Understanding and adjusting data sampling in Tableau Prep



Tableau Prep helps everyone quickly and confidently combine, shape, and clean their data for analysis. Learn more about Tableau Prep or try it for free.
With Tableau Prep, you can quickly view your data and directly interact with it to filter, combine, and clean—regardless of its size. To make this possible, Tableau Prep extracts data from the data source before you perform any cleaning operations so you can see the immediate impact of your changes.
When connecting to a large data set, Tableau Prep may sample by default, bringing a subset of the data into the flow for you to work on. This makes the flow more efficient compared to profiling all the data and applying changes to larger data volume as you’re working. When you run the flow and generate an output, Tableau Prep will process all the records in your data set.
Let’s take a closer look at how sampling works in Tableau Prep and review how you can take advantage of this functionality when working with large data sets.
Data sampling defaults
Tableau Prep quickly determines if a sample is necessary (and the default number of rows to bring into the sample) based on the number and type of fields present in the data. When a step is added to the flow, you can see the indication that the data is sampled along with the number of rows included in the sample.
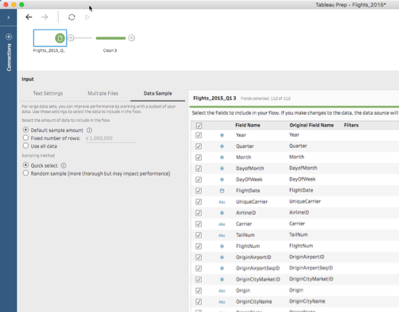
Input step for text file
Clean step showing sampled number of rows
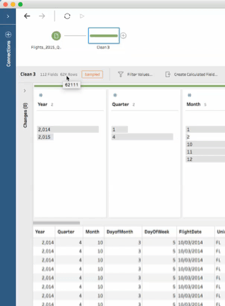
In most cases, data over one million rows will likely be sampled; the default sample amount is based on the number of fields, and the data types of the fields, not number of records. Data sets with more fields will result in a sample with fewer records (rows) than data sets with fewer fields. This means if you have 300 fields, you'll get fewer rows in your sample than if you had 5 fields. Data type is also a factor. Fields with a string data type are usually larger than a numerical data type. Text-heavy data sets will therefore return a smaller number of rows when sampled than data sets that are predominantly numerical.
Although Tableau Prep has helpful defaults for sampling, you may find that you need to adjust the sample, for reasons like:
- You need a more representative sample (i.e. the default settings only pulled data from 2005 when the data set covers 2005-2018). This is common when you have data that is ordered by date, or if you are using a wildcard union.
- You want to generate an even smaller sample (you know the data well and want to streamline the prep experience as much as possible).
- You want to generate a larger sample or use all of the data (there may be too many irregularities to clean the data effectively with a small sample).
Remove unwanted data before sampling
Apply filters at the Input step
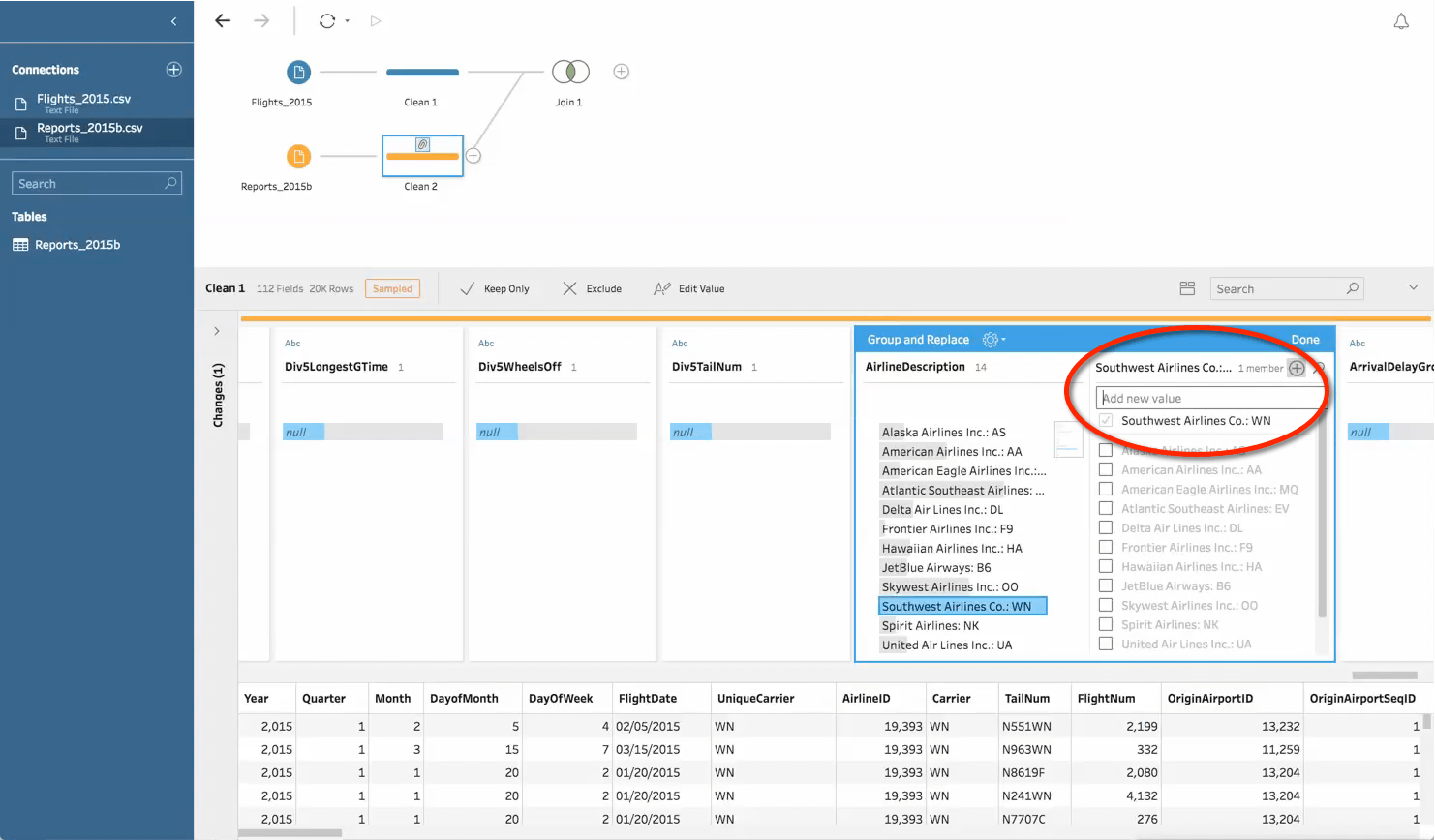
If you are filtering data to limit the values in a certain field, applying the filter in the Input step will improve performance and help you get more out of your sample. In the example below, I notice that my file has unwanted records from the year 2014. If I filter these records from the cleaning step, 100K rows will be removed after the data is sampled, leaving me with only 50K records from 2015. But if I filter the data at the Input step, the filter will be applied first, and I will get 150k records coming from 2015 into my sample.
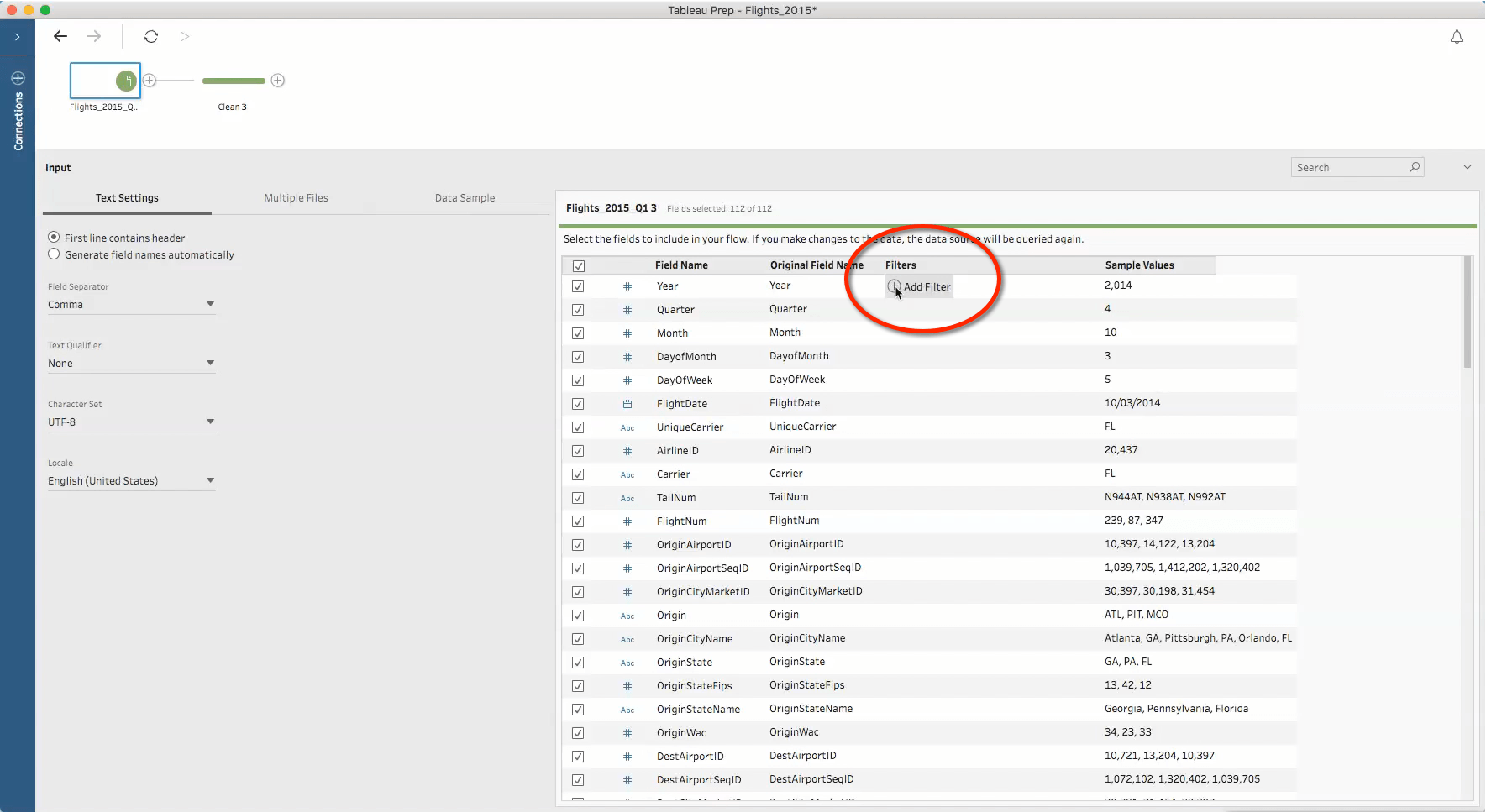
Remove unwanted fields
If I bring in flight data (used in the screenshots above), there are several fields that are mostly nulls, which I know I’m not going to use in my analysis. By de-selecting the fields in the Input step, the data is never loaded into Tableau Prep, which improves performance and allows for a larger sample size.
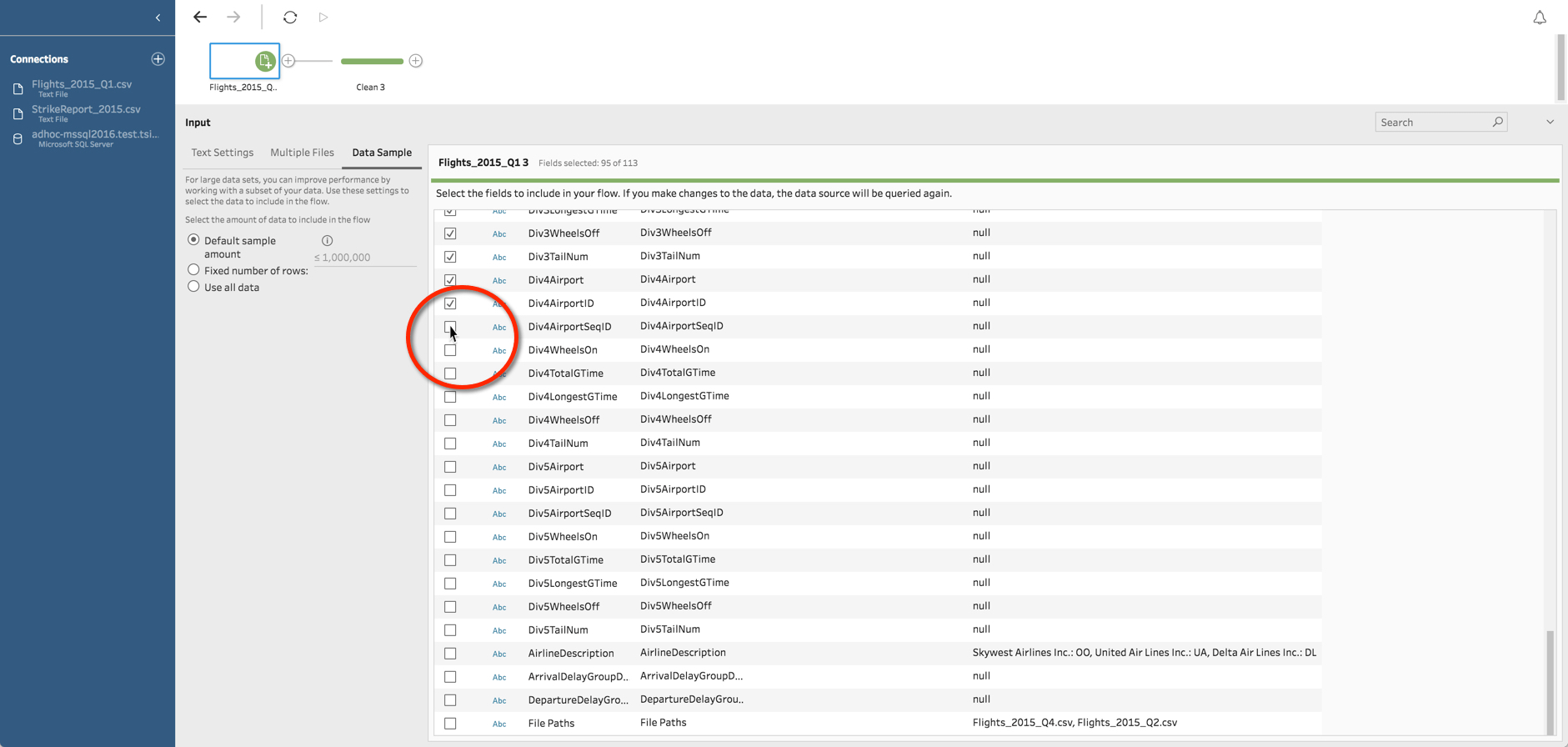
Tip: All changes made in the Input step will cause the data sample to be regenerated. If you have a large data set and want to use random sampling, you can reduce your wait time by making these changes together, or prior to changing the sampling method to random.
If you’re not sure what you can filter or remove during the Input step, the profile pane is a great place to identify those changes. Let Tableau Prep generate a default sample, then use the profile pane to see which fields or values you could remove. Just make sure you go back to the Input step to make those adjustments. This will re-generate the sample, and the rest of your cleaning can be done on an optimized sample.
Using the data sample options
Once you’ve trimmed unnecessary fields and values from the data set, you may still want to change the amount of data in the sample or how the sample is generated.
These settings are available on the Data Sample tab in the Input step:
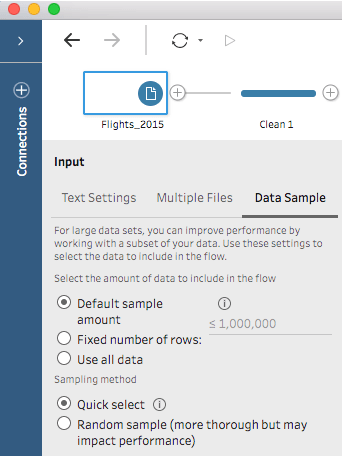
Amount of Data: This option determines how much data is brought into the flow.
Default Sample Amount: The amount of data included in the default sample configuration. This isn’t a fixed number of rows, rather how many records are returned depend on the characteristics of your data.
Fixed amount: Alternatively, you can specify a specific number of records to include in the sample, increasing or decreasing from the default.
Use all data: If you don’t want the data to be sampled, you can select this option to force Tableau Prep to retrieve all rows in your data.
Sampling Method:
This option determines how the records are chosen from the data source.
Quick select: By default, the database returns the number of rows requested as quickly as possible. This might be the first rows based on how the data is sorted, or the rows that the database had cached in memory from a previous query. While this is almost always a faster result than random sampling, it may return a biased sample (such as data for only one year rather than all years present in the data, if the records are sorted chronologically).
Random sample: The database looks at every row in the data set and randomly returns records until it reaches the number of rows requested, making the sample more representative. However, this will impact performance when the data is first retrieved because the entire data set must be scanned (rather than just the first N results like with Quick select). This can be useful if the quick select sample doesn’t contain the data that you need, are performing a wildcard union and want records from each file, or if joining two sampled tables returns few records.
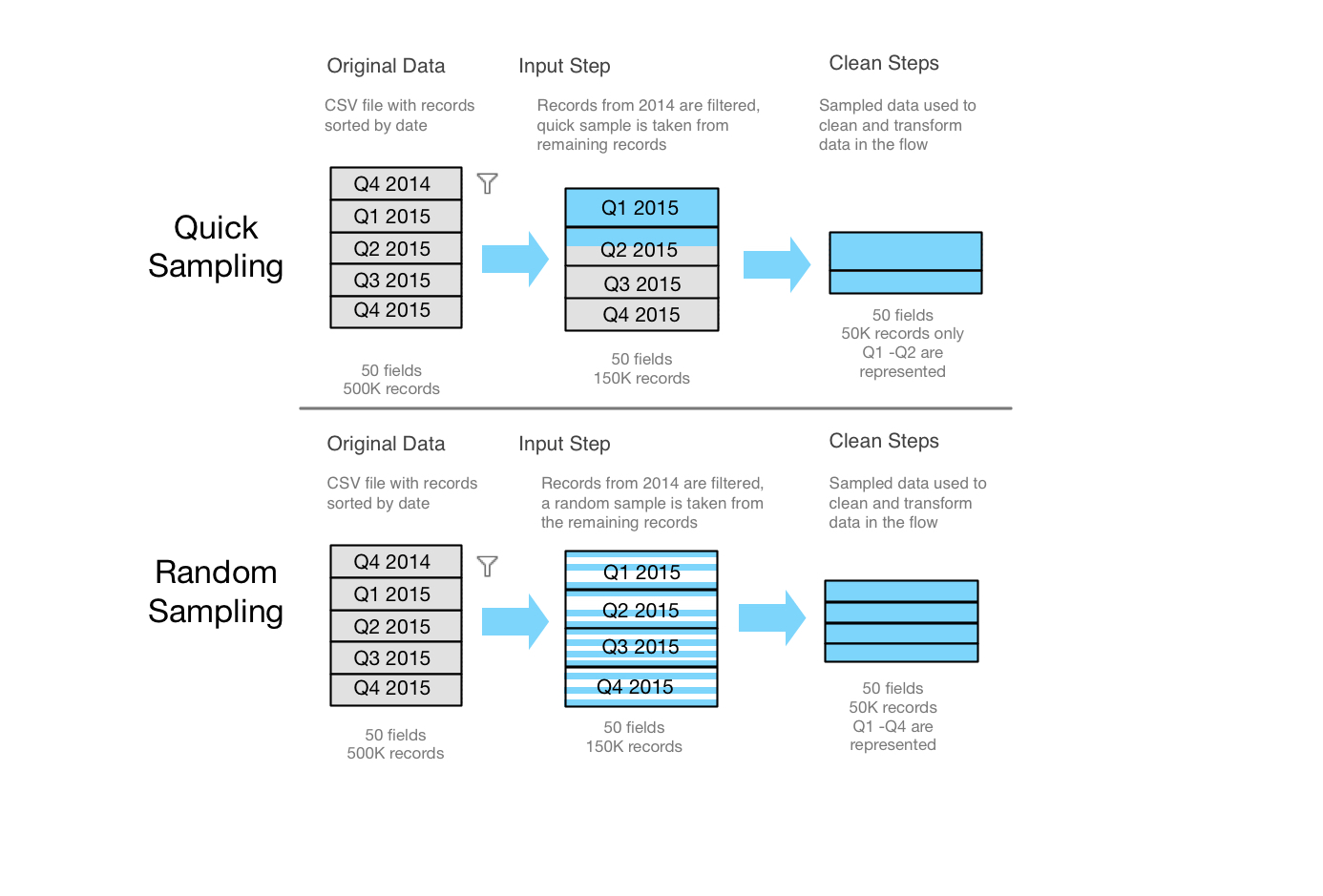
(How random sampling can help if your data is ordered by time.)
Review your output in Tableau Desktop and iterate
It’s important to review any data set that was prepared based on a sample. Run your flow and view the output in Tableau Desktop. (Note that you should run the full flow rather than “view sample in Tableau Desktop” so you can see the entirety of your data). If you see unexpected or incorrect values that weren’t in the sample, you can go back into Tableau Prep to address this. The sample may be regenerated, but you can address known issues even if they don’t appear in your sample by creating a calculation or manually adding a new value via group and replace.
The Tableau Prep team is constantly working on features and improvements that make it easier for you to prepare large data sets by working with relevant samples. You can ask questions or submit ideas regarding this topic in our community forum, or sign up for the prerelease program to try out new features as they become available, and provide feedback.
Related Stories
VizQL Data Service from Tableau: Use Your Data, Your Way
 August 8, 2024
August 8, 2024

When and How to Use Multi-fact Relationships in Tableau
 August 1, 2024
August 1, 2024

Top data books of 2021
 December 12, 2021
December 12, 2021