Developing the Connector SDK
How can the Connectivity Team help every customer see their data? Learn how we develop connectors that let you query and extract data from a variety of data sources.




How can the Connectivity Team help every customer see their data? We develop connectors that let you query and extract data from a variety of data sources. This functionality is so intrinsic to Tableau that some of the first C++ product code ever written was for our MySQL and Microsoft SQL Server connectors. Over the years, we have continued to add connectors to meet the diverse needs of our customers.
Below is a viz showing the number of new connectors that the Connectivity team has added over the years, totaling about 60. The null column shows connectors that will be available in our next software release.
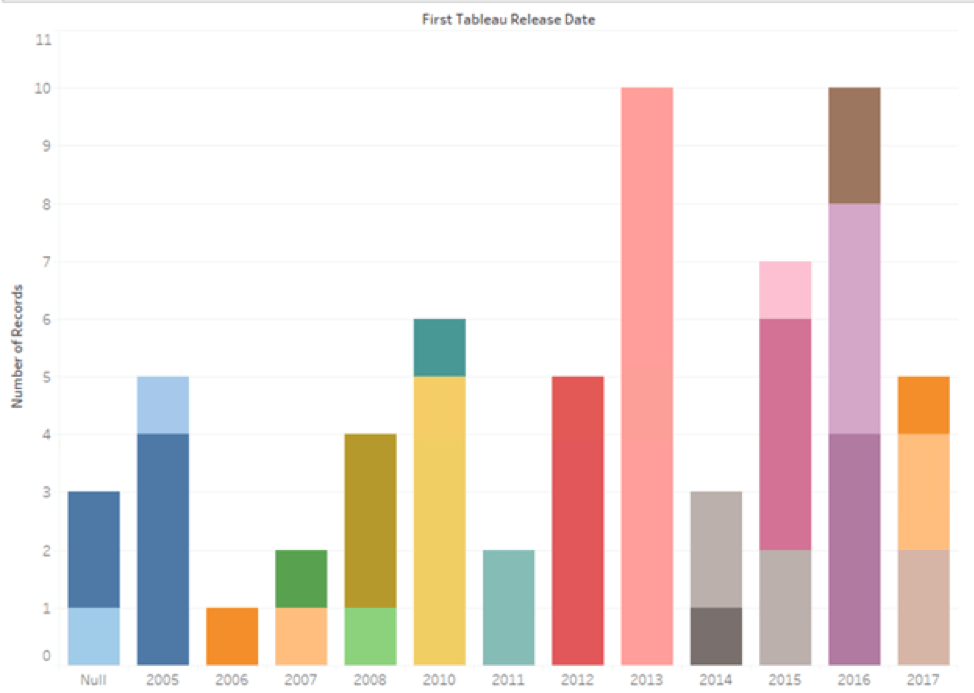
Figure 1: Tableau Connectors added per year.
The database engine ranking site db-engines.com lists over 300 databases and that number doesn’t include the myriad of web services with data APIs, such as Google Drive. Given this large number and variety of databases and services, how can the Connectivity team add hundreds of new connectors, simultaneously testing, maintaining, and supporting them all? How can we support the next generation of databases that haven’t been developed yet? While the Connectivity team has grown over the years, we can’t possibly hire enough engineers to accomplish this.
To further complicate matters, our C++ code base has grown organically over 14 or more years, and at one point adding a new connector to our code base meant creating a dozen new files and modifying 10 or 15 areas of code spread across different modules ranging up and down the stack. This was bad enough, but the most time-consuming aspect of developing a connector was fine-tuning the generated SQL to construct Tableau’s analytical queries. Making these changes in C++ code meant we had to recompile, build and then test many times per day. We desperately needed a flexible and extensible way to write a new connector, and a way to rapidly tune the generated SQL. With the blessing of senior leadership, a few intrepid individuals embarked on a quest to refactor our architecture and make it more modular and flexible.
What is a connector?
Before we dive into how we refactored our architecture to better scale the production of connectors, let's back up and begin at the beginning: what exactly is a connector? A Connector is code that defines how Tableau can communicate with a data source to query and extract data. This can be a complicated task involving several stages such as connecting, connection management, generating and running queries the data source understands, and error handling.
Our C++ code defines a high-level interface to the Connector, which includes methods related to these tasks. Using inheritance we’ve been able to specialize this functionality to cover several broad cases including ODBC, JDBC, file-based connections like Microsoft Excel, and even some REST APIs like Google BigQuery. These powerful abstractions let us handle diverse data sources in a uniform way pushing down code that deals with a particular data source or technology to a more specific class in the hierarchy.
Inheritance and abstraction are useful techniques, but they can’t solve every problem. Sometimes the team will add a new Connector very similar to an existing one, such as MariaDB which is based on MySQL. Inheritance can help here, but often results in a complicated class hierarchy consisting of many nearly empty classes. Using the object-oriented technique of delegation, we created a thin reusable and customizable wrapper that represents an interface to the connector and delegates most of the behavior to an existing connector class. This keeps our class hierarchies manageable, but also paves the way for a much more flexible approach to adding connectors in the future. We called these "subclassed connectors" since they represent a reuse and further customization of an existing connector.
By using delegation and composition, we can easily change behavior at run time. This powerful approach lets us make a dynamic connector that can be defined in an XML file when the system starts, using the specifications in the XML file to customize behavior at run time. By writing various extension points in the XML, you can change the behavior as desired or fall back to the parent connector’s code.
Data-Driven Architecture – ConnectionBuilder method
Continuing our journey to make our architecture more modular and flexible, I'll describe how we customized building the driver connection string. ODBC and JDBC drivers require a connection string or URL, which specifies the driver to use, the server address and port, username, and password, often allowing various connection options to fine-tune behavior. The connection string must be dynamically generated based on user input and is usually customized for each of our connectors which means reuse is not an option.
Initially, each connection contained a static method that would take an associative map of connection attributes and their values, producing an ODBC or JDBC connection string. Our first step was to pull that code out and put it behind an interface called IConnectionResolver, which defines a method called ConnectionBuilder. The old static method from the Connection was moved over to a new class that implemented the interface.
Next, we needed a way to easily customize the ConnectionBuilder method for a new Connector defined outside the C++ code. We needed a lightweight and flexible approach since this method can contain several levels of nested if/then statements depending on how complicated the connection scenarios are. The most appealing method was to load and run a script file, so that a new Connector author would have ultimate control over the connection string. (This would also leave doors open for future connection scenarios because the logic is loaded at run time.) We implemented this by writing another class called the JavaScriptConnectionResolver which would load a JavaScript function at run time and use that to evaluate the ConnectionBuilder function.
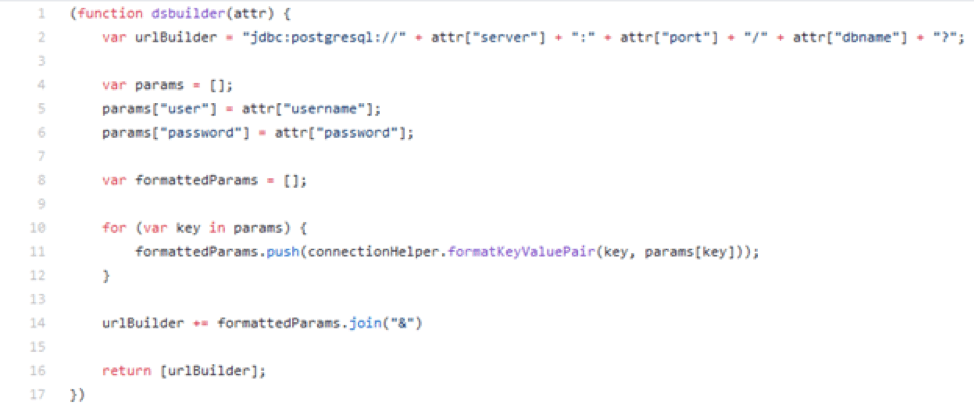
Figure 2: Example JavaScript ConnectionBuilder method.
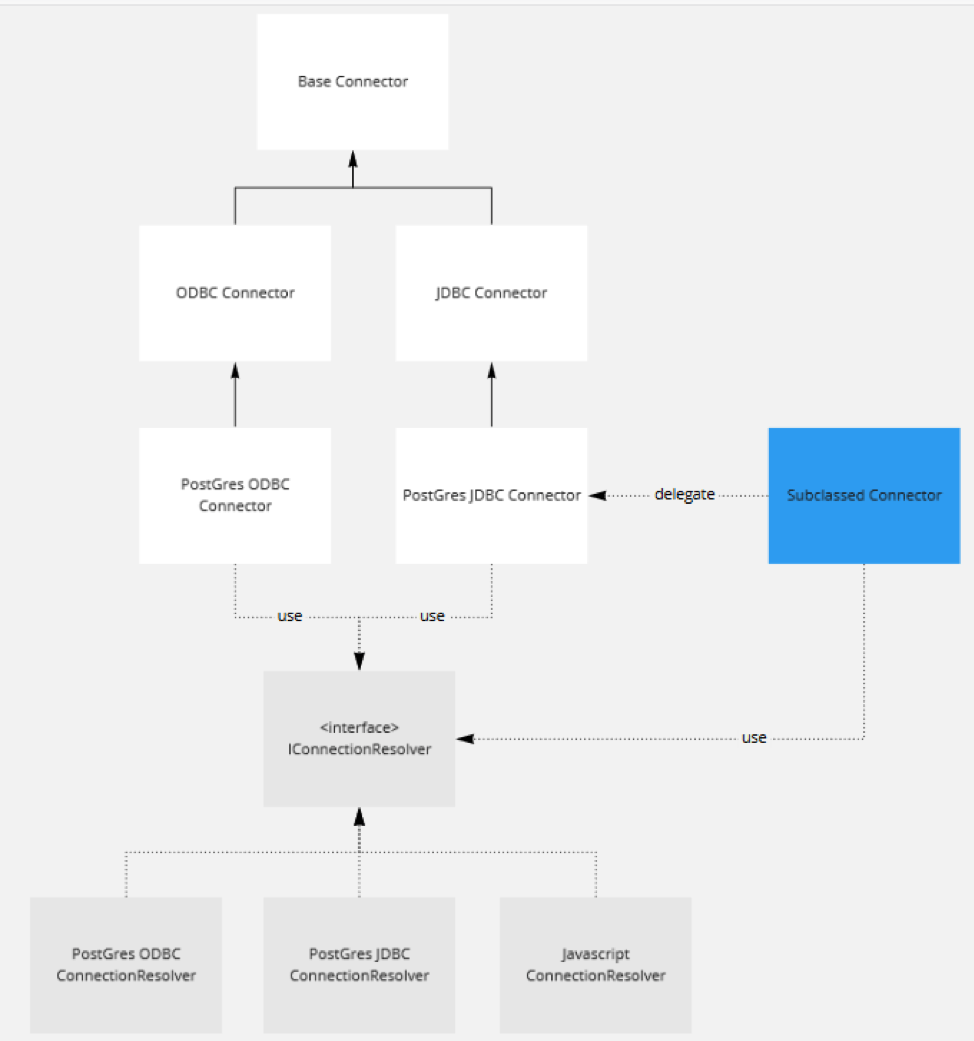
Figure 3: Simplified architecture showing a subclassed Connector based on PostGres JDBC.
We added more extension points for choosing a driver, describing the connection user interface, and defining the SQL dialect. The ability to specify the SQL dialect outside of code is a huge step forward for developer productivity. A new connector can reuse an existing SQL dialect from another connector that Tableau engineers have already written and it can be further customized at a function level. This dialect is loaded at run time so there is no need to compile any code and the results can be viewed in seconds.
The road ahead
In 2019.1, we shipped the MariaDB Connector, which is built using our plugin technology and was developed much faster without writing a single line of C++ code. Developing a robust and easy-to-use packaging system is very high on our list for 2019. This will allow external vendors to develop connectors that they can support and distribute.
There are a few extensions points that we would still like to develop such as table, database and schema enumeration, reading metadata, and connecting to stored procedures, but the Connector SDK is already very capable for many scenarios.
I encourage anyone with a database and ODBC or JDBC driver to try it out. The Beta SDK is available now at Tableau’s GitHub page and contains documentation, samples, and test tools. Once you try it out, please share your feedback with us and the Tableau Community through the GitHub Issues page or the Tableau Developer Forum.
Related Stories

Fast and Flexible Access to Data with Tableau's Google BigQuery (JDBC) Connector
 April 3, 2023
April 3, 2023
How to Get Access to Amazon S3 Data Directly from Tableau
 December 6, 2022
December 6, 2022
Customers heavily use S3 as part of their AWS implementations to store large files in S3 in various file formats. The Amazon S3 Connector for Tableau provides simple and fast access to Parquet, CSV, and Excel files stored in the cloud directly from Tableau.

Additional Tableau Connectors now available through the Tableau Exchange
 August 27, 2020
August 27, 2020
Tableau now offers partner-built data connectors through the Tableau Exchange. Learn more about these new connector extensions and the Tableau Developer program.