How Databricks and Tableau customers are fueling innovation with data lakehouse architecture





In many of the conversations we have with IT and business leaders, there is a sense of frustration about the speed of time-to-value for big data and data science projects. We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machine learning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and data lakes feel cumbersome and data pipelines just aren't agile enough. This inertia is stifling innovation and preventing data-driven decision-making to take root.
A growing number of organizations have moved to a lakehouse architecture to simplify their data landscape. In a recent Databricks study we found that 23% of organizations surveyed were already looking to transition to this approach—potentially signalling a significant technology disruption.
Here we’ll look at why this shift to a modern lakehouse architecture will deliver integrated data solutions more swiftly for all users, with any data. We’ll also explore the technical synergy between Tableau and Databricks and how our customers typically use the two platforms together to maximize the value of their data.
The division between data lakes and data warehouses is stifling innovation
Nearly three-quarters of the organizations surveyed in the previously mentioned Databricks study split their cloud data landscape into two layers: a data lake and a data warehouse.
A data lake is typically the landing place for unstructured and semi-structured data, also known as the raw layer. This raw data often goes through a number of transformation steps: clean and prepare, apply business rules, feature engineering, classification, scoring, and so on.
Aggregated results are then pulled into a data warehouse, or semantic layer, where business users can interact with the data using business intelligence tools.
This separation was necessary in the past as the data lake was designed for high throughput but couldn't scale to the high concurrency requirements of all line-of-business users. In contrast, data warehouses provided great concurrency and caching but were not suitable and cost-prohibitive for the raw layer of unstructured and semi-structured data.
However, this division between data lakes and warehouses creates technical and organizational barriers that slow innovation. For example, if a business user is exploring an aggregated data set within the data warehouse and discovers the need for additional data features or a different level of detail, it can take some time to update the data processing pipeline. Many businesses also want to include machine learning models in their visualizations—that are typically trained and built in the data lake.
Due to these limitations, organizations are looking for ways to "flatten" the data landscape—and vendors are responding by creating data platforms that combine the best of both worlds. One such approach is the lakehouse architecture model.
Tech innovations that enable the data lakehouse
A data lakehouse is a new, open paradigm that combines the best elements of data lakes and data warehouses. Lakehouses are enabled by a standardized and open system-design: Their architecture implements data structures and data management features similar to those in a data warehouse, directly on the types of low-cost storage used for data lakes.
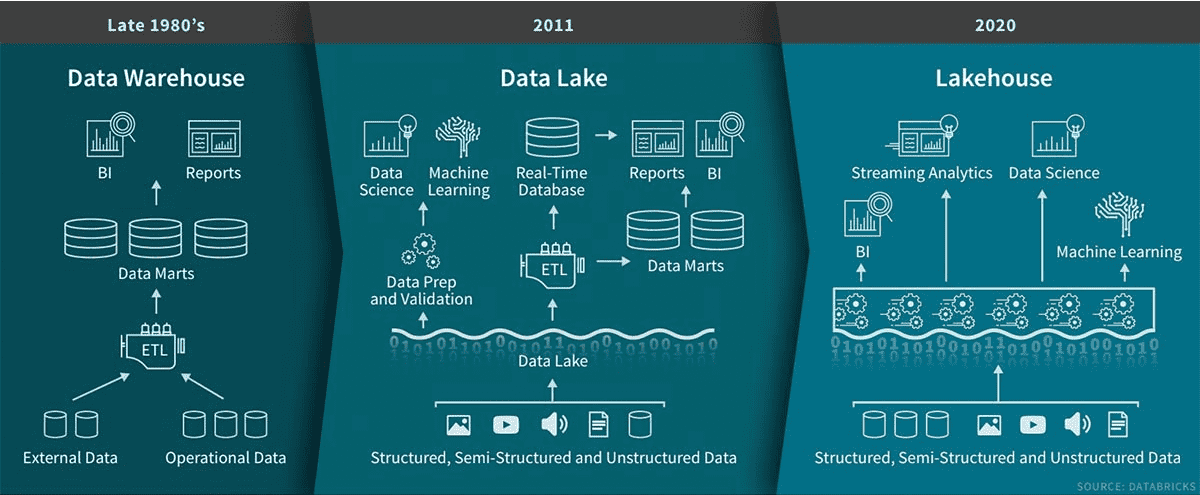
The evolution of data storage over time, via Databricks.
The lakehouse model provides distinct advantages for Tableau customers. It offers support for:
- All types of data used in modern analytics, including structured data, semi-structured data (such as logs and IoT data), and unstructured data (like images and videos)
- Real-time streaming and batch data. Streaming data is a perfect example of the type of data that needs to land in a data lake for storage. For quick access, organizations want to access that data immediately from the data lake
- SQL access, providing SQL users with instant access to the wide breadth of data within a data lake for analysis
We’ve already seen a number of joint Databricks and Tableau customers implement a lakehouse architecture, including Wehkamp, The US Air Force, and Kabbage. The strong technical synergy between our platforms simplifies the transition to this modern architecture:
- Performance: Delta Lake technology from Databricks provides high performance and reliability, readying the data lake for a wide range of analytical use cases—from data science and AI using Databricks to self-service analytics with Tableau.
- Concurrency: Our customers are starting to use Databricks SQL Analytics endpoints to run SQL- and BI-optimized compute clusters within a Databricks lakehouse. Early results indicate that this offers more concurrency through automatic load balancing, caching, query optimization, and the new Photon native vectorized engine.
- Extract or live connection: The hybrid data architecture in Tableau provides two modes for interacting with data in the lakehouse—via a live connection or an in-memory extract—easily switching between the two with a toggle in the browser. The two modes make it much simpler to shift to a lakehouse architecture: Connect live to massive volumes of data when conducting high throughput ad-hoc explorations and transition without disruption to in-memory access if an aggregated data set supporting a mission-critical dashboard needs massive concurrency.
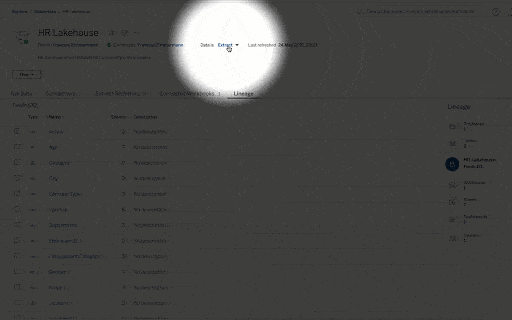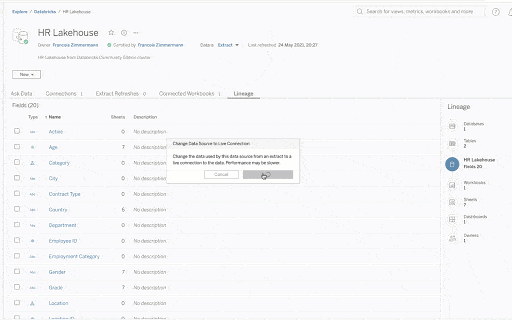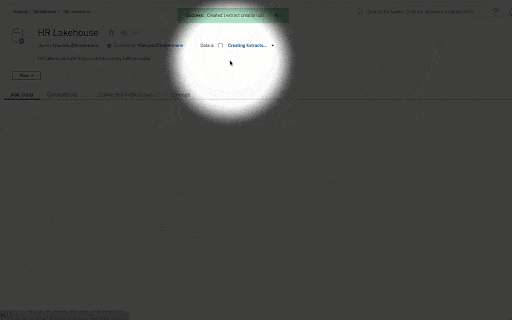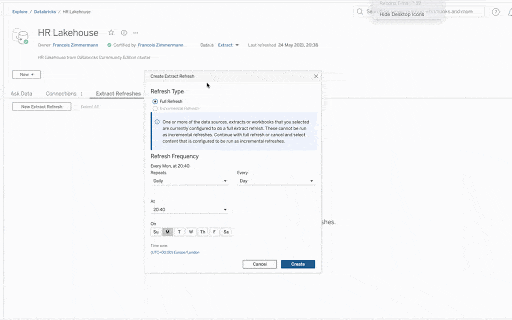
Empower all business users with a data lakehouse
A lakehouse has the most impact when every line-of-business user can self-serve insights. The Tableau platform focuses on bringing all your data assets from the lakehouse to empower users across the organization. Here’s how:
- Tableau and Databricks enable data stewards to model and curate the data and establish lineage and governance.
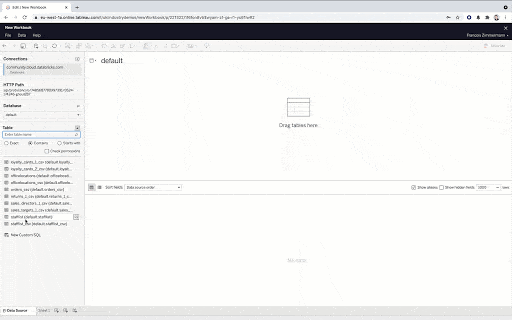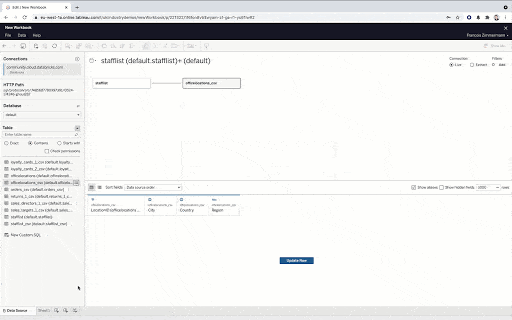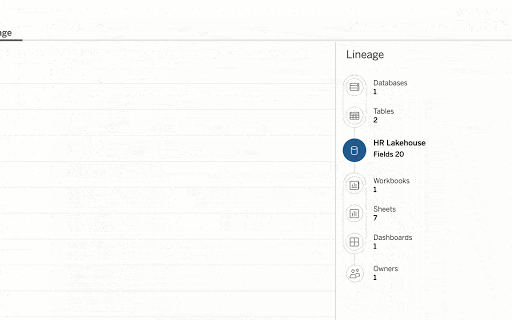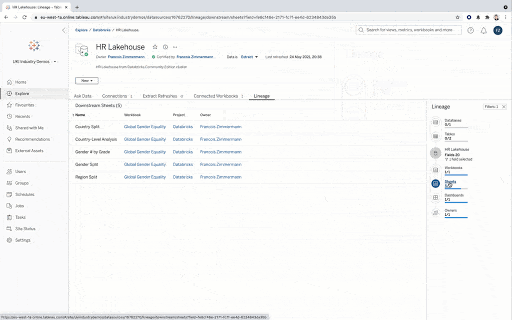
- Data consumers can discover assets with search and recommendations and explore data with visual, natural language, and augmented analytics.
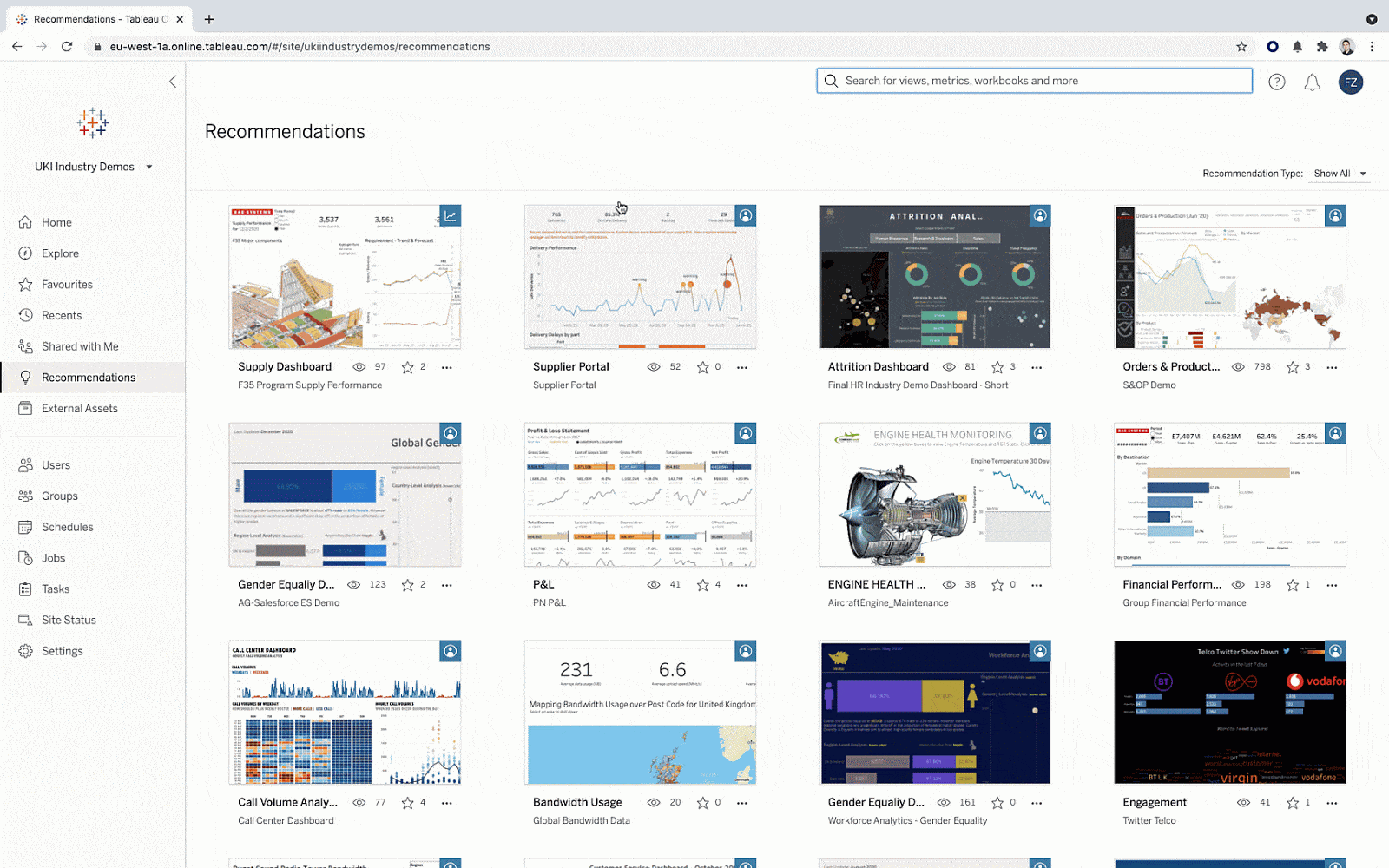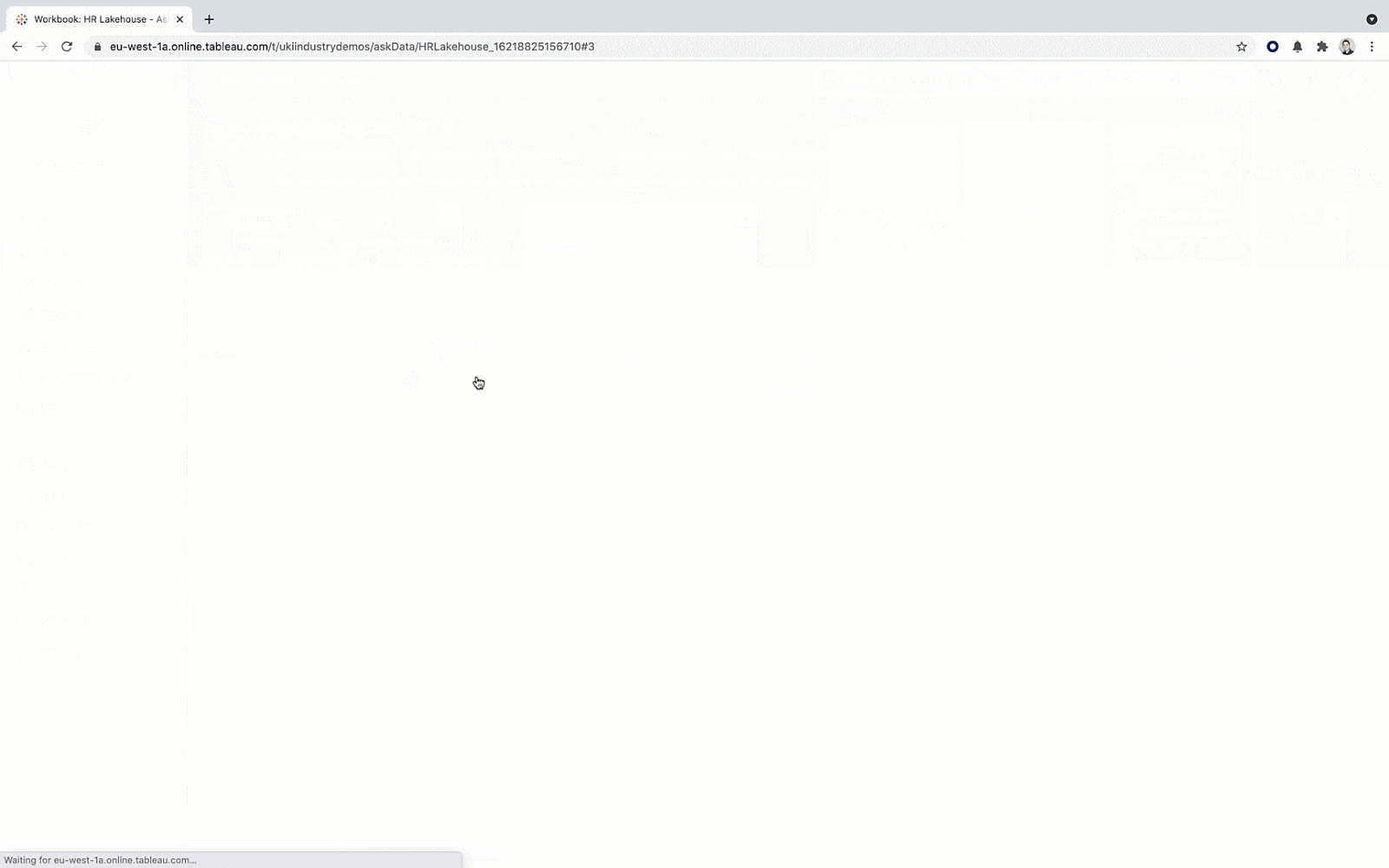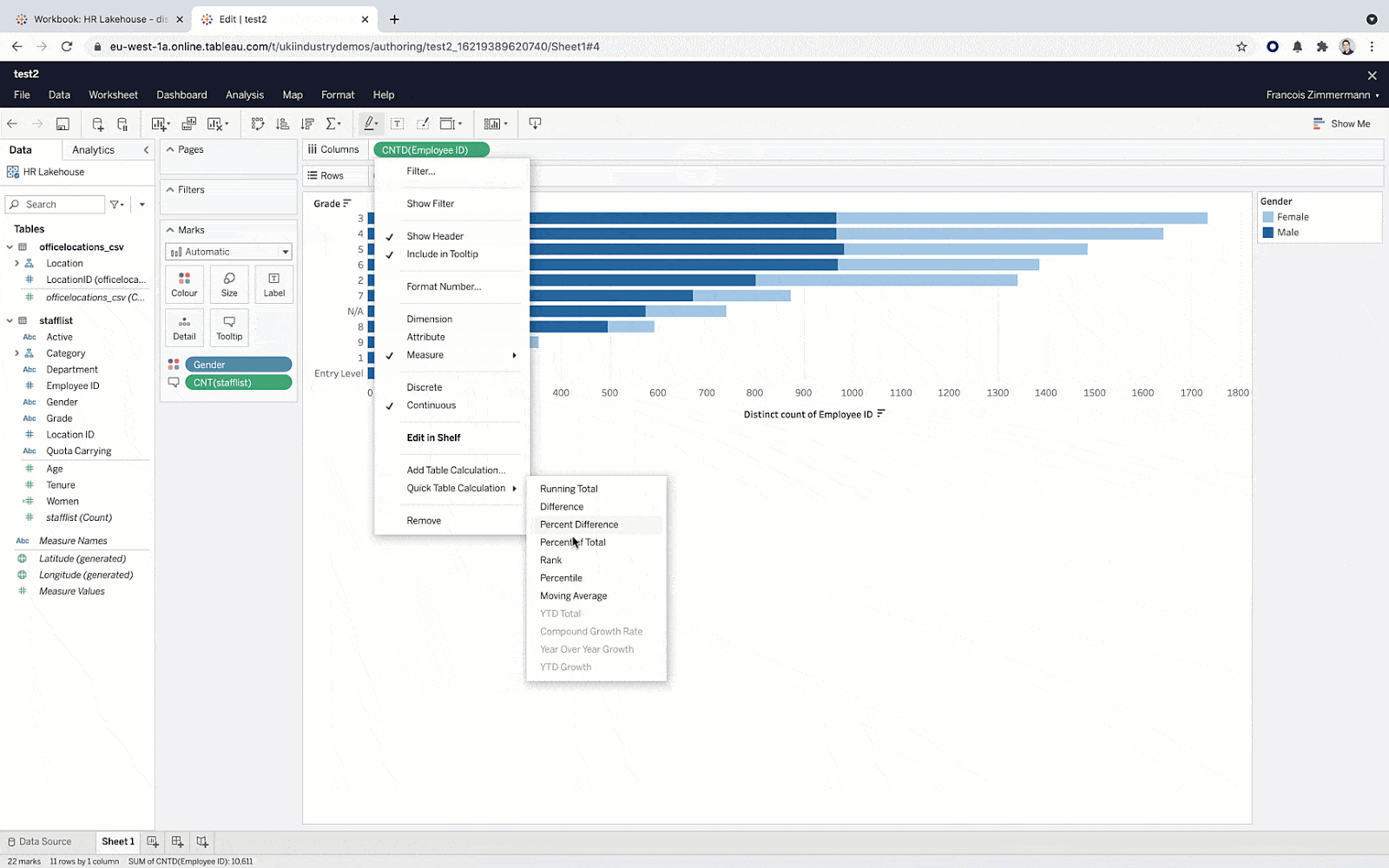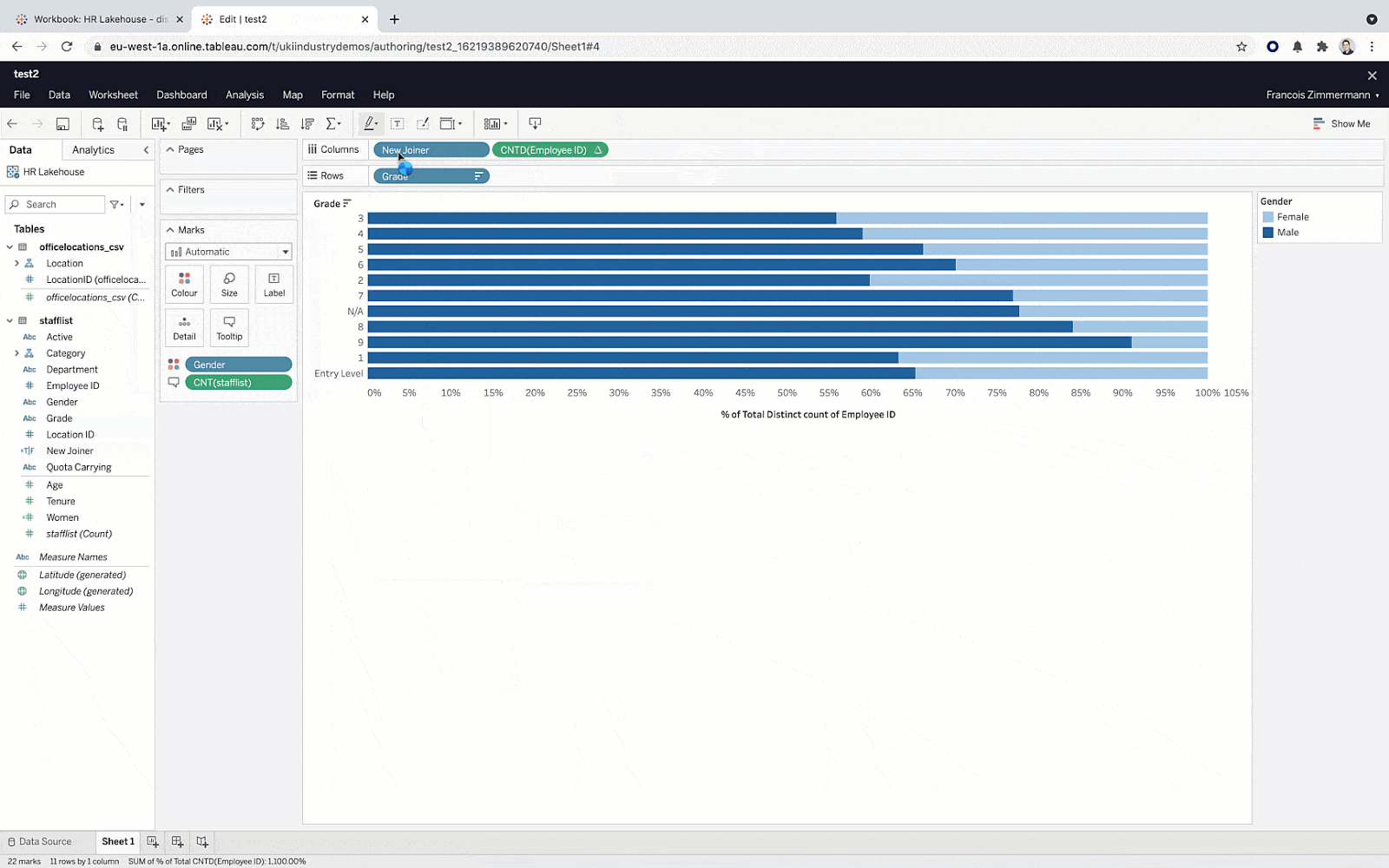
- Advanced data users can deliver predictive experiences using the Tableau Analytics Extensions API, allowing them to extend Tableau’s calculation language with models developed in Databricks.
Learn more about Databricks and Tableau at tableau.com/solutions/databricks.
相关故事

Tableau and dbt Labs: Strategic Partnership and Integration
 2025/08/25
2025/08/25

Supercharge Analytics with the Power of AWS-Hosted TabPy
 2024/10/14
2024/10/14
Tableau + AWS: Accelerating your digital transformation with Modern Cloud Analytics
 2023/11/27
2023/11/27
Tableau and AWS help customers digitally transform with Modern Cloud Analytics, combining technical resources and expertise with our vast partner networks.