Use an LOD Expression to Conquer Database Cardinality Issues




For many years, data users, whether they knew it or not, have struggled with database cardinality issues. I am excited to share a simple solution to this challenge.
Those of you who've tried your hand at table joins within or outside of Tableau likely found that some joining scenarios leave you with incorrect sums. This occurs because the numbers in one of the joined tables, such as quota or budget, have been duplicated in the resulting table. After the join, when you take the sum of quota or budget, the number appears to be way bigger than expected.
If the data set is of a manageable size, you may notice the incorrect numbers immediately. But in many cases, we may overlook the problem and unknowingly work with incorrect numbers. This is a topic of cardinality, specifically a one-to-many relationship between tables.
To better understand the problem and how it may apply to you, let’s take a look at an example of quota attainment.
The Problem
In this scenario, each salesperson makes many sales and has a single quota to reach. Sales numbers are stored in one table and the quota is stored in a second table. We can link these tables in a join via the salesperson’s name to find out who has reached quota.
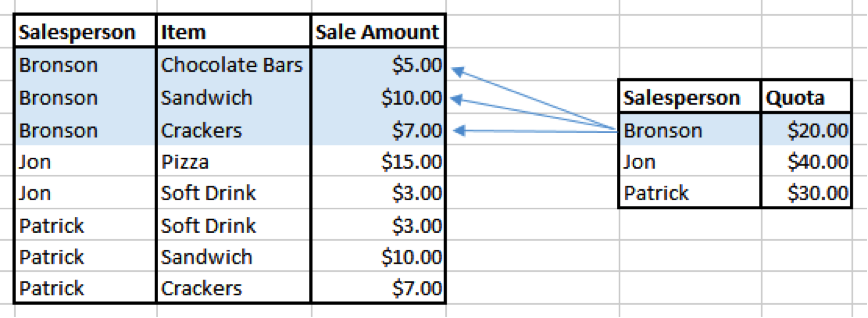
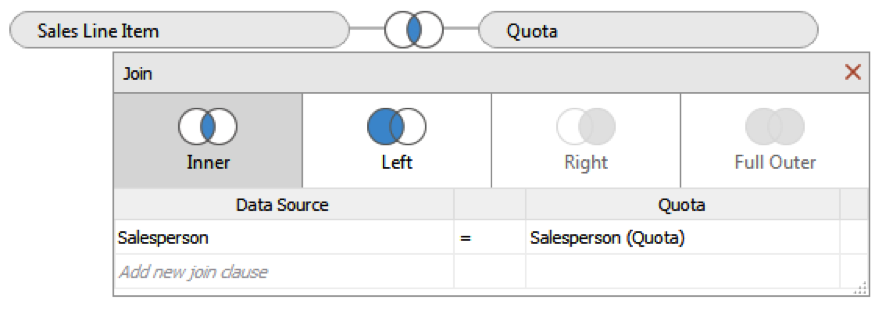
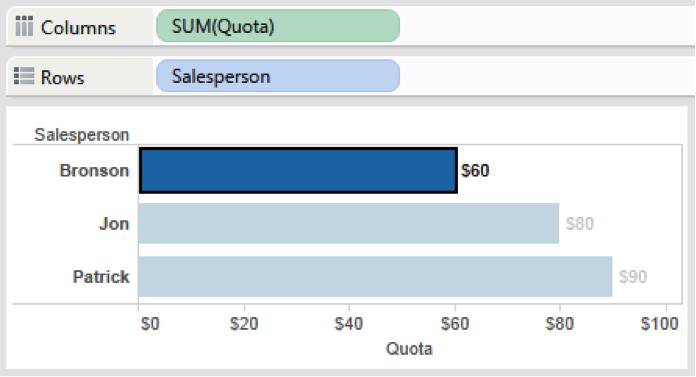
Notice that the data from the quota table will be replicated three times for Bronson when it is joined to the sales data. This is where our problem begins. Bronson’s quota of $20 is now repeated three times. And when we take the sum of quota for Bronson, it will show $20 x 3 = $60, which is clearly incorrect.
The Solution + Two Options to Avoid
So the challenge is clear, but how do we solve for it? You might consider data blending, or taking the minimum quota figure instead of the sum. Both of these options have caveats, however. Data blending can perform poorly on larger data sets. And taking the minimum quota figure relies on having the salesperson dimension in the view.
This brings us to our solution: using a Level of Detail Expression.
This approach is scalable, dynamic, and reusable. Since the quota is always replicated across the salesperson dimension, we can fix the level of detail to the salesperson and always take the minimum quota:
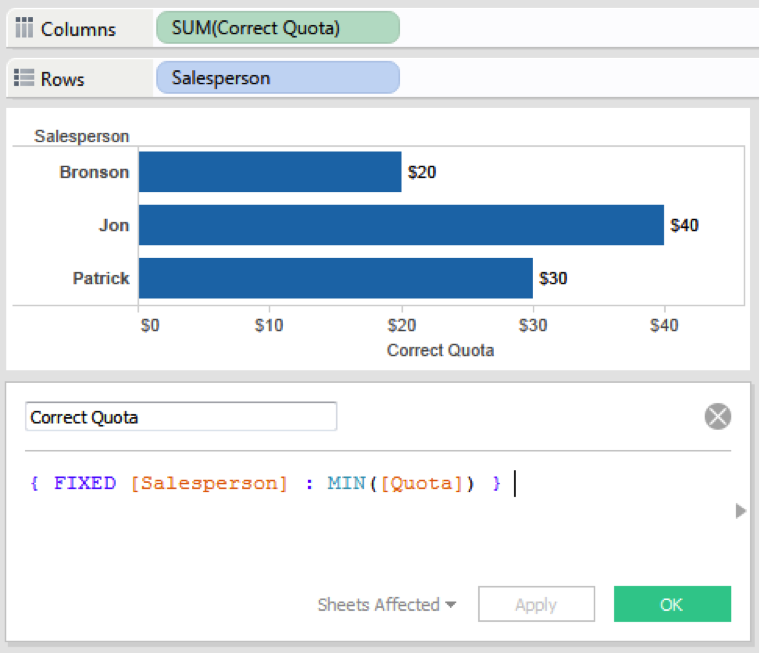
This calculation will give the correct value, whether we are looking at the view by salesperson or by total quota.
While this is one example, the application of this simple LOD Expression is vast. At Tableau, we use this across many of our data sources not only to improve performance, but also to ensure that others don’t fall victim to using incorrect numbers in their own analysis. I recommend changing the name of the duplicated metric to “incorrect value” and naming the LOD version “correct value” to ensure people use the right one.