Upgrading your Tableau Server with Hyper



Hyper is Tableau's new in-memory data engine technology optimized for fast data ingests and analytical query processing on large or complex data sets. Now, Hyper powers the data engine in Tableau Server 10.5, which is used when refreshing, or querying extracts. It is also used for cross-database joins to support federated data sources with multiple connections.
Recently we released a blog series highlighting Tableau Desktop scenarios and interactions between Tableau Server and Desktop.
This article will focus on Tableau Server and the upgrade experience.
Changes to Tableau Server Configuration
What’s different on Tableau Server?
Server architecture will remain the same, but there are some changes to the server configuration that we've detailed below.
- The Data Engine process is no longer configurable. It is automatically installed when any one of the following processes is installed on the machine:
- File Store
- VizQL Server
- Application Server (VizPortal)
- Data Server
- Backgrounder
- Only one instance of the Data Engine process is installed per machine or node.
Typically, these changes do not affect a single-node installation but may affect the configuration for a multi-node cluster, especially if you have certain processes isolated on a separate node, or have more than one instance of the Data Engine process installed on a node.
Let’s take a look at the upgrade experience using the following scenarios:
Scenario 1: Single node installation
Johnathan, who works for a small startup, is preparing to upgrade to Tableau Server 10.5. He has a single node installation and sets up a test machine to test the upgrade. The current configuration on the machine includes only one instance of the Data Engine process, which is similar to his production Tableau Server.
After downloading the Tableau Server 10.5 installation file, he runs the Tableau Server setup program on his test machine. Johnathan follows the installation steps and notices that these steps have not changed since his previous upgrade to 10.4. After completing the upgrade, he sees no changes to the server configuration.
After the upgrade to version 10.5, the scheduled extract refreshes on the test server upgrade the .tde extracts to .hyper extracts. Johnathan makes a note of this so he can remember to disable the scheduled refreshes prior to upgrading the production server. This way he has control over when the extracts are upgraded to .hyper extracts to avoid potential compatibility scenarios that are described in Part 2 of this blog series.
He then invites a few of his colleagues to make sure that things are working as expected. He and his colleagues are able to publish both 10.4 and 10.5 workbooks to Tableau Server 10.5 and they are able to download and use the upgraded extracts using a Tableau Desktop 10.5. Johnathan also notices that the extract refreshes are completing in a shorter amount of time than before, and his colleagues report that the workbooks are loading much faster.
Happy with their experience, Johnathan then proceeds to upgrade their production Tableau Server to version 10.5.
Scenario 2: Multi-node installation with specialized nodes
Sarah, a server admin for a large company, is preparing to upgrade to Tableau Server 10.5. Sarah’s company has a three-node cluster with the Backgrounder process isolated on one of the nodes to support a high extract refresh requirement, as shown below:
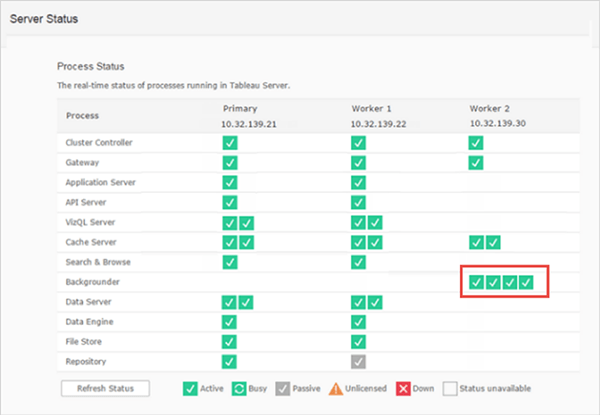
She sets up a test environment with the same configuration and recruits a few employees from each department to form a test team.
Prior to testing the upgrade, Sarah reviews the help documentation about pre-upgrade tasks and makes a note about the recommendation to disable extract refresh schedules as they would result in upgrading the published extracts from .tde to .hyper. She does not want that to happen automatically, so she disables the extract refresh schedules.
She downloads the installation files for Tableau Server 10.5 and runs the Tableau Server setup program on the primary node. During installation of the primary node, she sees a message that the worker nodes could not be upgraded automatically. She then signs in to each of the worker nodes and runs the Tableau Worker setup program. After completing the upgrade on the worker, she returns to the primary node and follows the prompts to complete the installation.
After successfully completing the upgrade on her test environment, she reviews the Server Status page, which now shows an instance of Data Engine on the node that has the Backgrounder installed:
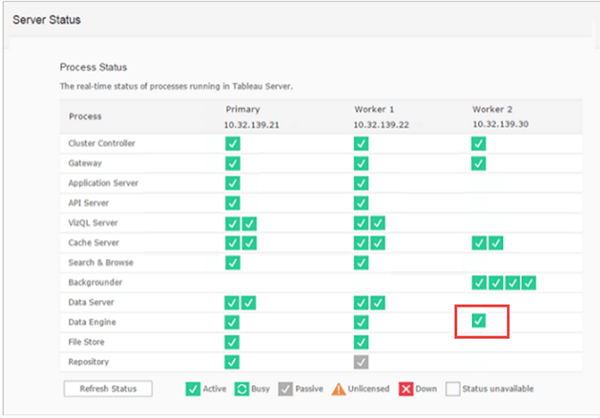
Once she has confirmed that the Tableau Server upgrade completed successfully, she then upgrades the test Tableau Desktop machines to 10.5.
She and her test team proceed to test the new upgraded test environment:
- They sign in to the Tableau Server to make sure they have access and can get to the same content they are able to in their production environment.
- Using Tableau Desktop 10.5, they publish workbooks and data sources, and test to make sure that they appear as expected.
- Sarah manually refreshes a few extracts to confirm that they complete successfully. She also runs a couple of key scheduled extract refreshes and is pleasantly surprised to see them complete successfully and take less time to complete!
- Her test team downloads and views published workbooks using Tableau Desktop 10.5. Overall, the team is happy with the improved performance that they see when interacting with the workbooks.
- The test team finds a couple of workbooks where they see some null values in the date field. These workbooks use an extract data source. After reading the Help documentation on the issue, and looking at the underlying data, they understand that this field has some trailing characters such as “midnight,” which is causing the problem. They fix the underlying data and the issue is resolved. Sarah makes a note in her upgrade checklist to fix this issue in their production environment before upgrade.
Based on her testing, Sarah creates and documents a plan to upgrade her production environment and prepares the communications she needs to send out to her company.
Key takeaways
After reading thus far, you may have some questions on Tableau Server 10.5 upgrade. Here are some common questions you might be thinking of:
How has the configuration of Data Engine and File Store changed in 10.5?
In versions prior to 10.5, you selected Data Engine process to be installed on a node and File Store was installed automatically along with the Data Engine process. In 10.5, the configuration is reversed. You can select where to install File Store process, and the associated single instance of Data Engine process is installed on the node(s) where File Store is installed.
Since Data Engine is now automatically installed with other server components, on multi-node installations, how are the data engines used?
The instance of the Data Engine process installed on the node where File Store is also installed is used for querying data for view requests.
The instance of Data Engine installed on the node where Backgrounder is installed is used for extract creation and refreshes.
Data Server, VizQL Server, and the Application server (VizPortal) use the local instance of Data Engine to do cross-database joins and create shadow extracts.
In multi-node installation, this blog post described a use case about changes to views (e.g., nulls in the date field). Are there more such issues? Where can I find out more information about this?
After an extract has been upgraded, you might notice some changes to a view that uses the extract data source. This is because values in your extract can be computed differently in version 10.5. Changes can include fewer marks in the view, more null values when you inspect the summary data, or the view itself has a different shape. In some rare cases, the view might even be blank. These changes also apply to live connections to Excel, text, and Google Sheets file data. For more information about the type of changes you might see when interacting with extracts with this version of Tableau, see Changes to values and marks in the view.
Related Stories
What is Tableau Prep?
 April 30, 2026
April 30, 2026
Insights Wherever You Work: Meet the Tableau App for Microsoft 365
 March 16, 2026
March 16, 2026
What is Tableau Next?
 March 12, 2026
March 12, 2026