Fun with Optimal Random Sampling



Finding an elegant solution to a basic problem can be fun (and especially nice when it can be put into practice). In this post, I’ll introduce three random sampling algorithms that are optimal, elegant, and extremely easy to implement.
Here’s a basic problem. Draw k random samples from 1, …, n without replacement. Give an algorithm to do this optimally, with exactly k random draws and O(k) time and space for any k,n.
Sounds simple, right? Surprisingly, algorithms used in practice fail to achieve this. In practice, not only do they suboptimally require > k random draws, many libraries and languages simply implement slow, highly suboptimal algorithms that always take O(n) time, which is pretty much as bad as it gets for small k.

I’ll introduce three optimal algorithms that can be implemented in < 10 lines of code and can solve some useful problems that go beyond the basic random sampling without replacement problem. Two are novel algorithms³, while one, Floyd’s optimal algorithm, unfortunately seems to have been lost in history.
As a bonus for math lovers, you’ll see how multiple random sampling algorithms, including these three optimal algorithms, just fall out if you choose the right representation of a permutation.
Algorithm 1: Fisher-Yates Sampling
Let’s start by thinking about how to draw a sample without replacement. One idea is to shuffle the items and pick the last k. There is a slick algorithm to do this shuffling: the Fisher-Yates shuffle.
import numpy as np
import numpy.random as rnd
import scipy.stats.distributions as distributions
def fisher_yates(n, k):
A = np.arange(n)
for i in reversed(range(n-k+1, n)):
r = rnd.randint(i) (
A[i], A[r]) = (A[r], A[i])
return A[(n-k+1):n]
The Fisher-Yates shuffle essentially repeatedly samples without replacement. After iteration t, the t items at the end of the array are samples, and those at the beginning are the n-t unsampled items. Each iteration draws a position in the array of unsampled items, and a swap simultaneously moves the chosen item to the samples while updating the unsampled items.
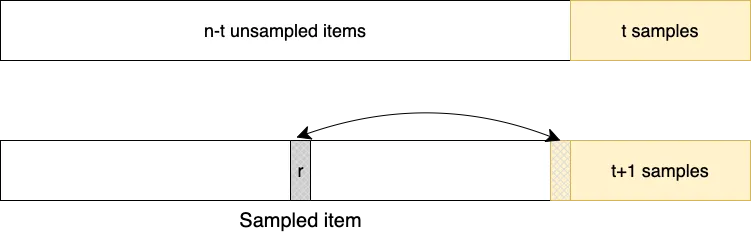
Sampling instead of shuffling only requires k draws, and using this fact gives the classical swapping procedure. Unfortunately, even with this optimization, the algorithm takes O(n) time to initialize a length n array.
But why should I initialize a length n array when I only perform k swaps? This observation leads to our first new, optimal algorithm: a “sparse” Fisher-Yates that uses a hash table instead of array to keep track of the swaps. A python implementation as an iterator is given below.
def sparse_fisher_yates(n):
A = dict()
for i in reversed(range(n)):
r = rnd.randint(i+1)
yield A.get(r, r)
A[r] = A.get(i, i)
if i in A:
del A[i]
What’s particularly cool about this algorithm is that you can generate a sequence of samples. You don’t need to specify the sample size k in advance. If you need another sample, just perform another swap.
A Useful Mathematical Representation
Now let’s look at a mathematical representation of the algorithm to see what else we can learn.
Mathematically, a swap of items in positions x and aₓ is called a transposition and written as (x aₓ). The Fisher-Yates shuffle essentially says that a random permutation π can be written as the product of n transpositions:
π = (1 a₁) (2 a₂) . . . (n a_n)
where each aₓ ≤ x. That is, each transposition (x aₓ) can only swap position x with an earlier position or with itself (i.e. do nothing). The Fisher-Yates shuffle applies the transpositions from right to left. In group theory, this is the left action of the permutation on an array.
The sampling version of Fisher-Yates only applies the k rightmost transpositions from right to left.
What’s neat about this representation is you can read off different shuffling and sampling algorithms from the representation. If you apply the transpositions in the opposite order from left to right and only keep the values in the first k array positions you get Reservoir Sampling (seemingly a topic of many tech interviews).
What is really cool is that by reading off the transpositions in another way, you get a very elegant sampling algorithm, Floyd’s optimal sampling algorithm. This algorithm was published by Bentley and Floyd in 1987 [1] but seems to have been lost in time (perhaps because it came after Luc Devroye’s bible [2] on random number generation in 1986).
Algorithm 2: Floyd’s optimal algorithm
Rather than sampling from all n items at the beginning, Floyd’s algorithm [1] starts by considering only n-k+1 items and drawing a sample of size 1. At each iteration, it both introduces one more possible item and increases the sample size by 1 . On the draw t, it draws a location L from Uniform(1, …, n-k+t). If L has not been drawn before, it adds L to the sample. Otherwise, it adds the new item n-k+t to the sample.
def floyd_sampler(n, k):
H = set()
for i in range(n-k, n):
r = rnd.randint(i+1)
if r in H:
yield i
H.add(i)
else:
yield r
H.add(r)
This algorithm also falls out naturally from the transposition representation. Apply the k rightmost transpositions and use the last k positions for the sample like Fisher-Yates, but apply them left to right like Reservoir Sampling, and you get Floyd’s optimal sampling algorithm!
To see this, imagine the transpositions are applied to an array initialized to 1, …, n. The first n-k positions always represent the unsampled items. The ith iteration decides what should go in position n-k+i in the array. If it selects an item R not in the sample (i.e. from the first n-k positions) it swaps out the initial value of n-k+i with R, which adds R to the sample. Otherwise it swaps it with another value that is already in the sample, so the initial value n-k+1 is retained and added to the sample.
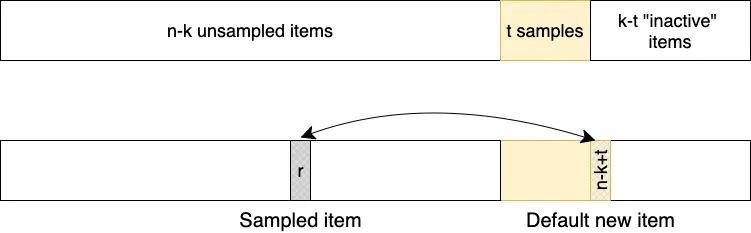
If not only the sampled items but their positions in the array are maintained, you get a new, simpler variant of Floyd’s algorithm for generating a sample in random order.
def floyd_perm_sampler(n, k):
H = set()
x = np.arange(n-k, n)
for i in range(k):
r = rnd.randint(n-k+1+i)
if r in H:
j = rnd.randint(i)
(x[i], x[j]) = (x[j], x[i])
H.add(n-k+i)
else:
x[i] = r
H.add(r)
return x
The advantage of Floyd’s algorithm is that it requires only a set data structure and not a map. However, both n and k must be specified in advance, and the basic version does not produce a uniformly permuted sample.
Algorithm 3: In order samples w/ Beta-Binomials
The last algorithm is my favorite of the three. It returns samples in sorted order. This is useful when random access is expensive, for example when reading from disk.
There are several algorithms to do this given in Luc Devroye’s “bible” for random number generation (1986). However, they come with a caveat,
“All techniques require a considerable programming effort when implemented.”
In fact, in the software listed in the table above, Vitter’s algorithm D is the only one in this class that has a real world implementation. It’s not hard to see why when you see a description and implementation.
Ironically, this improved algorithm is perhaps the easiest of the three to implement! At each step, the algorithm finds the position of the next sampled item within the stream. While past methods developed complicated, custom procedures to sample the distribution of the next position, I’ll show draws from standard distributions suffice, namely the common Beta and Binomial distributions (and the Beta distribution isn’t even necessary [4]).
def in_order_sampler(n, k, offset=0):
if n < 0 or k <= 0:
return nskip = distributions.betabinom.rvs(n, 1, k)
yield offset + nskip
yield from in_order_sampler(n-nskip-1, k-1, offset+nskip+1)
To see how this works, draw the same sample two different ways: first by shuffling and then by counting. Start with an array of n independent Uniform([0,1]) random variables. Sorting them generates a random permutation and then “unsorting” generates the inverse permutation. So if I start with the sorted values and “unsort” them to shuffle the array, selecting the first k values gives a random sample from the set of Uniform([0,1]) values. The positions of these selected items in the sorted array gives a random sample of 1, …, n. These positions can be computed a second way. Draw the first k independent Uniform([0,1]) values: U₁,U₂, …, U_k. The position of an item Uₓ can be computed by drawing the remaining Uniform random variates and counting how many are ≤ Uₓ.
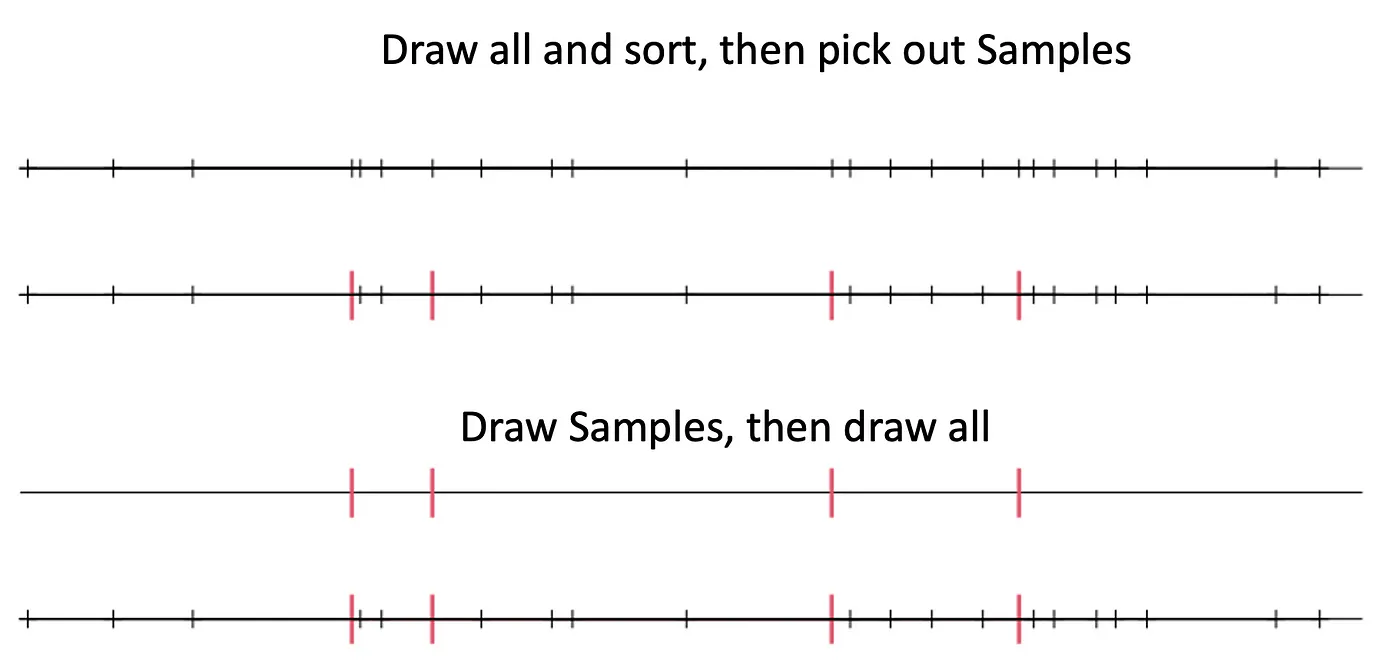
Concretely, the first position L in the sample can be computed by taking k Uniform([0,1]) draws and computing their minimum B. The position is simply how many of the remaining n-k Uniform([0,1]) draws that are < B plus 1. This makes the problem of drawing a position easy. Draw B, then count.
A well known fact about the minimum M of k i.i.d. Uniform([0,1]) draws is that it has distribution B ~ Beta(1,k). Of the remaining n-k random variates, a Binomial(n-k, B) of them are < B since all draws are independent. Thus, the first sampled position is L ~ Beta-Binomial(1,k, n-k) + 1.
(As a sidenote, this algorithm actually came from the transposition representation as well and illustrates how research in seemingly unrelated topics can be surprisingly connected. I stumbled upon it when looking at nonparametric Bayesian clustering models during my PhD. There’s an “insertion to the left” process which gives the position and which arises from converting the transposition representation to the cycle representation (the Chinese Restaurant Process). However, the uniform r.v. explanation is simpler for those unfamiliar with this process.)
Distributed/Parallel sampling
This idea has other nice uses in the distributed or parallel sampling setting that you can read about in the formal paper [4].
Conclusion and What to use
I’ve presented interesting new algorithms for random sampling, and all three are theoretically optimal. So which should you use?
The appropriate choice is perhaps dictated more by the sampling scenario. Is the data stream length n or sample size k is known in advance? Is random access efficient? Or is the data distributed? The beauty is that these algorithms are so simple that you can implement them all.
update: Micheal Shekelyan and Graham Cormode pointed out that a version of the sparse Fisher-Yates algorithm is also in a preprint in Arxiv: CacheDiff: Fast Random Sampling (Bui 2015). They also have a very recent paper (with code) on another neat method for in order sampling. It cleverly uses Fisher-Yates to reduce the main problem to a simple with replacement sample. Check it out, and if you don’t have access to a binomial random number generator, it‘s likely the easiest in-order sampler to implement (and fastest).
[1] Bentley, John and Floyd, Robert (1987). A sample of brilliance. Communications of the ACM, 30(9):754–757.
[2] Devroye, Luc (1986). Non-Uniform Random Variate Generation. Springer.
[3] After writing this post I discovered a post by Paul Dreik describing a sparse Fisher-Yates applied to shuffling rather than sampling though.
[4] Ting, Daniel (2021). Simple, Optimal Algorithms for Random Sampling Without Replacement. Arxiv. https://research.tableau.com/paper/simple-optimal-algorithms-randomsampling-without-replacement
Related Stories

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 April 14, 2026
April 14, 2026
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 April 10, 2026
April 10, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 June 8, 2025
June 8, 2025