Free Tools for Your Data-Prep Kit




"By failing to prepare, you are preparing to fail."
This month, we've been talking about preparing data in Tableau Public. With the help of our Data-Agony Aunt, guest bloggers, and developers, we've shared, in detail, how to use the data interpreter, pivot or join your data, and split it or clean it with formulas. (ICYMI, here's a nice summary of things we've learned.)
To close this month, we'd like to tell you about some of the other free tools out there for data preparation, from collection to cleaning and consolidation. Let's explore these tools in the order of increasing complexity.
Extract Tables from a PDF Document with Tabula
Tabula is a very neat and easy to use tool that lets you find the tables inside your PDF and exports them as a text file. Once you've downloaded Tabula from the link above, launching the tabula.exe will bring you to the below web page:
Importing your PDF in Tabula.
After your PDF has been successfully imported, Tabula will let you choose between two options:
- "Autodetect tables" will highlight in red the elements that Tabula recognizes as tables. You can then go and delete the ones that have been improperly highlighted.
- Select the target tables yourself by drawing a rectangle around them. You can do a page-by-page selection if the tables in your PDF are irregular.
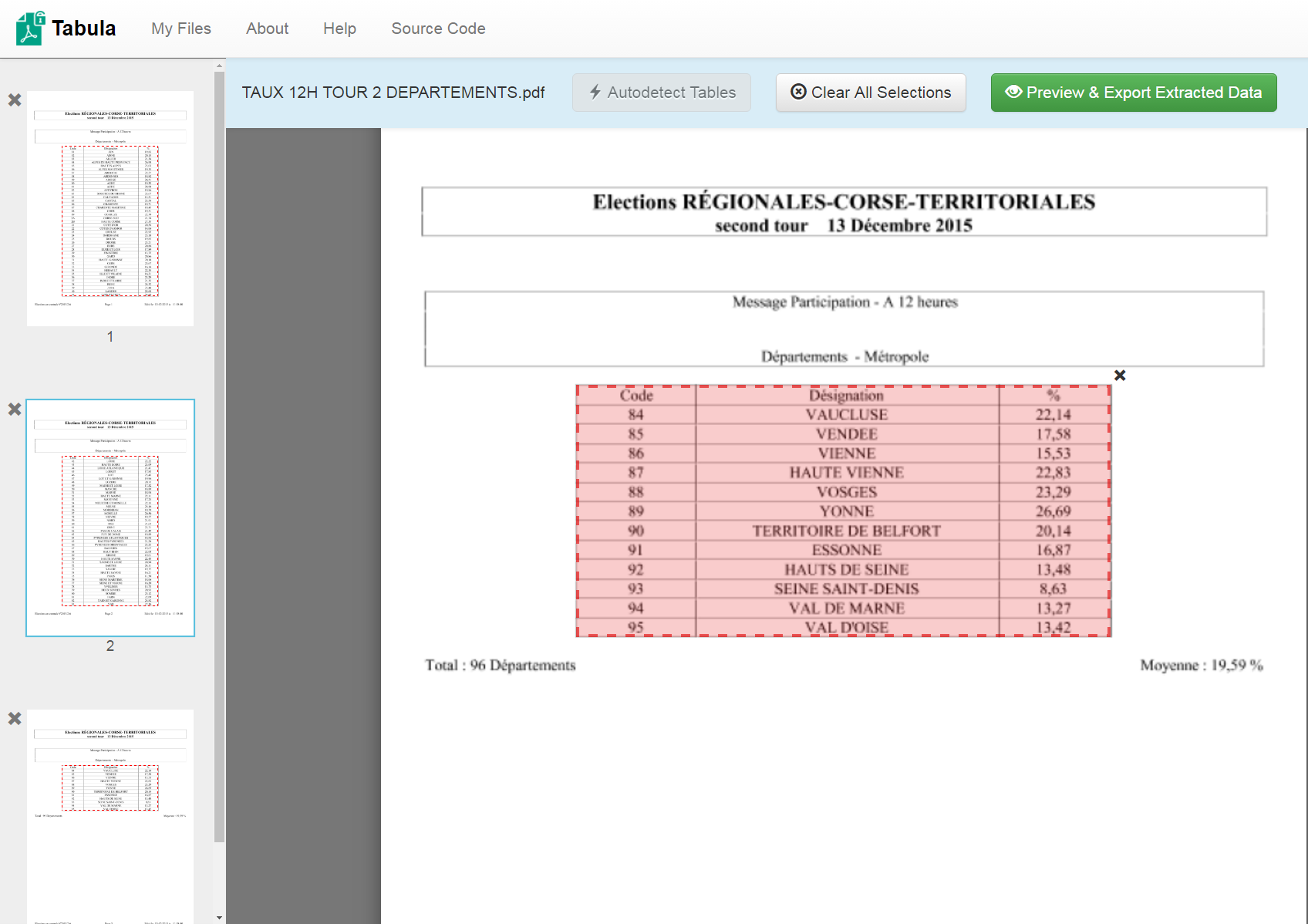
Finding tables in your PDF with Tabula.
Once this is done, just click "preview & export extracted data." Choose the format you want for your export (CSV, JSON) or just copy the whole table to clipboard and paste in Excel. Voilà!
Now, let's move on to data cleaning. There are a bunch of cleverly-built tools that let you identify errors and inconsistencies in your data, combine different data sources, and format data to be machine-readable. Remember: To be good, a data-prep tool must operate in a systematic and replicable way. Being intuitive is a plus; being well-document is a must.
Clean Your Data with DataWrangler, an Online App
Starting with DataWrangler makes sense as it is the easiest to test. You can access the app here, and directly paste in your text data.
I should mention DataWrangler started as a research project and is no longer supported, but it has evolved into a fully-supported commercial piece of software in Trifacta Wrangler, which also happens to be free. I’ll walk you through DataWrangler as I’m most familiar with that tool, but do give Trifacta Wrangler a try. Robert Kosara says “the app is designed very nicely with many features and built-in tutorial."
Paste your text data direcly into the app.
You can play along using the sample data set on crime stats, which is also the one used in this demo video. The concept is easy: Click on elements in your data set, and DataWrangler will suggest some transformations ranging from the most specific (single transformation) to the most general (apply to all similar occurrences). Hovering over a suggestion lets you preview the result of applying it.
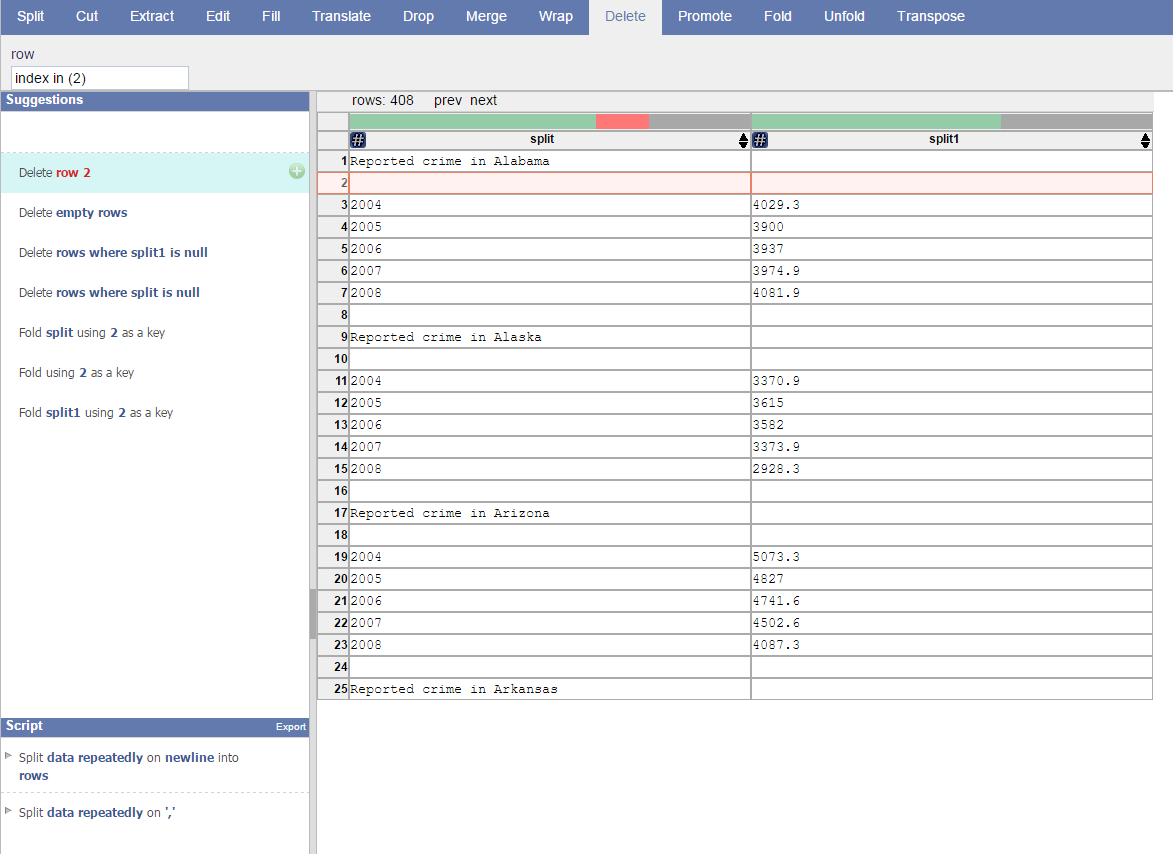
Click on elements you'd like to transform, be they entire rows or a single cell.
Here, by selecting an empty row, DataWrangler suggests deleting this specific row as well as deleting all empty rows or rows where one of the cells is empty. By playing around a little while in the tool, one can quickly understand the logic behind item selection and the various elements available in the top menu.
And of course, DataWrangler lets you export a recipe ("script") that you can apply to other data sets with the same characteristics.
Clean Your Data with OpenRefine (Formerly Google Refine)
Famous in the world of open data and data journalism, OpenRefine benefits from loads of tutorials from a variety of sources. It's not a difficult tool to learn, but it does have a lot of functionalities, and you'll need to get into its logic of "facets" and "filters" to perform your data cleaning. You'll probably have to learn a couple of formulas as well to apply corrections to the anomalies detected.
Here is a great detailed tutorial to start with. It explains how to download OpenRefine and start performing basic data-prep actions like cleaning up inconsistent spelling, removing duplicate rows, or finding geographic coordinates for a list of place names. The series of three introduction videos available on OpenRefine's homepage is also a good resource when you're getting started with the tool.
In OpenRefine, import your data in any file type you like.
The welcome page lets you import a variety of data file types, including the classic Excels and CSVs. If your data file hasn't been recognized properly, make the corrections directly in the preview pane before moving on to creating a "project." In the project view, you will be able to filter your data on a given field or explore the distribution of one of your numeric columns (measures in Tableau) to see whether values are consistent.
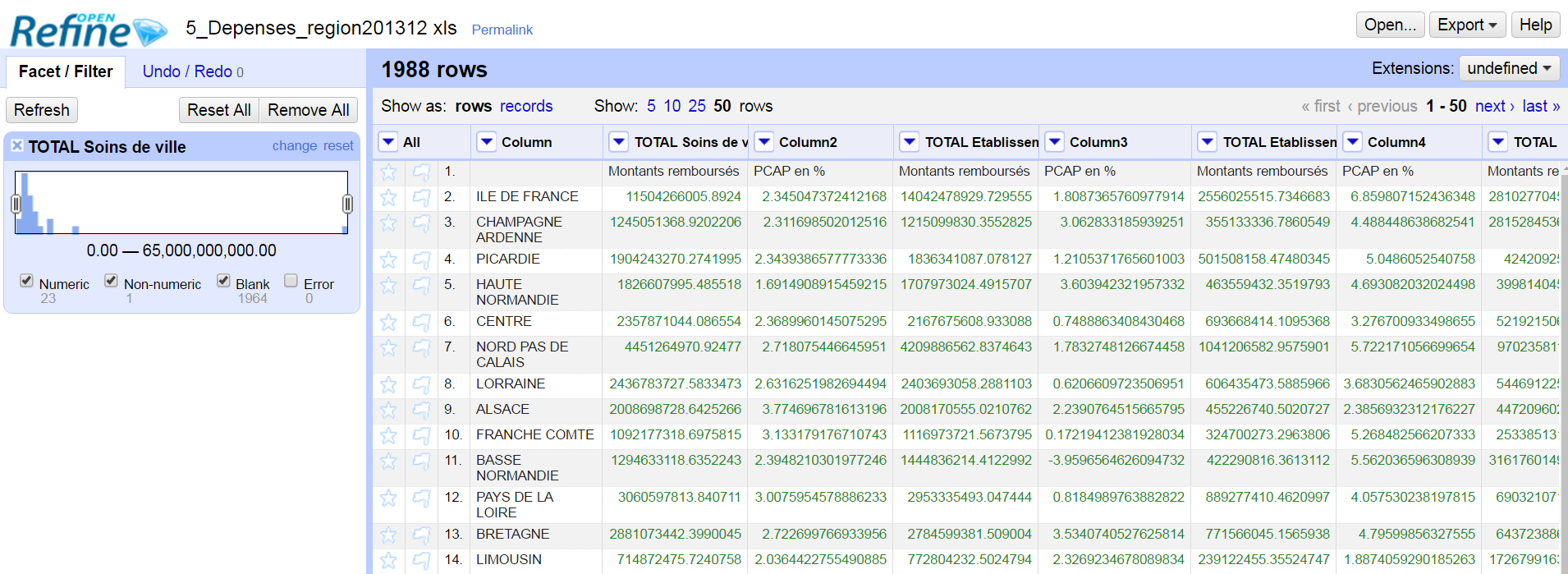
Analyze the distribution of any column in your data set to check for inconsistencies or outliers.
In the above picture, there is one outlier at the very right of the distribution range of my "numeric facet" which may indicate a row of totals somewhere in the data set. I can exclude it using an expression in the Google Refine Expression Language (GREL), Jython, or Closure. A methodic column-by-column analysis will help you spot and correct similar irregularities. And one of the greatest features of OpenRefine is the clustering of "text facets," which lets you identify similar strings of characters and group them when anomalies are due to misspellings.
Needless to say, OpenRefine also creates recipes that can be applied again and again on similarly-designed data sets.
More advanced users will probably use the Pandas library in Python or R, which both let you prepare and clean your data, and they'll find all the material they need to get started online.
It is now time to close #SpringDataCleaning month. We hope you've enjoyed reading tips for structuring and preparing data. For a great closing read, check out "Unions in Tableau 9.3: Tips and Tricks" by Tableau Zen Master Joshua Milligan, aka @VizPainter.
And stay tuned for the theme announcement for the month of June!
Related Stories

Iron Viz 2026: Read Between the Data
 May 28, 2026
May 28, 2026

Tableau's Iron Viz Winners

Explore the 2026 Iron Viz Entries
 December 15, 2025
December 15, 2025