How I Learned Tableau Prep with Data + Movies




Fifteen years ago I took on the role of data analyst and inherited a database with a lot of complications—no schema or documentation, no guidance, and little help in the way of support.
I taught myself SQL, leveraged online resources, reverse-engineered others’ work, and learned database design largely alone. One of the biggest payoffs for me was a lesson I learned from my dad when I was younger—being inquisitive will help propel you in new directions. From the time I was a kid my dad drilled into me the value of understanding how things are assembled and why it’s done that way. It’s something that applies to both work and play and is as appealing for me now as a father as it was when I was a kid.
This self-development by necessity paid off, and I became a respected member of the business outside of IT, who was trusted to help build the tables, views, and functions, and who stored procedures necessary to run a multi-billion dollar non-profit.
When the initial Data + Movies challenge dropped I was immediately struck by the size of it, a whopping 1.09GB. Wow!
Yes, it was a ton of great data, but I was also a little disappointed.
Looking under the hood, I could tell there was quite a bit of duplicated data, causing the file size to bloat. I suspected it was due to database design, and dedicated myself to making it better.
I had known about Tableau Prep for a while, and even used it once to troubleshoot someone else’s project, but had never developed a new project in it. I suspected that if I leveraged Tableau’s native relationship modeling capabilities and disaggregated the data from a single table, I could create a more efficient model.
Getting started with Tableau Prep
To tackle the challenge I created a plan of attack:
- Identify duplicated data
- Diagram a normalized data model
- Extract the data out of Tableau
- Flow it into Tableau Prep
Sounds easy enough, right?
I started by listing every data element to assess how much uniqueness there was. It boiled down to Titles, Persons, Genres, and Production Companies. Separating those into camps largely deduplicates the data.
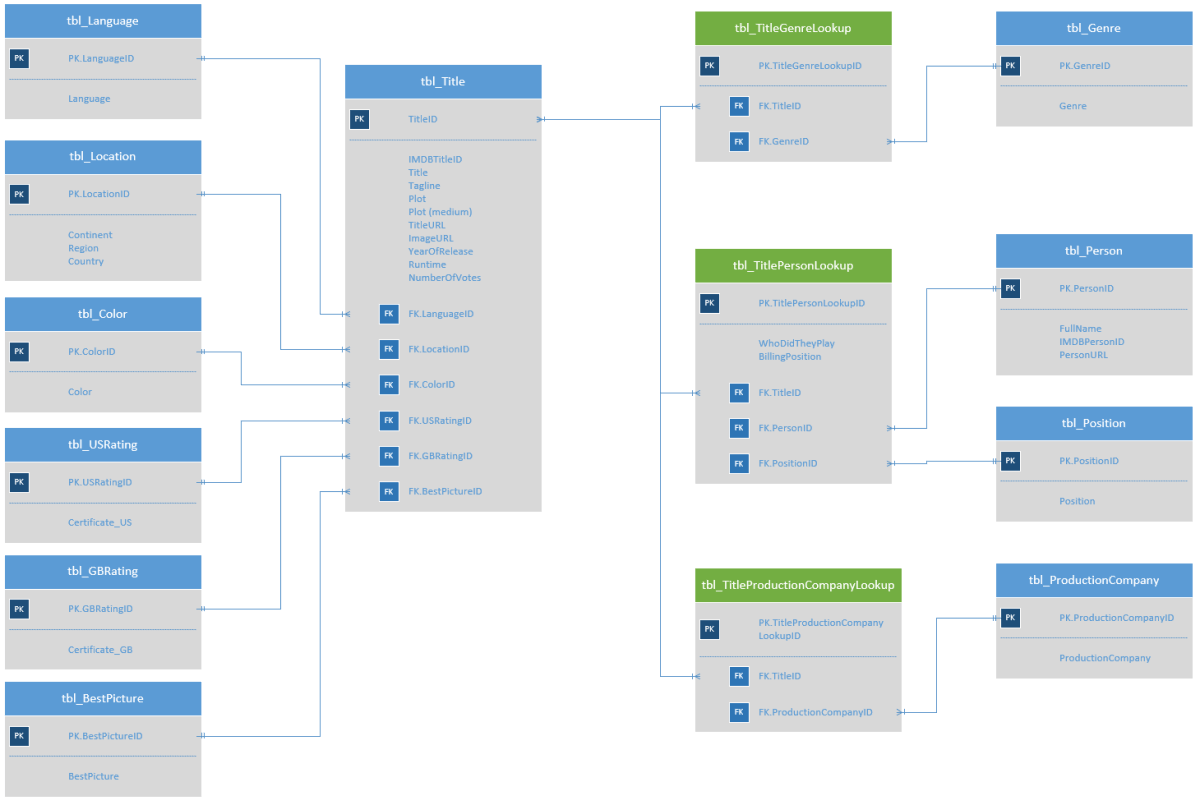
A new model
I applied best practices when I built the new data model.
Certain fields necessitated unique identifiers. Person and Titles both had unique IDs but were made of strings, which are costly in data models. Integers are much smaller and allow for faster joining, but this meant that I needed to introduce new data.
Moreover, other data was duplicated that didn’t have a unique ID. Even more data needed to be related through reference tables because of many-to-many relationships. This meant creating more data than existed originally, and I feared this adventure might end in failure.
Nevertheless, I continued.
Extracting data out of Tableau seems tricky, but I was able to leverage Tableau Community for a clever little trick: a Tableau .twbx is a fancy zip file. I unzipped it and located the hyper file that stores all the data. This clocked in at 2.5GB. That’s a 2.5x compression—amazing!
It’s Prep time!
Since I was new to Tableau Prep, there was a bit of trial-and-error at first, building out 14 individual flows to create the required outputs. As I learned and evolved in Tableau Prep usage, I realized I could do this all in a single flow that might be more difficult to build but a fun challenge. Moreover, a single flow would ensure I used the correct lookup keys. Turns out I only needed to know a few Tableau Prep objects in order to realize my dream.
Aggregation
In my initial Visio design, I knew there were 11 tables consisting of unique data and another three reference tables I’d need. The reference tables are really the secret sauce, allowing for many-to-many relationships on things like actors, crew, genre, and more. So I knew I’d be starting my data modeling process using the powerful Aggregation Object, which makes listing unique values a cinch.
Split and pivot
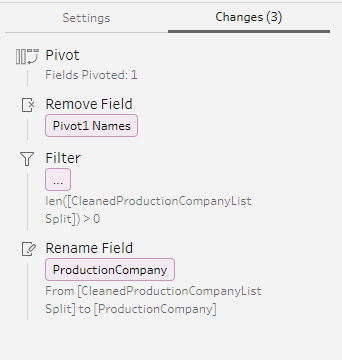
Speaking of multiple genres, one of the genre fields housed an array. An array lists multiple values in a single field. The original architect had split the values into separate fields, but this also created an issue. If you filtered on one genre field, say for “comedy,” there was no guarantee that another film was not a comedy if that was split into a different field and you could be unintentionally excluding data.
I approached this problem by splitting the array and pivoting it along the title. This would allow a film with multiple genres to be represented by multiple rows instead of columns. This created my first reference table.
In data modeling, a tall and narrow dataset is preferable to short and wide.
Surrogate keys
In a database, a primary key is a naturally occurring unique identifier within the dataset.
The IMDb dataset had two unique keys: Person and Title. If I was to build out this dataset in a modern snowflake model, I would need to generate other unique keys.
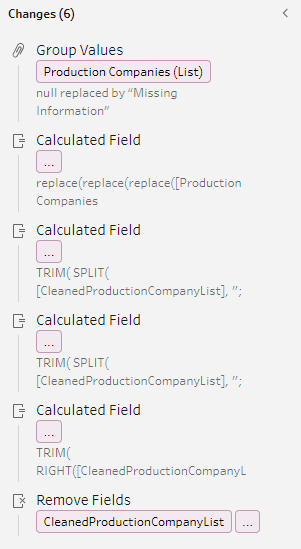
That’s where surrogate keys come into play. Surrogate keys hold no business value or meaning other than to aid in database design. For each table being created, I created a calculated field and ordered by whatever was special in the table.

ROW_NUMBER() creates an integer value, and the list of production companies is ordered alphabetically.
Cleaning
Some of the cleaning steps I used were done to replace nulls with “Missing Information.” This way, if a film was lacking data language, I could ensure all titles were represented either by the language available or by informing the user that no information was available.
Other cleaning steps were to hide data no longer necessary that was created along the way or filter out blanks created when fields were split.
Packaging
Once I understood how to do all of these steps, I worked through when to interrelate everything. I needed the surrogate keys created early enough to reference them as foreign keys in other tables. And since I was committed to doing this in a single flow, I was prepared for a mess.
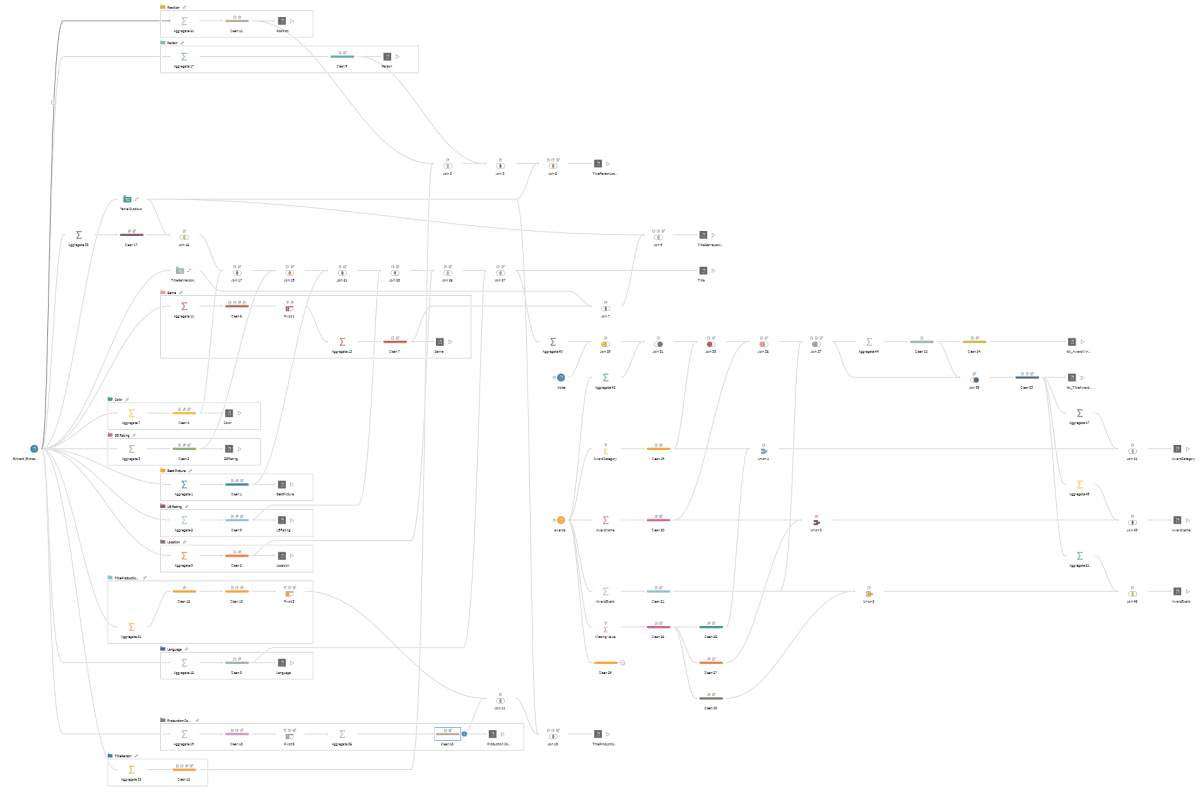
Once everything was run through Tableau Prep, it was just a matter of putting it back into Tableau using the model developed.
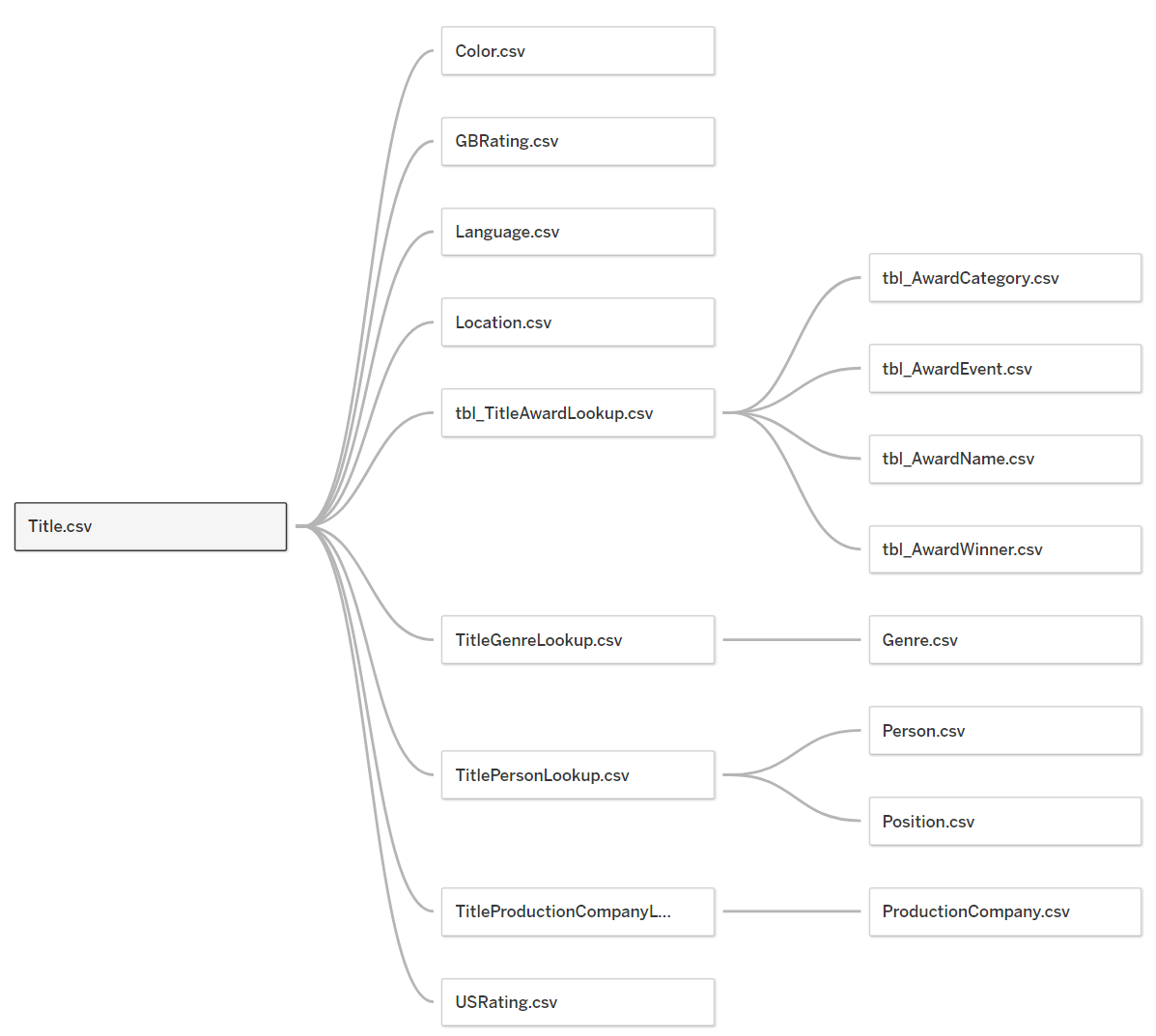
Done.
I successfully used Tableau Prep to condense 1.09GB of IMDb data down to 219MB—a 5x compression!
What’s even more amazing is that this included more data than before by way of the reference tables and keys developed.
My friend Zach Bowders in his article “Cinematic Insights: The Art of Movie Analytics” said, “Data is about making connections.” Tableau Prep allowed me to find the underlying relationships within the data and expose them in a positive way. The Data + Movies challenge lets you uncover the stories of the movies you grew up with and love. For me it gave an opportunity to learn something new: Tableau Prep!
Related Stories

9 Tips to Succeed in a Tableau DataDev Hackathon
 January 8, 2025
January 8, 2025

A Guide to Mapping and Geographical Analysis in Tableau
 November 15, 2024
November 15, 2024

Making Tables Smarter: Key Features of the Tableau Table Viz Extension
 November 14, 2024
November 14, 2024