Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics




Tableau Research presents Lexara, a user-centered evaluation toolkit for Conversational Visual Analytics (CVA). This research was conducted by Srishti Palani and Vidya Setlur at Tableau Research. This work was presented at the ACM CHI Conference on Human Factors in Computing Systems, the premier venue for research in human-computer interaction.
As Large Language Models (LLMs) become the backbone of conversational data analysis tools, a pressing question emerges for the teams building them: which model and prompt combination actually works best for your users and your data? Today, answering that question requires cobbling together spreadsheets, writing custom scripts, and manually inspecting outputs across models and apps, a process that is fragmented, inaccessible to non-engineers, and poorly suited to the nuanced, multi-format outputs that conversational analytics systems produce.
The evaluation gap in conversational visual analytics
Conversational Visual Analytics tools let users generate and refine visualizations through natural language. But evaluating the LLMs powering these tools is surprisingly difficult. Existing benchmarks rely on synthetically generated test cases that don't reflect how people actually talk to their data. Traditional NLP metrics like BLEU, ROUGE, Precision, Recall, and F1 reduce rich, multi-format outputs (charts, specifications, and natural language explanations) to simple n-gram overlaps. And running evaluations typically requires programming expertise, shutting out product managers, designers, and other key stakeholders.
Through interviews with 22 CVA tool developers and observational sessions with 16 end-user analysts, we uncovered a consistent pattern: practitioners care deeply about evaluation but lack the tools to do it well. They want to know not just whether a chart is "correct," but whether the right fields were selected, whether axes are properly oriented, whether filters carried over from a previous turn, and whether the accompanying explanation is grounded in what the visualization actually shows.
What is Lexara?
Lexara is an evaluation toolkit that operationalizes these practitioner insights into three components.
Real-world test cases. Rather than synthetic queries, Lexara's test suite is derived from logged interactions with actual data analysts. These test cases capture the complexity of real CVA usage (ambiguous field references, multi-turn context carryover, and diverse chart types) annotated with expected outputs and labels for common challenges.
Interpretable, graded metrics. Lexara introduces metrics that mirror how practitioners actually judge CVA outputs, organized across visualization quality (data fidelity, field similarity, chart type, axis accuracy, filter and sort correctness, visual encodings, interactivity) and natural language response quality (factual grounding, assumptions disclosure, insightfulness, coherence, follow-up relevance). Crucially, these metrics support partial credit—a chart with swapped axes isn't a total failure, and Lexara's scores reflect that.
An interactive, low-code evaluation tool. Lexara's interface lets practitioners upload their own data and test cases, configure model-prompt combinations, and explore results at multiple levels of granularity—all without writing code. Side-by-side comparisons of rendered visualizations, JSON specification diffs, and hierarchical metric drilldowns make it easy to diagnose why one configuration outperforms another.
How practitioners evaluate: beyond binary correctness
A key insight from our formative studies is that CVA evaluation is inherently graded. A response may be technically valid but still suboptimal—a pie chart where a bar chart would be clearer, a field labeled Billing_Timestamp_HFD correctly mapped from a user's mention of "date," or a natural language explanation that restates the query without offering any analytical depth.
Lexara's metrics capture these distinctions. For example, the Field Similarity metric uses stemmed cosine similarity with data-type bonuses to score how well selected fields match user intent, even when exact names differ. The Chart Type metric leverages Tableau's Show Me recommendations to assess whether the chosen visualization is optimal, acceptable, or inappropriate for the given data fields. And LLM-as-a-Judge metrics for dimensions like insightfulness and coherence are grounded in few-shot examples drawn directly from end-user ratings during our formative study.
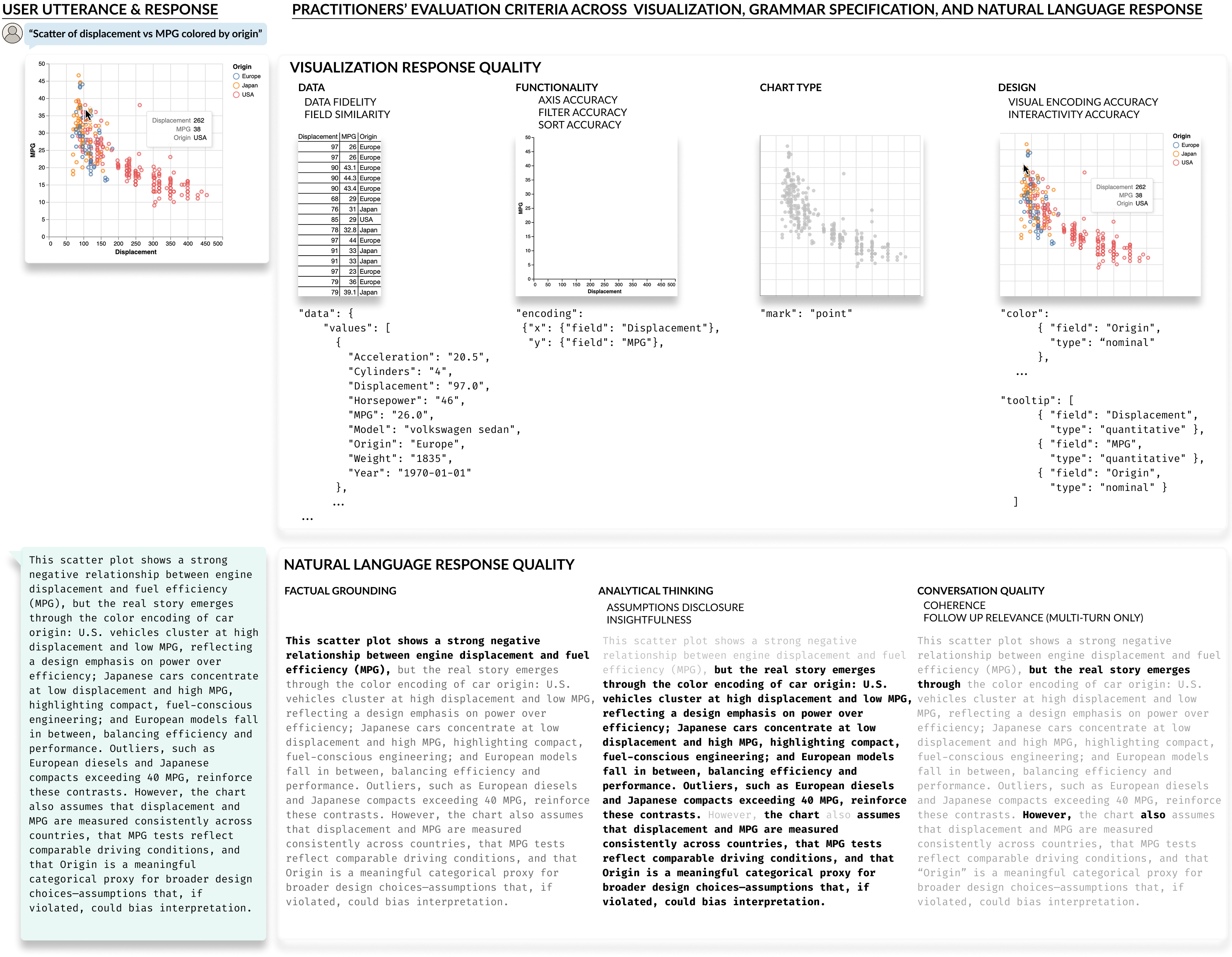
Figure 1: Practitioners evaluate CVA responses across multiple formats and dimensions: visualization quality (data fidelity, chart type, functionality, design) assessed through both rendered charts and grammar specifications, and natural language quality (factual grounding, analytical thinking, conversation coherence); These criteria are what Lexara operationalizes into interpretable, graded metrics.
What we learned from a field deployment of this evaluation toolkit
We deployed Lexara with six CVA tool developers in a two-week diary study. Participants ran 38 evaluation experiments across 57 test cases, comparing 10 LLMs and 6 system prompts. Their workflows revealed how Lexara supported real evaluation needs:
- Diagnosing model behavior. One participant initially tested a compact model but noticed misaligned encodings through Lexara's JSON diff viewer, prompting a switch to a different model family with measurably better results.
- Comparing prompt strategies. Participants tested persona-prompting, few-shot examples, and even prompts in different languages, using Lexara's side-by-side views to trace how prompt variations affected chart accuracy and explanation quality.
- Making metrics actionable. The hierarchical drilldown—from an overall visualization score down to specific sub-metrics like sort accuracy or visual encoding—helped participants connect high-level performance to concrete output differences.
Participants valued the graded nature of the metrics, noting that "accuracy isn't just yes or no, sometimes it's close enough to be useful; other times a valid-looking chart is misleading." The toolkit's interpretability was also highlighted: hovering over scores revealed exactly what differed between expected and actual outputs, transforming opaque numbers into actionable diagnostic insights.
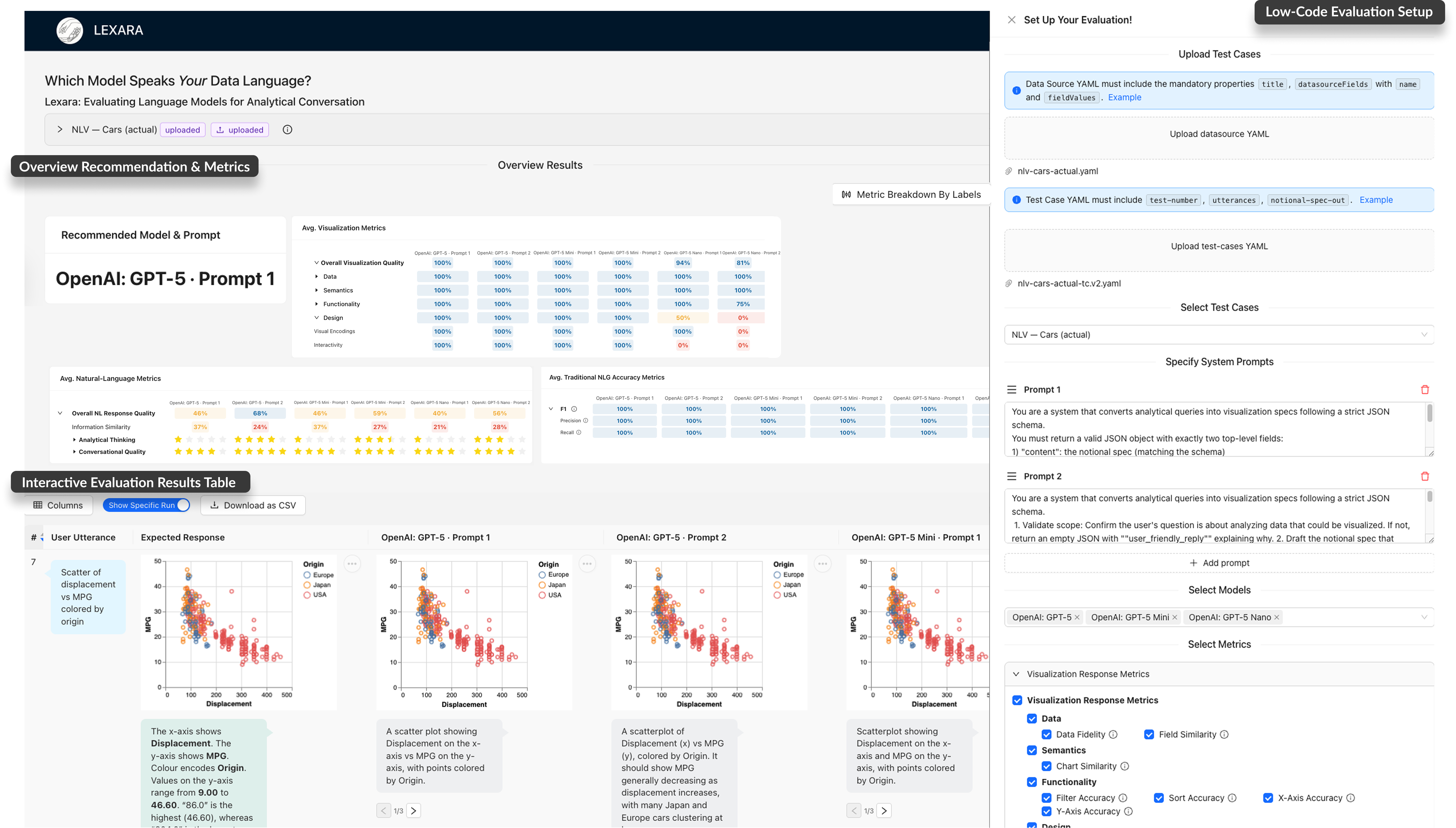
Figure 2: Lexara’s interactive CVA evaluation interface supports two core workflows: (1) an Evaluation Setup Panel for configuring data, test cases, models, and metrics; and (2) an Interactive Results Table for viewing side-by-side model outputs (visualizations, specs, natural language) with tools for multi-granular inspection and tracing divergences.
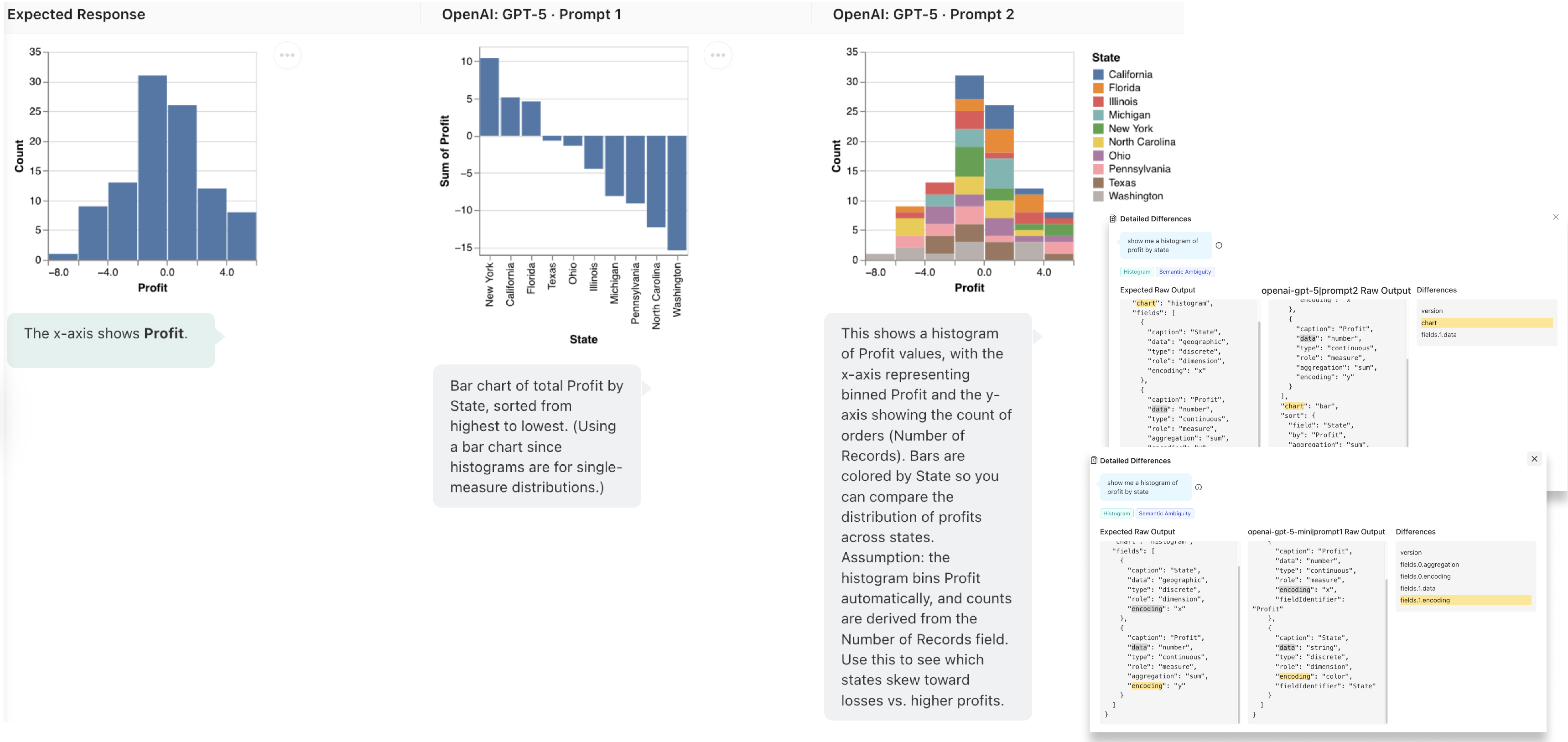
Figure 3: For each test case, Lexara aligns expected and actual outputs across rendered visualizations, natural language explanations, and JSON specifications, enabling practitioners to pinpoint exactly where and why model outputs diverge.
Figure 4: Lexara surfaces evaluation results at multiple levels: a recommended model–prompt pair with aggregated metrics (top left), performance breakdowns by chart type, ambiguity class, and context-handling (top right), and utterance-level comparisons of expected vs. actual outputs with detailed metric explanations (bottom).
Validating the metrics
To ensure Lexara's metrics align with expert judgment, we conducted a validation study with 120 CVA responses rated by two human evaluators. Most metrics showed moderate to high inter-rater reliability (median Cohen's κ = 0.63–0.65) and strong correlation with human ratings (Spearman's ρ up to 0.82 for factual grounding). At the model level, Lexara's scores tracked practitioners' qualitative preferences with rank correlations of ρ = 0.79 for visualization quality and ρ = 0.74 for natural language response quality.
Why this matters
As the ecosystem of LLMs continues to evolve rapidly, CVA tool teams face constant decisions about which models to adopt, which prompts to deploy, and how to maintain quality as systems scale. Lexara addresses this by making evaluation systematic, interpretable, and accessible—not just for engineers, but for the full range of stakeholders involved in building and shipping conversational analytics products.
Beyond being a toolkit, Lexara also contributes a framework for thinking about CVA evaluation: one that embraces graded correctness, accommodates multiple valid answers, and bridges the gap between automated metrics and human judgment through a hybrid human-AI evaluation approach.
The toolkit is publicly available at lexara-6b38293fcdac.herokuapp.com with open-source code to support broader adoption and experimentation within the CVA research and practitioner communities.
Interested in exploring our work on human-AI data analysis? Visit the Tableau Research website to check out the Lexara paper and our latest work on navigating analytical conversations with SyncSense.
Want to see these ideas in action? Join Srishti Palani and Ewald Hofman at the Tableau Conference 2026 for their session, Verify Your AI: The Analyst's Guide to Trust and Quality — where they'll share practical guidelines and design patterns for catching errors, validating insights, and using AI with confidence.
Related stories
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 10 April, 2026
10 April, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 8 June, 2025
8 June, 2025
Visualize, Narrate, Repeat: Closing the Loop on Data Storytelling
 2 June, 2025
2 June, 2025