How we translate millions of words to localize Tableau into over 10 languages



Our mission
Our mission on the Tableau Product Internationalization Engineering Team is to help people around the world see and understand data in their own language and culture. We are tasked with localizing all of our products and all of the Tableau Help content into 11 different languages and growing.
Writing localizable code
It is very difficult and expensive to translate strings that are directly embedded in source code files. Therefore, developers must avoid hard-coding strings by isolating all text into localizable string resource files.
For example, if a developer is adding a new navigation option in Tableau Server called “Shared with Me”, they should not hardcode the English term directly in the source code like this:name="Shared with Me"
Instead, the developer adds the English (US) source string to a localizable string resource file with a unique string ID. In this example, the string lives in a file called en_US.json:

In the source code, the developer calls the string by the string ID, for example:name={Messages.navigation_sharedWithMe()}
At runtime, the “Shared with Me” string appears in the navigation pane like this:
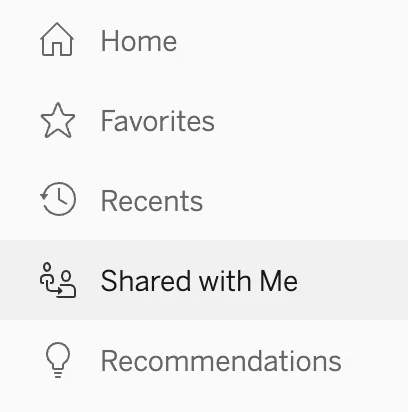
The en_US.json string resource file is then translated into all supported languages. For example, the German strings in this example live in a file called de_DE.json:

Now, when the Tableau Server User Account Language is set to German, the “Shared with Me” and other navigation options appear in German:
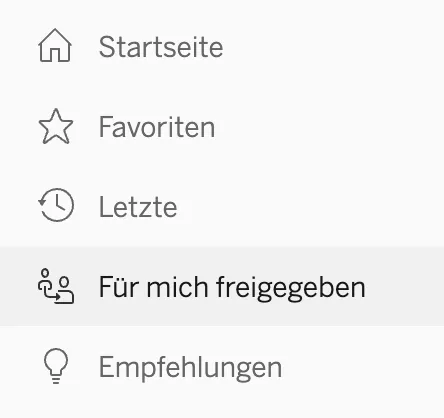
This process seems pretty simple so far. All of the English strings live in a string resource file called en_US.json and all we have to do is translate those strings in language specific files (de_DE.json, ja_JP.json, etc.) in all supported languages and submit our changes for the localized strings to appear when the customer changes their Tableau language preferences.
However, there are hundreds of string resource files called en_US.json scattered across hundreds of GitLab source code projects. Furthermore, Tableau products run on Windows, macOS, Linux, iOS, Android, and in the browser. For flexibility and scalability, the code is developed in various programming languages such as C++, Java, etc. Each programming language has its own file extension for the localizable string resource files, including: *.json, *.resx, *.html, *.xml, *.wxl, *.properties, *.data, *.strings, and many others. Every resource file type has a different file format that we need to create parsers for. For example:



To top that off, Tableau source code lives in multiple source code repositories including GitLab, GitHub, and Perforce. We not only need to create parsers to handle all of the various file formats, but we need a way to keep track when new strings are added, removed, or edited in existing string resource files and when new string resource files are created in the various source code repositories. We also need a way to collect all of the strings and hand them off to our translation vendor. And we need a way to merge all of the localized string files back into the various source code repositories.
Centralized String Repository
Our solution to this problem was to create a centralized string repository to process and store all of the strings from various source code repositories, programming languages, and file formats. The centralized string repository is accompanied by a number of string repository scripts that are deployed using various CI/CD pipelines to facilitate the flow of hundreds of individual modules to the central string repository database. As Tableau embraced modularization, this was needed to support the growing organization.
The centralized string repository database contains a separate folder for each individual source code module. Under each of those module folders, we include a JSON file (xx_XX.json) for every language that that we support, plus a couple of extra “pseudo” languages that we use for testing purposes only.
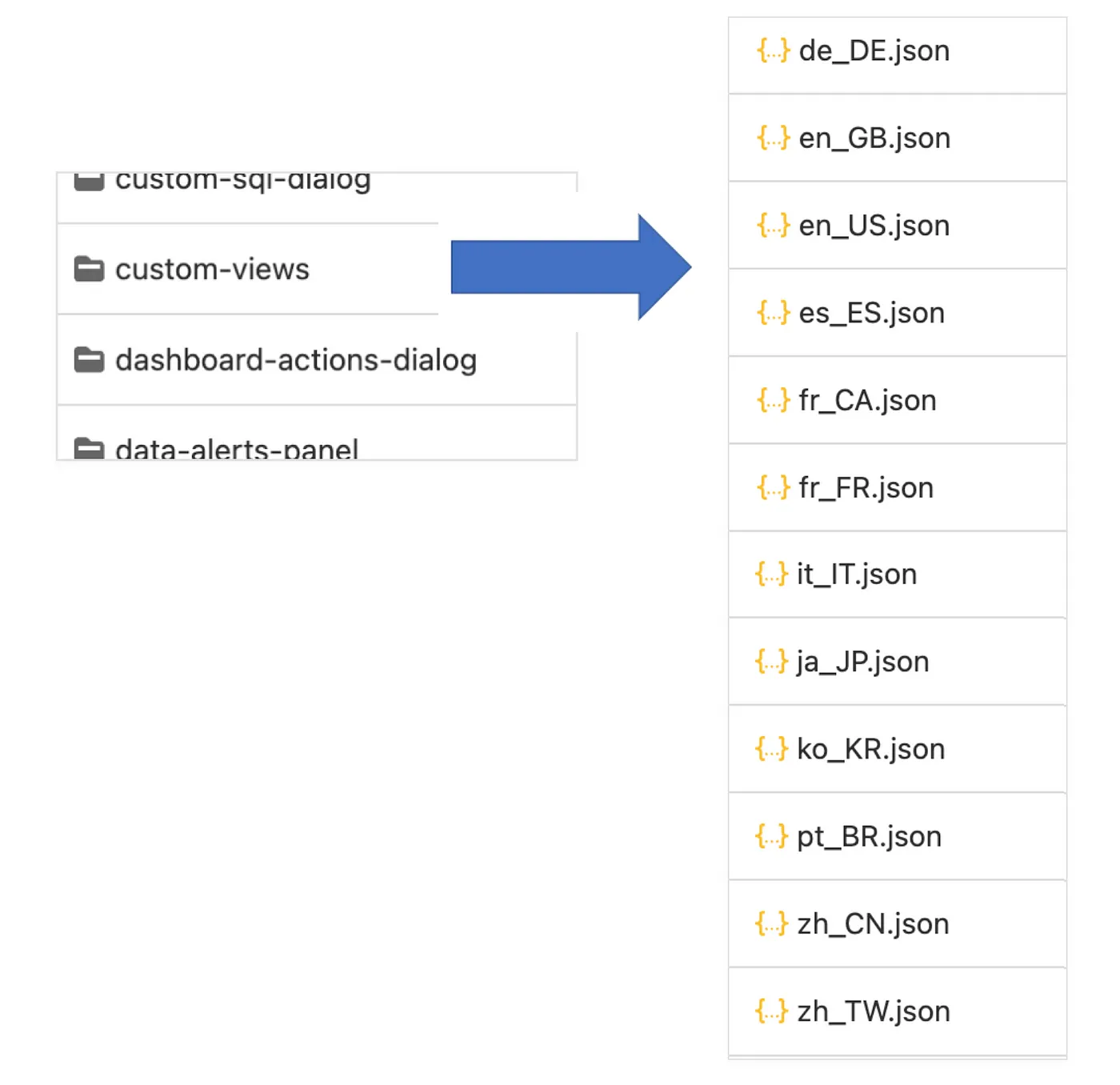
The structure of the centralized string repository JSON schema is the same across all string resource file types and all languages. We specify the schema version, the module name (source code location), and the language of the strings in the file. We parse out the string ID, the text, and the optional developer comments from the original source code string resource file. Each string is added as an individual record in the centralized string repository JSON file for that module. Each string record includes the string ID, the text to be translated, the status (“new”, “pending”, or “translated”), a timestamp to indicate when we last updated the string in the file, and the developer comment associated with the string (if available).
{
"schemaVersion": "2.0.0",
"moduleName": "@tableau/[moduleName]",
"language": "en_US",
"records": [
{"id": "[string_ID]",
"message": "[English (US) source string]",
"status": "[new/translated/pending]",
"updated": "[time_stamp]"
"comment": "[Optional developer comment to the translators]"
},
For example, the record for the “Shared with Me” string looks like this:

We developed another library that developers must import into their projects in order for our localization automation to detect changes to their string resource files. They must also include a configuration in their project that specifies the path to their localizable string resource files and they must grant permissions to our team service account to access their source code repositories. Another automated script runs nightly that connects to every source code repository and pulls down all of the new and updated strings and merges them into the centralized string repository. New strings are inserted as new records into the corresponding en_US.json files in the centralized string repository. The status is set to “new” or “pending” and the timestamp in the ”updated“ field in the record is updated to the time that the changes were merged into our centralized string repository.
Translation Process and Tools
Our strings are not translated in-house. We contract with a Localization Services Provider (LSP) that employs native speaker translators located in each of our target markets. We use a popular cloud-based Translation Management System (TMS) to create localization jobs to share with our LSP vendor. Every 2 weeks, a scheduled automated script runs which pulls all of the latest versions of the English source strings from centralized string repository into a new localization project in the TMS and alerts our LSP vendor to begin translation. The localization project contains separate jobs for each language. The vendor then assigns each language-specific job to their translators.
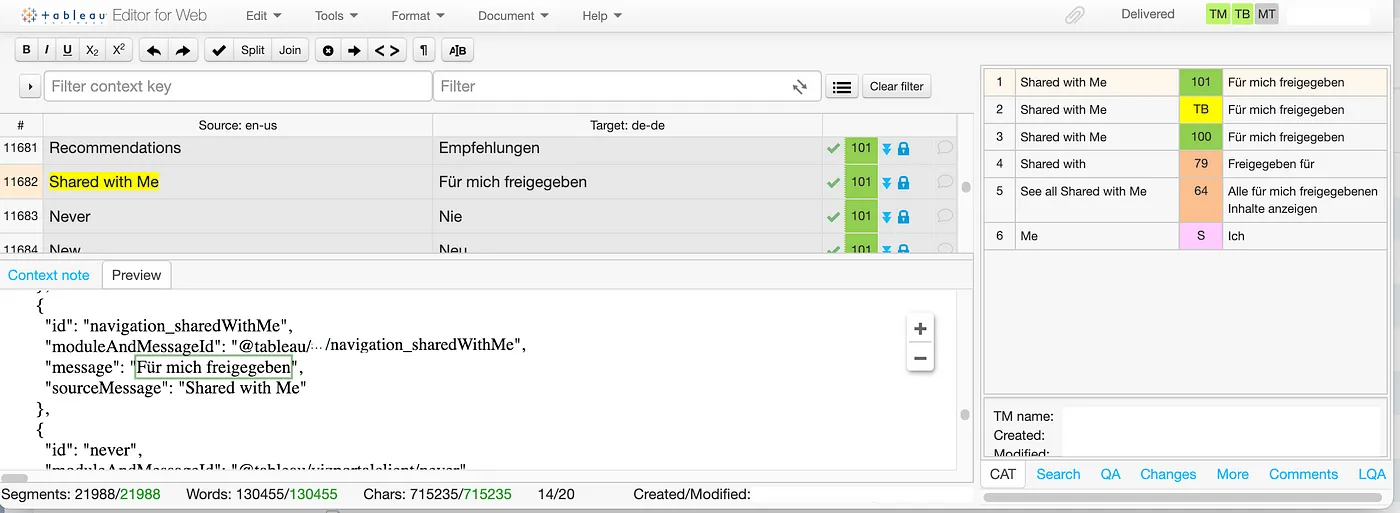
Translation Management Systems (TMS) are powerful tools to help with efficient and quality translations. We use Translation Memory (TM) to recycle existing translations for existing identical strings to ensure translation consistency across our products. We create rules and regular expression keywords to identify terms that should not be translated, such as product names like “Tableau Desktop”, placeholders, HTML tags, and other formatters. We utilize Term Bases (TB) to store Tableau jargon, feature names, and other terms that we want to make sure to translate consistently. The TMS informs the translator when terms should not be translated or when they should be translated using an approved term from the Term Base. The TMS also includes quality assurance tools to validate a variety of common translation mistakes including, typos, inconsistent translations, terms which differ from the suggestion in Term Base, inconsistent punctuation, missing placeholders, etc.
The TMS indicates which translations have been fully translated and approved. The translator can filter the content to display only new and updated strings. They typically do not retranslate any strings that have already been signed off except to fix translation defects. The TMS also includes a way to preview how the strings will look in the target file. In our case, the preview is how the localized file will be formatted in the .json file in our centralized string repository.
Putting it all back together again
Typically, it takes our Language Services Provider (LSP) vendor one week to fully translate all new and updated strings in all languages. Once the vendor hands back the updated files through the TMS tool, we run various automated scripts to process and validate the files before they are submitted.
Once all validation tests have passed, automation runs that merges all new and updated strings into our centralized strings repository. The status is updated to “pending” and the timestamp is updated to match the time of the merge request. For example:

Another automated script runs that updates the target localized files with the new and updated strings. Validation checks are run to make sure that we have formatted and encoded the files correctly and to make sure that we have not over-translated any placeholders. If the validation checks succeeds, then our automation sends a merge request to each source code repository.

Once the changes are merged, then the new translations appear in the next pre-release build of the product.
Quality Assurance Measures
Our translations and product builds undergo a variety of quality checks to verify linguistic quality and functionality, including the following:
Localization Freeze
- To ensure that we release fully localized software, we set a “Localization Freeze” milestone on every release calendar which is the last date that developers are permitted to make changes to their English (US) strings. Any changes to strings after that date need special approval before they can be made to avoid risk of not being translated in time for the release.
File Format Validation
- Various file format validation test are run against the files during the hand back processing to ensure that files are formatted and encoded properly.
Merge Request Auditing
- Any errors that are generated when merge requests are created are sent to a monitored Slack channel for quick resolution.
- Automated auditing of un-merged requests notify affected teams when they have pending merge requests that are older than 2 weeks. Engineering teams have the ability to configure how they want to be notified (via email or Slack) when they have un-merged requests.
LSP Quality Checks
- Our Language Services Provider (LSP) runs a variety of validation checks before handing back the translations to us.
- The translation tool includes various built-in validation checks, including: spell checkers, grammar checkers, punctuation checkers, verification that all strings have been translated, verification that the suggested terms from the Term Base were used, etc.
- The Language Service Provider (LSP) runs regular reviews of the translations to check for linguistic accuracy. They also periodically review the terms in our terminology database for linguistic accuracy.
Geopolitical Reviews
- Every quarter, we send a batch of string files to an external consultant who reviews the English and translated terms for geopolitical and cultural sensitivity issues and to make sure that we are using inclusive language.
Pseudo-Localization
- Nightly pseudo-localization builds are generated that creates a fake language for testing purposes so engineers and test automation can validate localizability of our products without waiting for the fully localized strings to be handed back from the Language Service Provider (LSP).
- We add a unique string ID to help us identify the location of the string in our numerous string resource files for faster defect fixes.
- The string ID also lengthens the string to help us verify that the text will not be truncated after translation.
- We append delimiter characters around the string to help us identify the end of the string to spot potential truncation issues.
- We replace some of the English letters with non-English characters to help validate encoding and garbage character issues. But the text is still legible to English speaking engineers.
- The “Shared with Me” example above looks like this in our pseudo-localized internal testing builds:

Automated and Manual Testing
- In-house test automation is run regularly in all languages to verify functionality of our products with localized user interface.
- Multiple times during each release, we send the Tableau product pre-release builds to our translation test vendor to run manual test passes of the localized product UI on localized operating systems. These test passes uncover untranslated strings, truncation, overlapping, functionality issues, etc.
- During both manual and automated test passes, we capture screenshots of the localized user interface. These screenshots are then sent to our native speaker translators so they can see their translations in context. They compare the localized screenshots side-by-side to the corresponding English (US) screenshots to check for linguistic accuracy and consistency.
Tableau Language Quality Game
- At the end of every Tableau product release, we upload all of the latest product UI screenshots that we captured into an internal tool that we call the “Tableau Language Quality Game”.
- We invite native speaker Tableau employees around the globe to participate in the game for a chance to win prizes. They review the localized and English (US) screenshots side-by-side to help us identify any translation issues we may have missed during all of our other quality efforts.
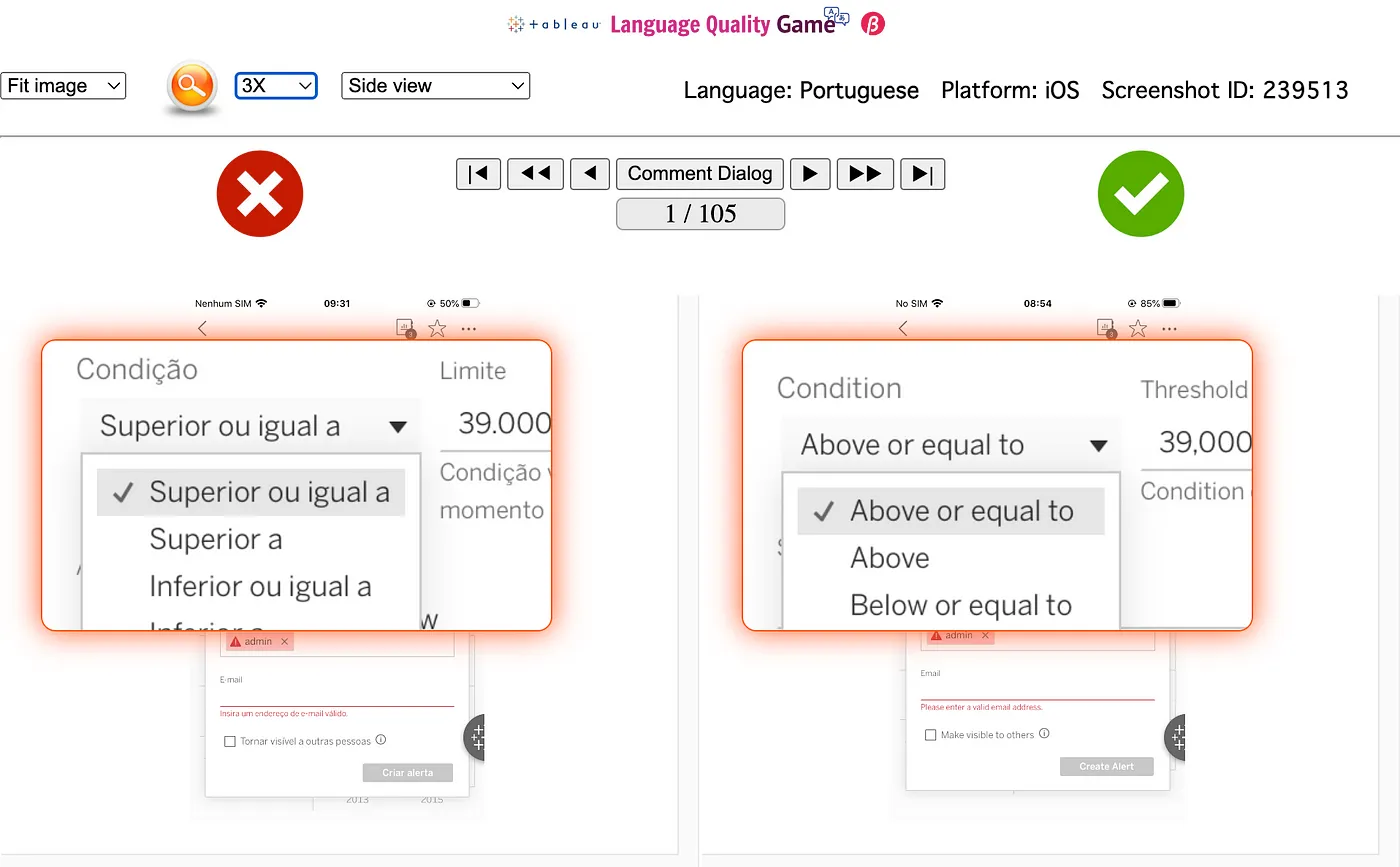
We try our best to translate our products fully and with the most accurate terminology. But sometimes bad translations slip through. For blocking issues, we ask customers to contact Support. For less urgent questions and suggestions, we love to hear from our customers in our Tableau Internationalization Community.
Summary
Developers across Tableau are continuously making product improvements and developing new features. Many strings are updated, added, or removed daily. Our automation runs nightly to pick up their changes and merges them into our centralized string repository.
Every 2 weeks, our automation prepares the latest English source strings to be handed off to the localization vendor (LSP). The translators typically take 1 week to translate all new and updated strings. After the vendor hands back the completed translations, our automation gets the updates from the Translation Management System (TMS) and updates the records in centralized string repository. Then the changes are merged back into their respective source code repositories and modules.
This cycle of localization hand offs and hand backs repeats continuously, so we call it the “Localization Train” or “Loc Train” for short. The Loc Train never stops and stays on a mostly consistent schedule.
The “Loc Train“ process for our Tableau Help content is very similar, except that we use a different Translation Management System (TMS) tool and translation schedule. All of the Help content lives in a single source code repository and there are fewer file formats to parse and translate. However, the amount of content to translate is extremely large.
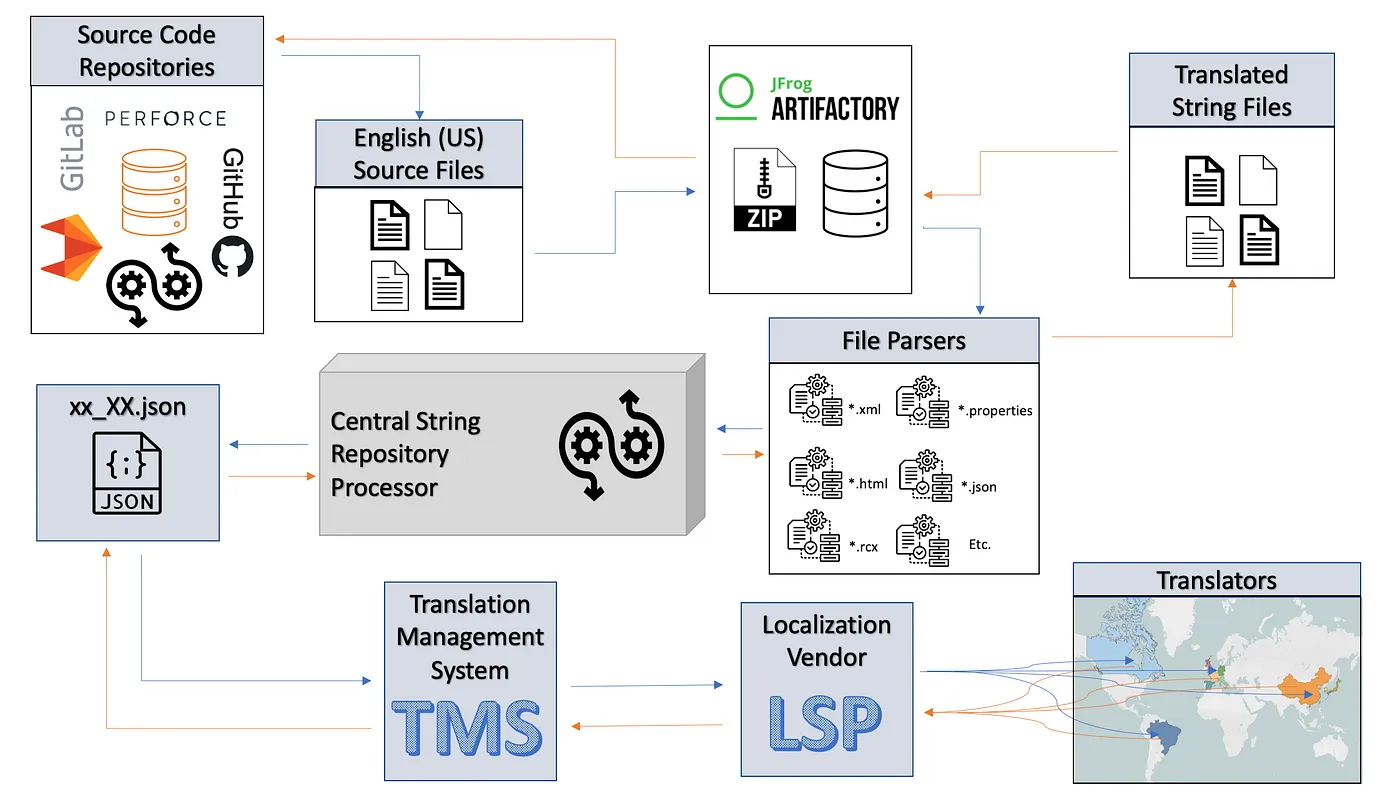
The whole “Loc Train” process looks like this:
- The English (US) source string are pulled from the source code repository.
- A snapshot of the latest English (US) files are packaged up and stored in our artifactory.
- The localizable strings are parsed from each source file into a single en_US.json file.
- A new localization job is created for each language using our Translation Management System (TMS)
- The Language Services Provider picks up the jobs from the Translation Management System (TMS) and assigns the jobs to translators across the globe.
- The translators use the TMS tool to translate the strings and the vendor alerts us when they are ready for hand back.
- The localized strings are parsed from the .json files and the target localized files are created.
- The localized files are zipped up and stored into our artifactory and validation is ran against the files.
- The localized files are pushed to each source code repository and merge requests are created.
- Once the changes are merged successfully, the localized strings will be displayed in the next build and the “status” field in centralized string repository is set to “translated”.
- Quality assurance is an ongoing part of the process that happens at various stops along the “Loc Train” route.
Related stories

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 14 April, 2026
14 April, 2026
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 10 April, 2026
10 April, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 8 June, 2025
8 June, 2025