start with helping machines learn to interpret human intent. The key is semantics.
Sometimes intent is simple and explicit, like asking Siri or Alexa if a flight is delayed. This question has clear intention and a simple response—returning the flight status answers the question. Such simplicity is seldom the case when it comes to data analysis. Questions are usually more nuanced, making it hard to correctly assume what the user is really looking for. Natural language is even more tricky where ambiguous terms are common.
It’s also difficult for a machine to understand our intent within a limited context. The machine has the data itself but doesn’t grasp the bigger picture in the same way a person with domain expertise can. Asking “How are my sales doing in the Northeast?” is a lot more ambiguous than the flight status example above.
Ambiguity isn’t a new challenge in data analysis. Different groups within an organization may have different definitions or calculations for the same words: for example, the term “profitability”. Some organizations use central dictionaries (also called data catalogs) to reduce ambiguity and create consistency across the organization. These tools can help provide users with the context they need to understand more deeply.
How semantics can help
Semantics is essentially the search for meaning in language. The practice of semantic governance involves the enrichment of data with metadata that describes aspects like classifications, relationships, synonyms, and external references. This enrichment helps people ask questions of data without worrying about the underlying structure of the data.
Earlier generations of natural language technologies began mapping keywords to column headers, helping users search their data without the need to understand how it was categorized. But this has its limitations. Because it relies on a limited index of synonyms that can still carry multiple meanings, intent can easily be lost. A query for “city hardware store” may search a column of cities looking for one named “Hardware Store” when the user was looking for hardware store locations within a city.
Semantic governance and machine learning will enable more powerful synonym mapping and contextual understanding by extending the associations the system can make. For example, when asked to “show me the cheapest apartments,” the system can connect “cheapest” to a column labeled “price” or “rate” and even sort values from low to high to meet the user’s intent. Where semantics are more ambiguous, or lingo is specific to organizations or industries, machines must learn intent over time.
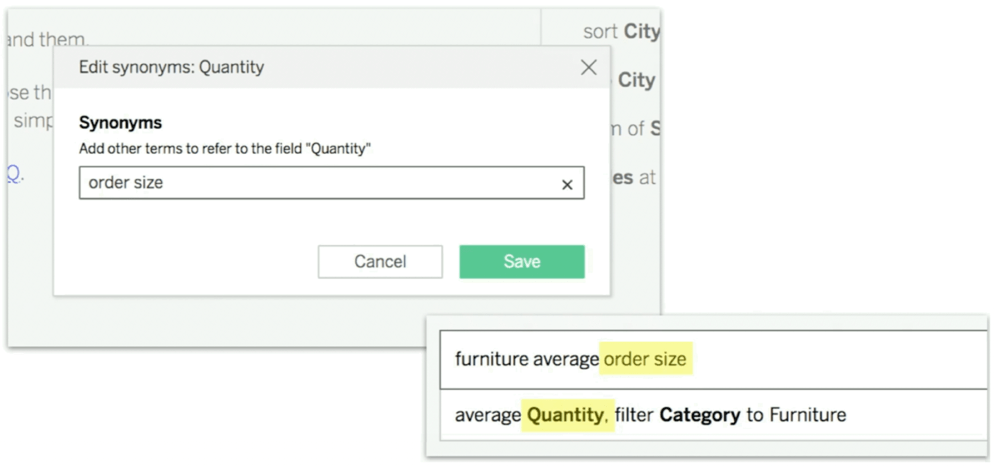
With synonyms, a user can ask about "order size" and the system knows to query the field labeled "Quantity."
Why we should embrace ambiguity
When using natural language for data analysis, ambiguity serves as an excellent way for machines to learn about user intentions. A user could ask the system to show “big earthquakes”, and it may return results according to magnitude. While that’s a reasonable interpretation, perhaps the user really wanted to see the data in terms of the cost of damage. If the system provides a mechanism for feedback—"You asked for X, but did you mean Y?”—the user can correct and guide the system. Equally important is the ability for the person to fine-tune the ask, whether through clarification or follow-up.
Through monitored usage behavior and user feedback, machines will learn people’s preferences. An analytics platform can learn colloquial language that carries nuances specific to an organization or even to a person. The definition of “top customer” can vary within an organization: One team might place greater weight on customer lifetime value, while another might look more closely at profitability. Here, the meaning is more subjective than “cheapest apartments.” This type of machine learning helps the system better anticipate needs over time.
With an understanding of user and organizational behavior, and a view of the data, systems can more intelligently deviate from what’s most popular or predictable. Maybe there’s a different data source or piece of published content that’s used less often that would lead to new and interesting insights. While it’s hard to engineer a “happy accident” in an algorithm, this idea of assisted exploration holds a lot of promise, and another way we may be able to embrace ambiguity. Rather than continuously reinforce the same paths, both the user and the machine may benefit from taking a chance.
For greater impact, start small
With bold new ideas, the best way forward is to start with a scoped test and not seek to boil the ocean with the perfect system. Truly understanding people’s intent and helping them better answer questions related to their data is still relatively nascent. It’s challenging to get a system to understand deeply nuanced intent across a broad set of data. Start with a very specific scope, like a certain department or use case. With a narrower set of known tokens and semantics, the system can navigate context and learn the user’s intent much more easily.
As the platform and the human become more familiar with each other, and machines learn more about usage behavior, the context can grow and become more generalized. With a strong foundation of semantic governance, machine learning and natural language will bring powerful, accessible analytics and faster insights to more users.
Check out Tableau's natural language interface, Ask Data—part of our 2019.1 release.
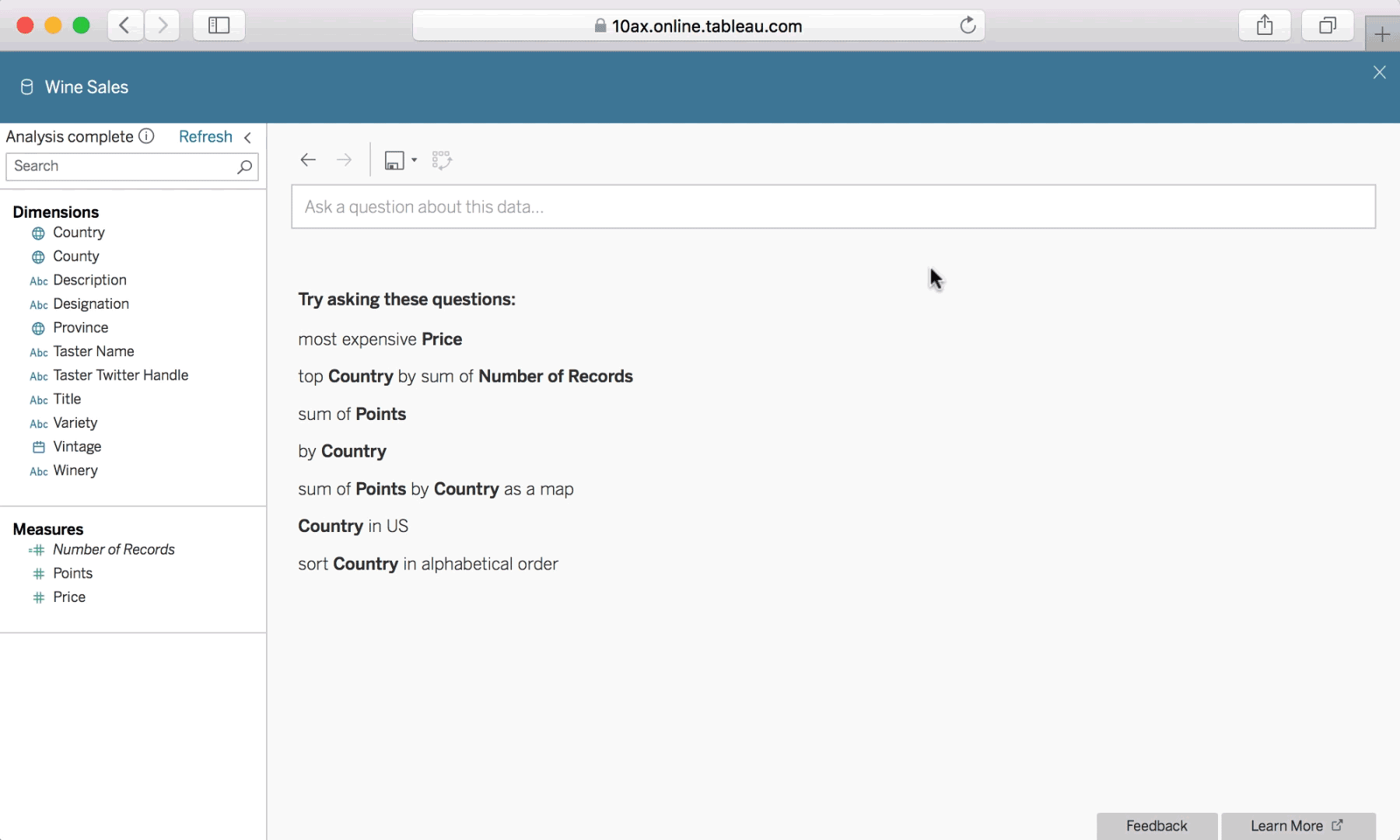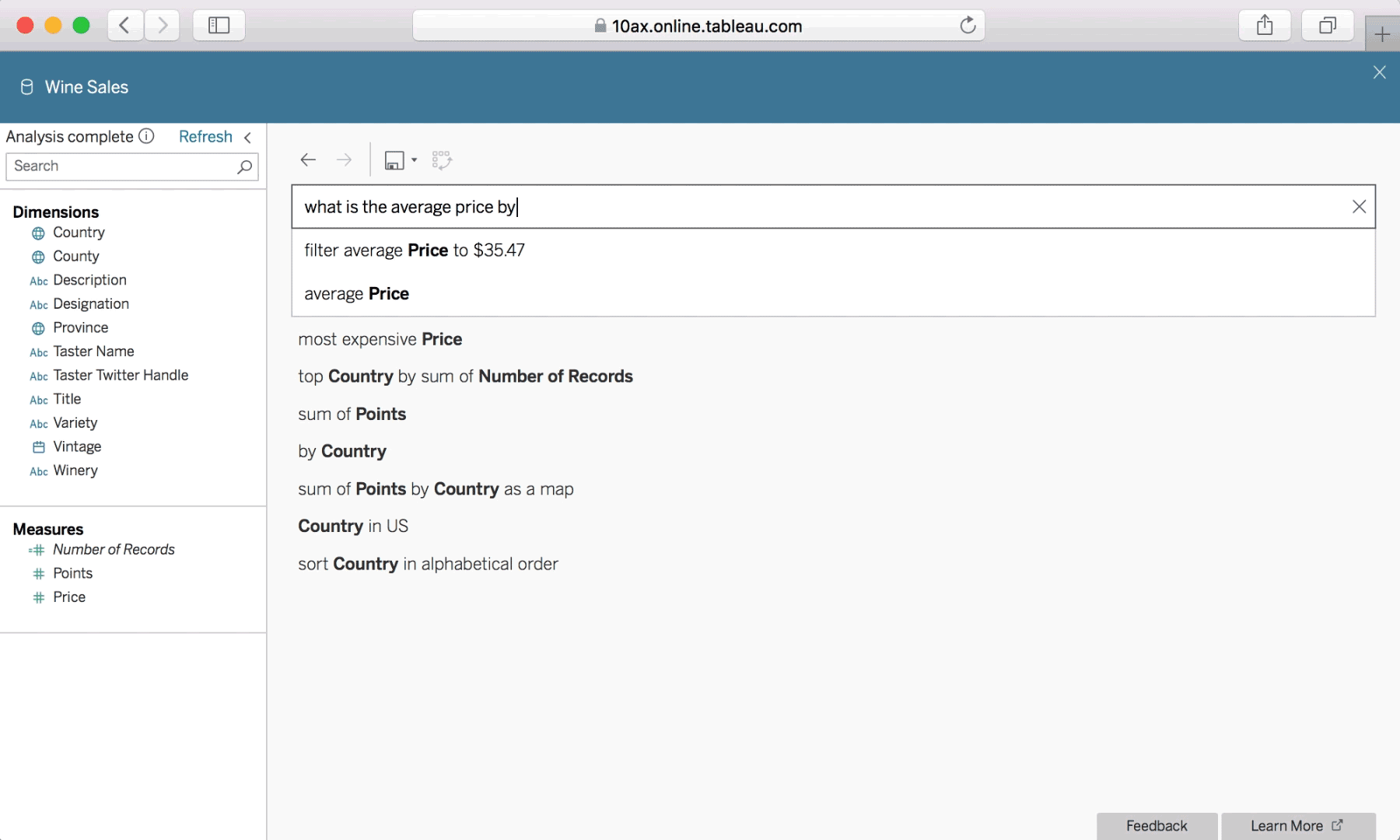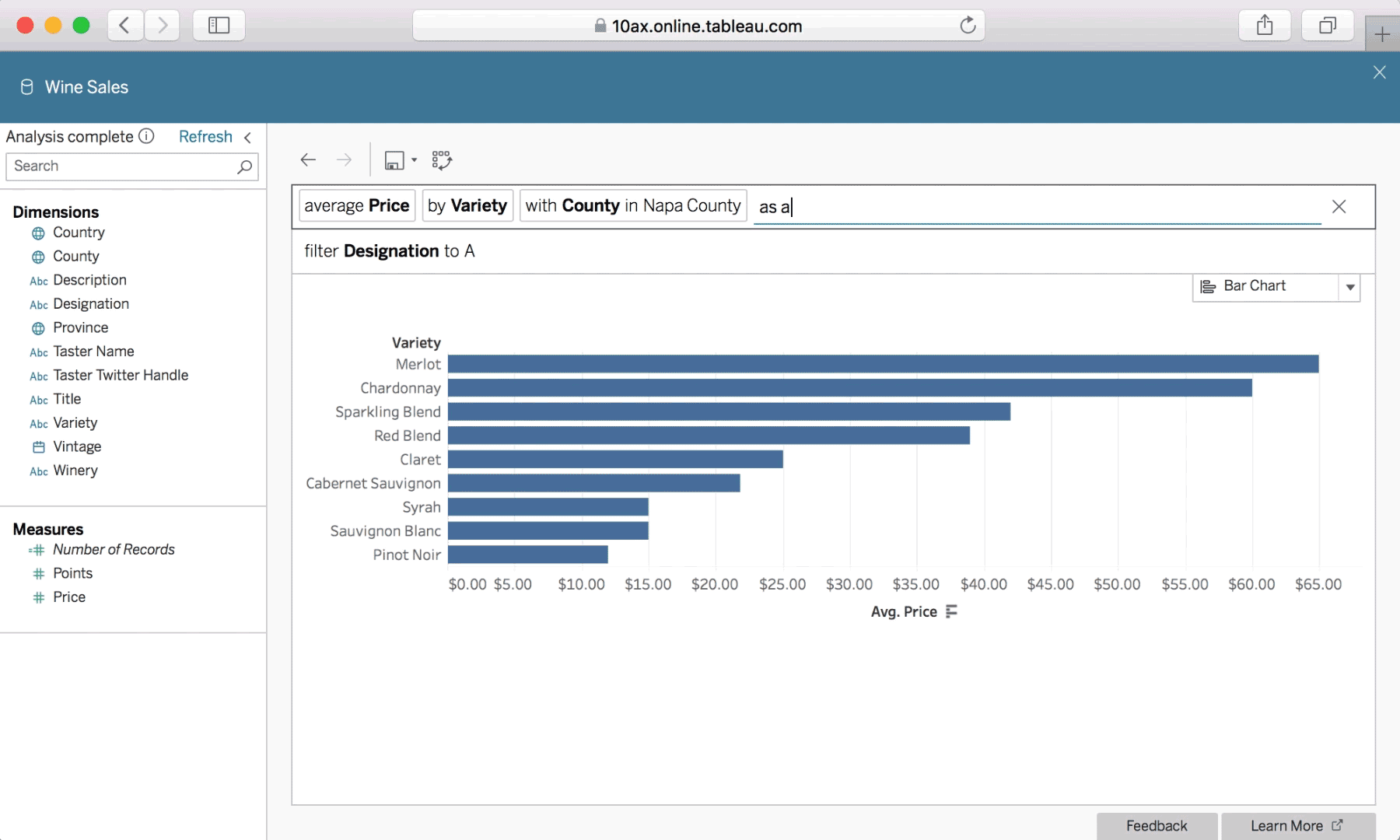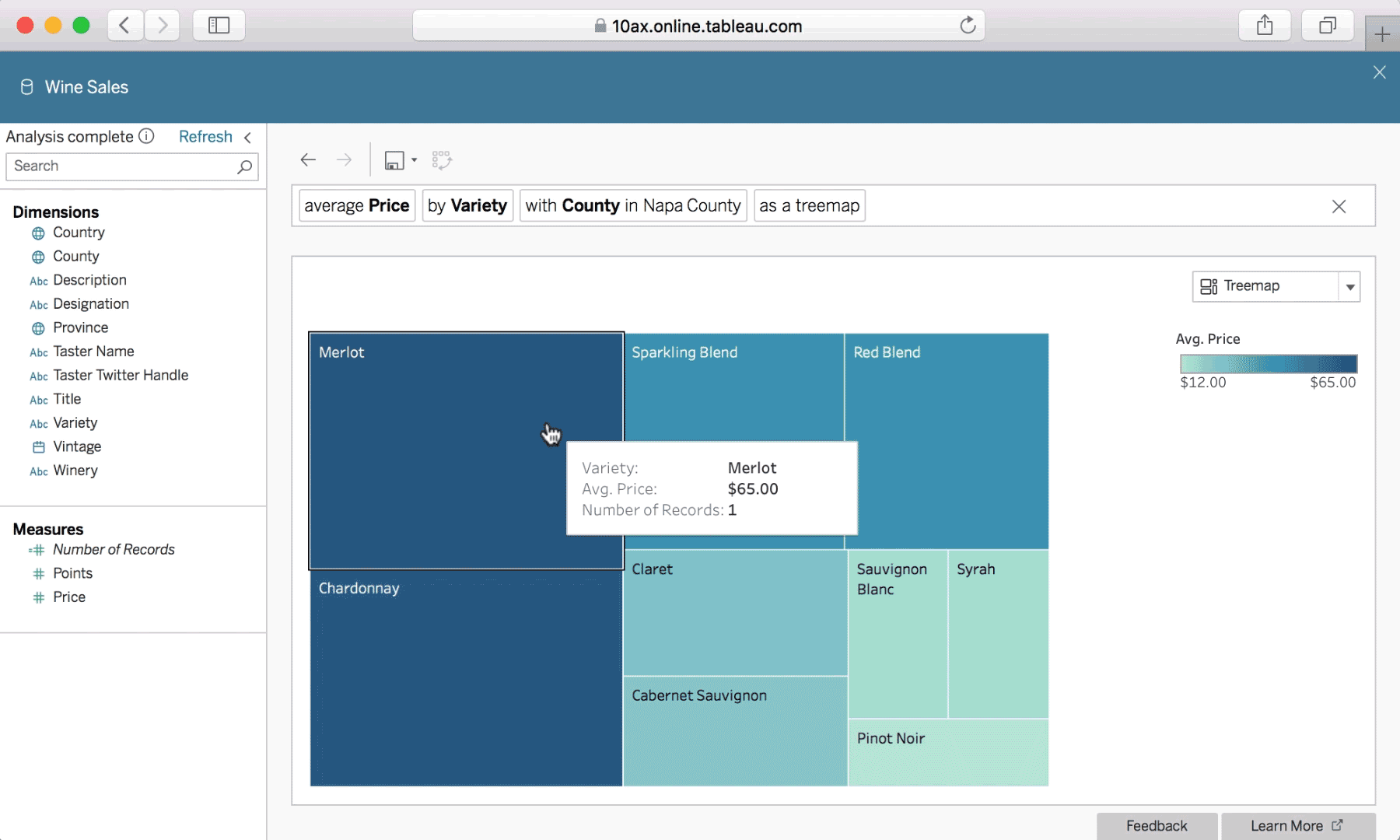
With Ask Data, interactions using natural language are simple and conversational.
Related Stories
How EMD Serono is improving patient care with personalized, AI-powered insights from Tableau
 September 30, 2024
September 30, 2024

Embedded Analytics: Should you build or buy?
 June 7, 2022
June 7, 2022
Data fabric’s value to the enterprise
 May 11, 2022
May 11, 2022