Helping People Ask Data Questions




TL;DR: Natural language interfaces (NLIs) for visualization have become a prevalent medium for data exploration and analysis. However, the lack of analytic guidance (i.e., knowing what aspects of the data to consider) and discoverability of natural language input (i.e., knowing how to phrase input utterances) make it challenging for people to interact with such NLIs.
This post summarizes our recent work investigating the use of utterance recommendations to provide analytic guidance by suggesting data features (e.g., attributes, values, trends) while implicitly making users aware of the types of phrasings that an NLI supports.
This post is based on the ACM UIST 2021 conference paper “Snowy: Recommending Utterances for Conversational Visual Analysis” by Arjun Srinivasan and Vidya Setlur.
Popular visualization tools like Tableau, Microsoft’s Power BI, and Qlik now offer NLIs for visual data analysis. These NLIs make it possible for people to directly ask questions about their data and specify visualizations without having to learn the nitty-gritty of using an interface. With improvements in natural language processing (NLP) techniques, these NLIs continue to improve at understanding user queries. Furthermore, to assist people in issuing queries and enable a smoother user experience, such systems now also provide smart autocompletion features.
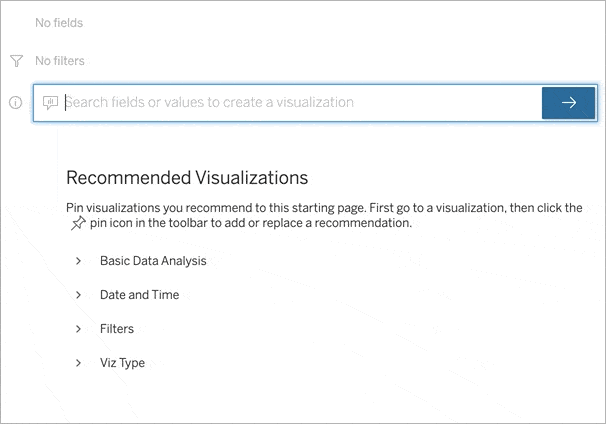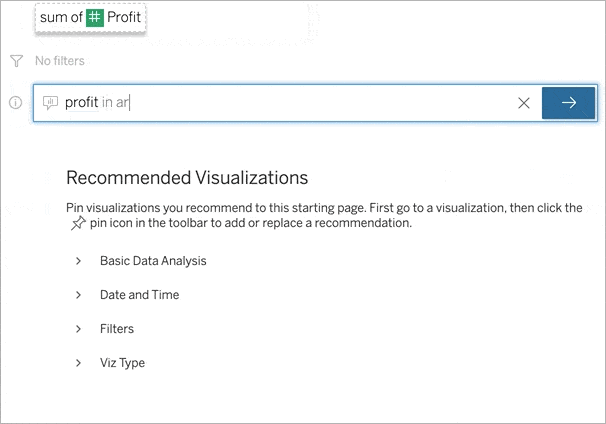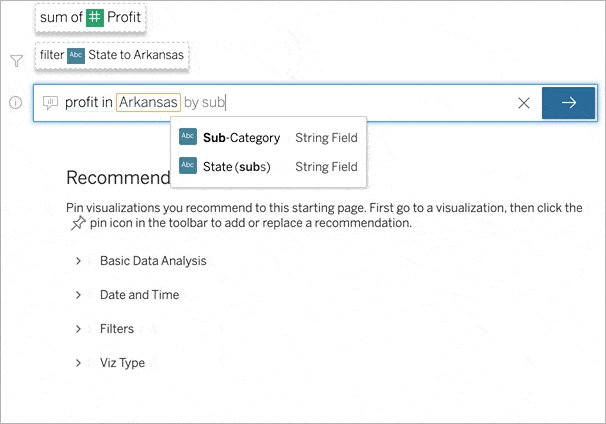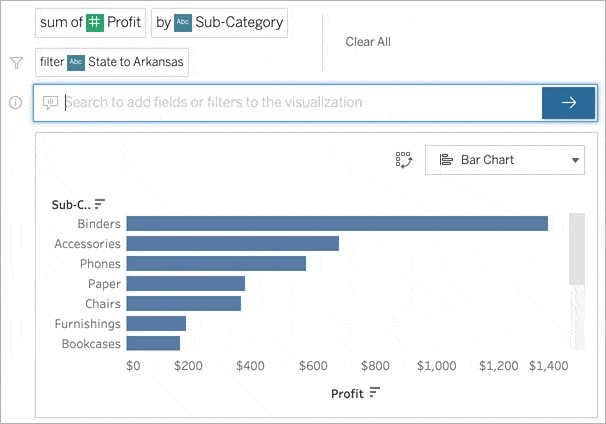
Despite the improvements in NL understanding and assistive features like query autocompletion, asking questions during data analysis remains a challenging task for two key reasons. First, formulating questions requires users to know about the data domain along with potential attributes and patterns to query (e.g., choosing which attributes to investigate a correlation between). This can be particularly challenging when starting a new analysis or when exploring a dataset for the first time. Second, practical limitations of a system’s NL understanding capabilities often require users to phrase their utterances in specific ways that the underlying system can best interpret them (for the remainder of this post, we use the term utterance to refer to any NL command, statement, query, question, or instruction that one may issue to an NLI). Without a clear understanding of an NLI’s interpretation capabilities, users often end up “guessing” utterances, thus being more prone to system failures.
While the lack of analytic guidance (i.e., knowing what to ask) and a lack of discoverability of NL input (i.e., knowing how to phrase utterances) are fundamental challenges on their own, in tandem, these can disrupt the analytic workflow and discourage the use of NLIs for visual analysis altogether.
To address these challenges, we explored the idea of generating contextual utterance recommendations during visual analysis. We operationalize this idea within a prototype system, Snowy, that recommends utterances at different points during an analytic session.


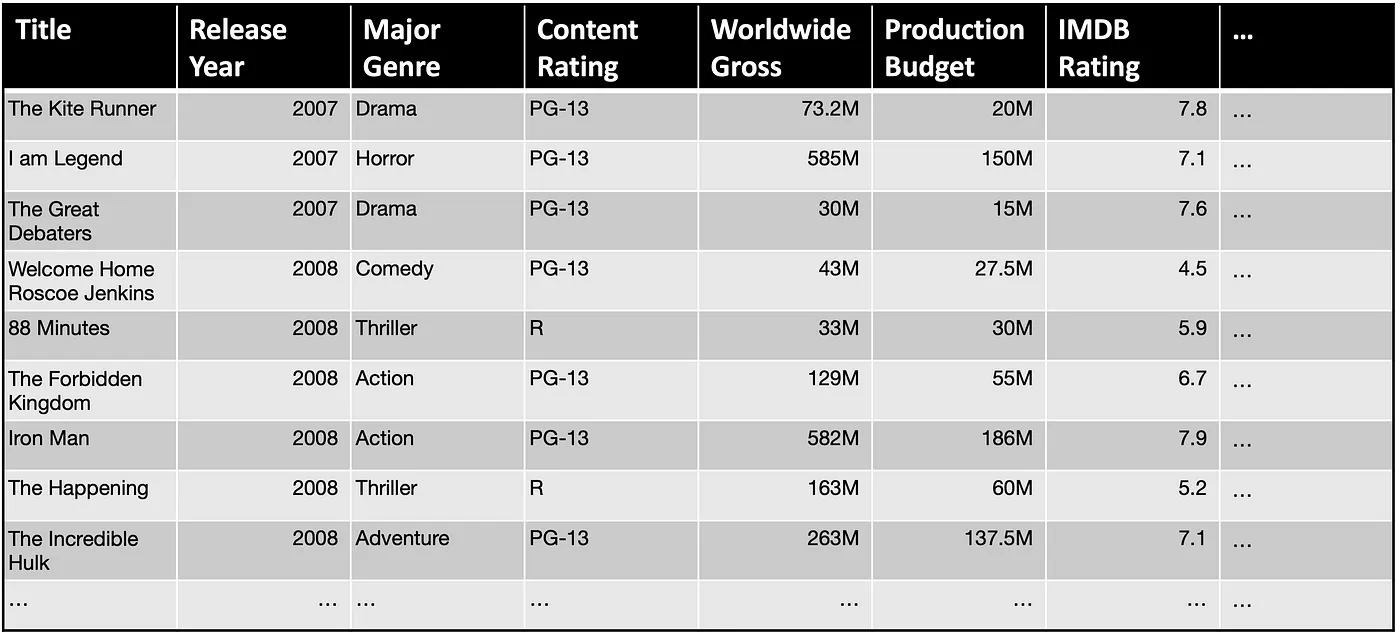
Now let’s walk through a brief illustrative scenario to better understand how Snowy generates utterance recommendations. Imagine Tintin, an analyst at a production company is examining a movie dataset.

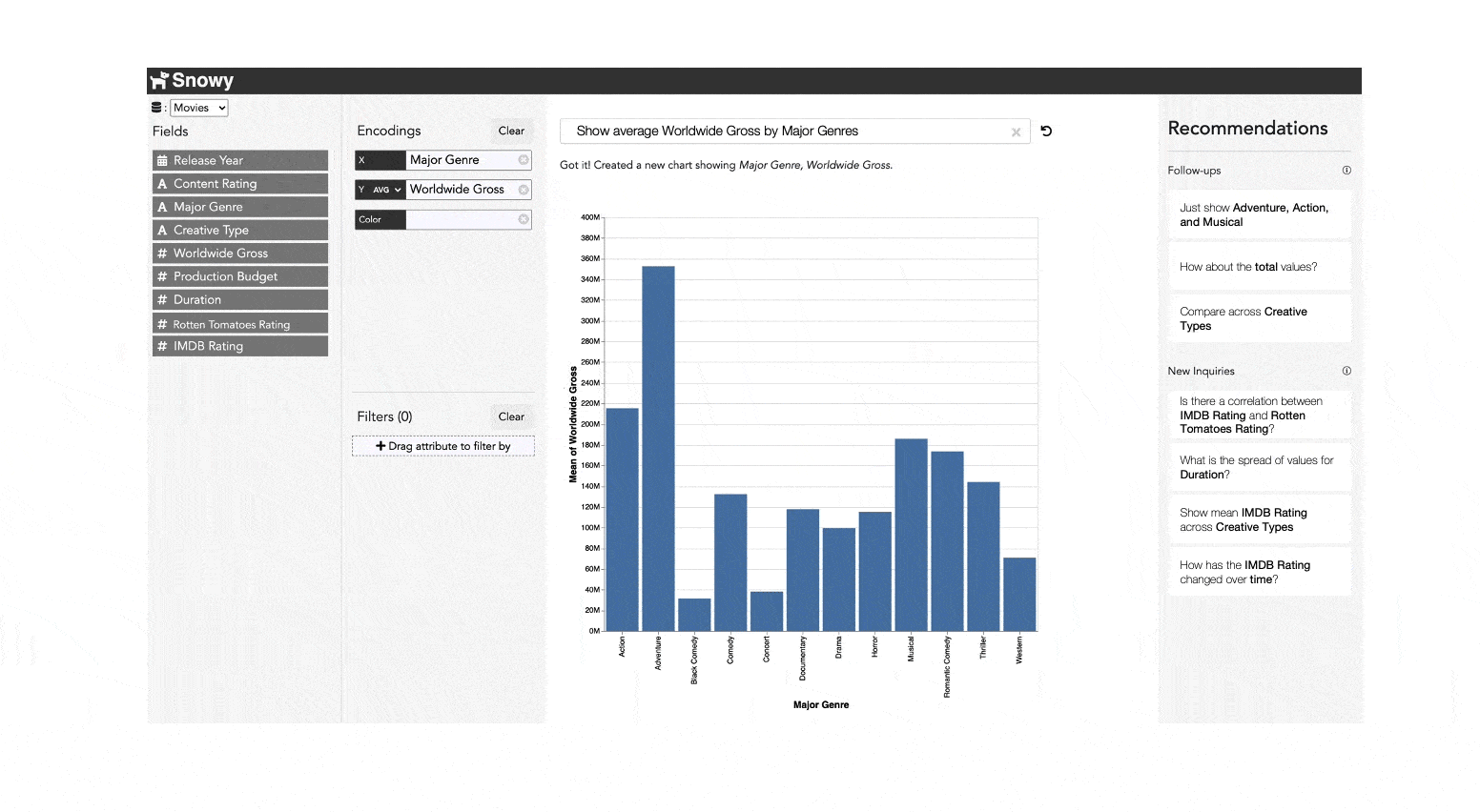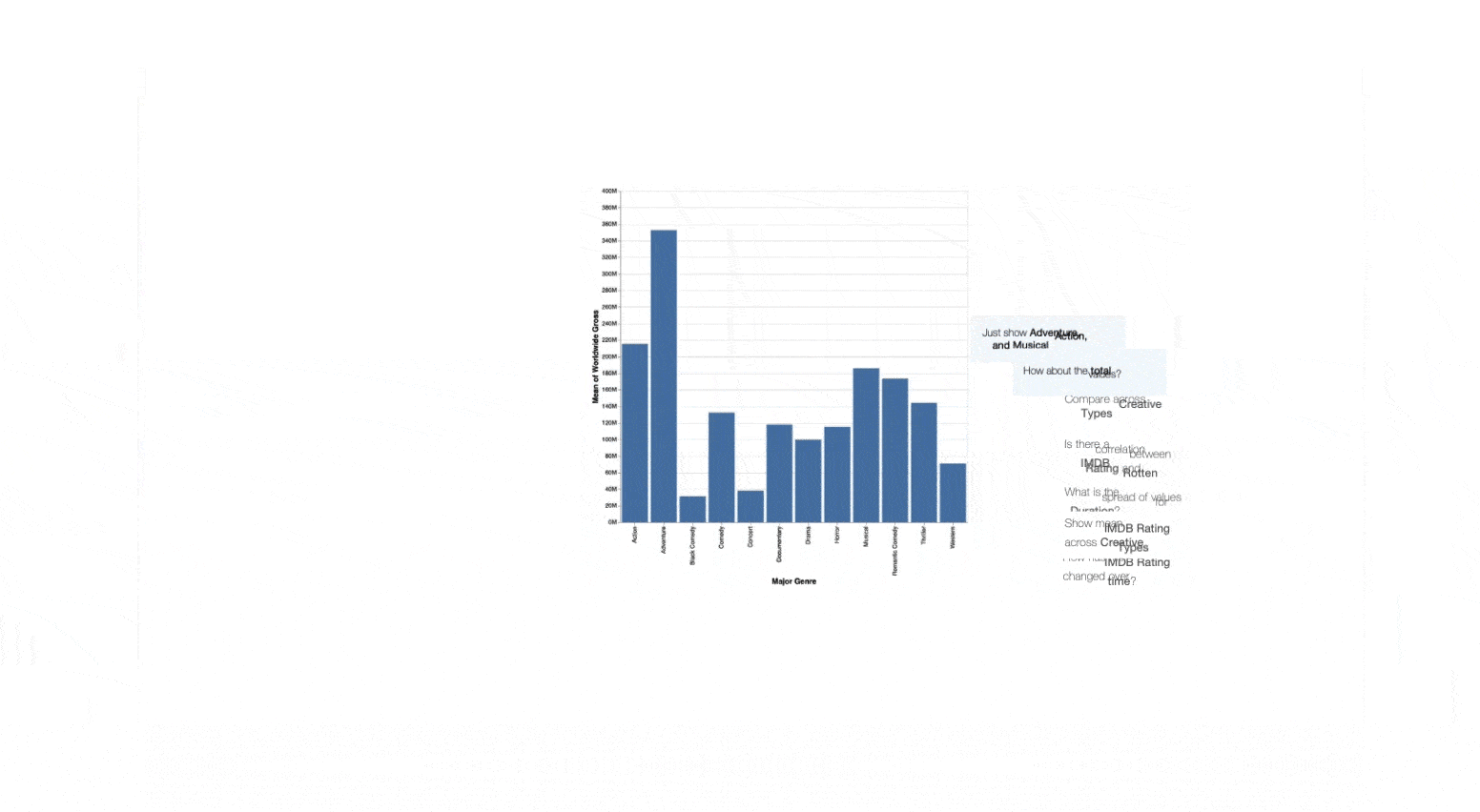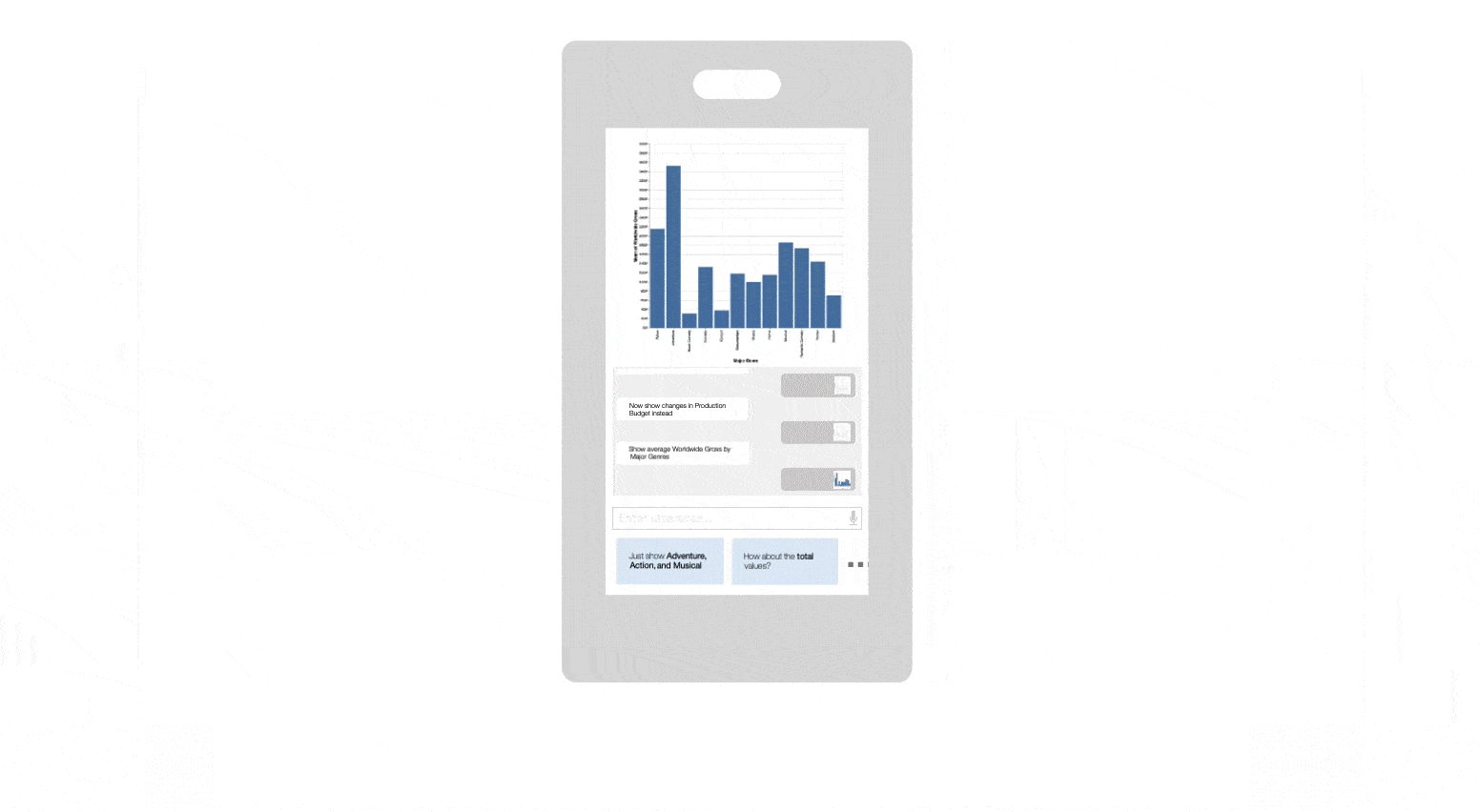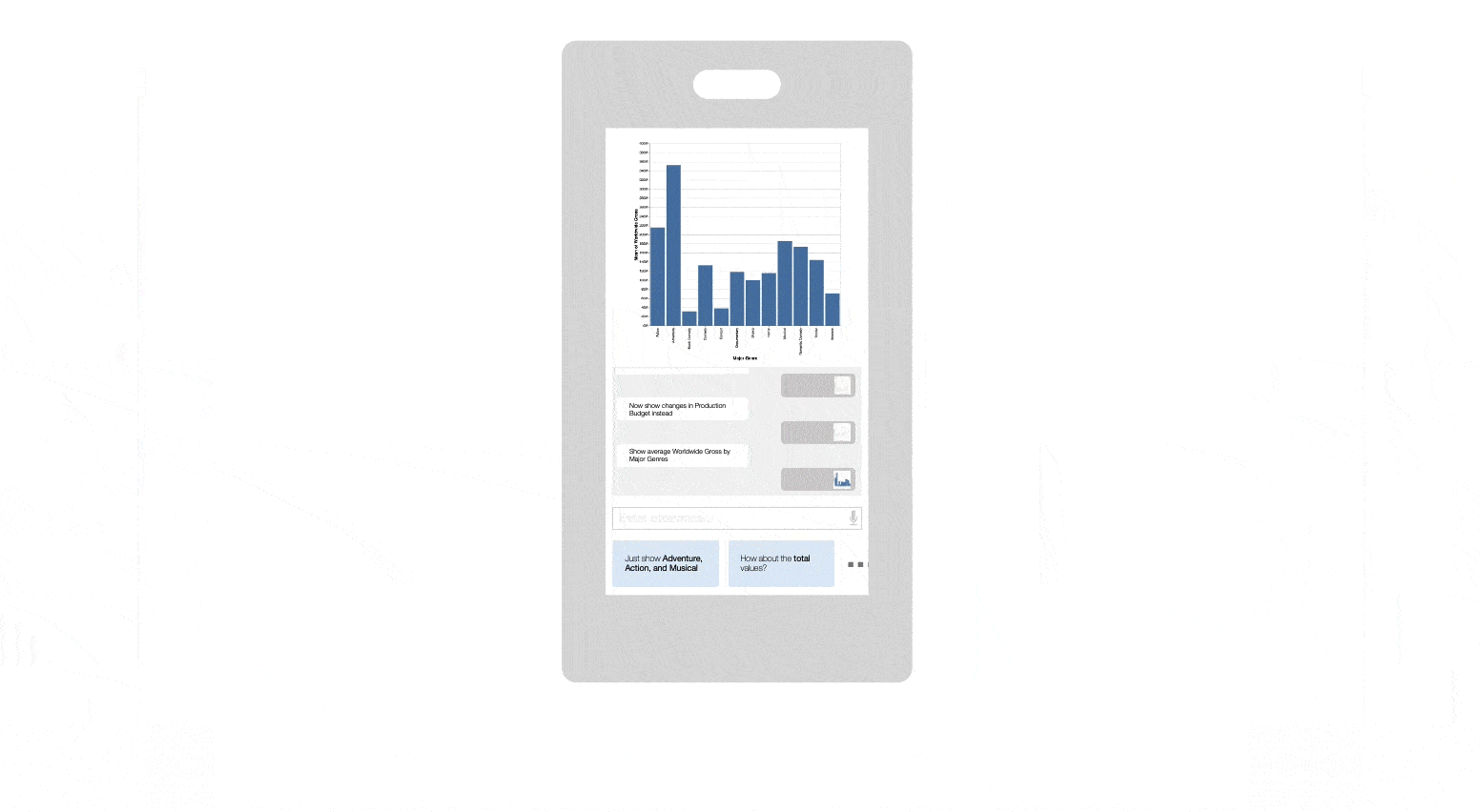
As Tintin loads the dataset, Snowy scans the underlying data to identify potentially interesting attribute combinations to explore and presents a list of utterance recommendations that Tintin can use to start his exploration. Specifically, Snowy recommends utterances that cover popular analytic intents (e.g., finding correlations, observing temporal trends) and populates the recommendations with attributes that might highlight salient data patterns (e.g., Production Budget and Worldwide Gross are suggested for the correlation intent since these attributes are highly correlated). Skimming through the recommendations, Tintin is curious to learn more about the relationship between budget and gross, and selects the utterance “Show the relationship between Production Budget and Worldwide Gross.” Snowy interprets this utterance using its NL interpreter and generates a scatterplot in response.
Next, taking into consideration the fact that Tintin just issued an NL utterance, to promote a fluid analytic experience, Snowy recommends a follow-up utterance “Break down by Content Ratings,” and also updates the initial set of recommendations covering different analytic intents. Notice that the follow-up recommendation is much terser than the other recommendations since this utterance builds upon prior inputs. To investigate the effect of different content ratings on the relationship, Tintin selects this recommendation, resulting in Snowy updating the chart to a colored scatterplot where the colors map to the different content ratings.
With the modified chart, Snowy again updates its recommendations — now suggesting filters for potentially interesting data subsets (e.g., “Drill down into R” since R-rated movies in the dataset exhibit a strong correlation between budget and gross) as well as utterances mapping to other intents and attributes to start a new line of analytic inquiry. However, instead of using the recommendations, at this point Tintin decides he wants to investigate the active chart further to better understand the values and relationships for high budget movies. To do this, Tintin drags his cursor to select movies with a budget of over $200M. As he makes the selection, Snowy updates its follow-up recommendations to now suggest utterances that can be issued exclusively on the selected points (referred to as deictic utterances because their context is derived from the user’s selection). Specifically, in this case, inferring that the active chart is a scatterplot, Snowy suggests computational utterances for calculating the correlation coefficient and the average attributes values. Tintin notes the averages and also that investing in a high-budget movie does not guarantee a significant return and continues his analysis.
So… do utterance recommendations help?
We conducted a preliminary user study with 10 participants to gather feedback on the idea of presenting utterance recommendations during conversational visual analysis. Participants were given two datasets (one about movies and one about US colleges) and asked to perform both targeted analysis and open-ended data exploration using Snowy. After the session, we gathered subjective feedback through a semi-structured interview and a series of Likert-scale questions.
At a high-level, participants said that the recommendations supported their analytic workflows and provided useful guidance during data exploration, without intervening with their self-directed or targeted analysis. Although participants were in agreement about the utility of recommendations to guide their exploration, the feedback on the specific content within the recommendations (i.e., the attributes and values) was more mixed. In particular, participants were unsure about how and why certain recommendations were generated and this lack of clarity resulted in them not feeling confident about the recommended content. However, all participants unanimously agreed the recommendations helped them discover and learn about the system’s NL capabilities including both the situations in which they could issue NL utterances (e.g., to create a new chart, updating an active chart, performing deictic operations) and the types of phrasings they could use (e.g., well structured commands vs. terser keyword-style queries).
To summarize, this feedback from the preliminary study suggests further investigating the use of utterance recommendations — particularly delving into aspects of the recommendations’ interpretability (i.e., conveying why the recommendations are shown and how they are generated) and their impact on learnability and use of NL input. Besides these directions, we are also excited about exploring new scenarios that utterance recommendations can facilitate (e.g., data-oriented chat applications, or in accessibility contexts where traditional visualization recommendations cannot be shown).
For more details about the Snowy system and the user study, please refer to the accompanying research paper and project page.
If you find this topic exciting, be sure to continue the conversation and reach out to us with any feedback or questions.
Related Stories

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 April 14, 2026
April 14, 2026
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 April 10, 2026
April 10, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 June 8, 2025
June 8, 2025