Tableau 和 Python 如何搭配 TabPy 進行規範分析



這篇部落格貼文的版本最初出現在 Medium。
TabPy 是 Python 套件,可供您即時執行 Python 程式碼並在 Tableau 視覺化中顯示結果,以便您快速部署進階分析應用程式。TabPy 提供的分割方法可實現兩個世界級資料視覺化功能的優點,並且有強大的資料科學演算法做為後盾。在 Tableau 中顯示 Python 演算法的重大效益是,使用者可以在儀表板更新時調整參數,並即時評估對分析的影響。
為了達成這個目標,TabPy 主要是運用輸入/輸出方法,按照目前的視覺化效果彙總資料,並將調整參數傳送到 Python。系統將會處理資料,並且將輸出送回 Tableau 以便更新目前的視覺化。不過,您可能需要完整的基礎資料集來進行計算,但是您的儀表板正在顯示彙總度量,或者您想要同時顯示多個彙總等級。此外,您可能希望在一次計算中使用多個資料來源,而不影響儀表板的回應能力。
在這篇貼文中,我將逐步引導您採取一種方法,協助您在下列情況中完全發揮 TabPy 的功用:
- 即時互動:您想要操作即時使用者介面,以便盡可能減少參數變更和更新的視覺化之間所需的處理時間和延遲。
- 多個彙總等級:您想要在同一個 Tableau 儀表板顯示 (多個不同的) 彙總等級,不過您需要使用包含全部資訊的最精細、最細分等級來執行全部計算。
- 各種資料來源:後端計算不僅仰賴單一資料來源和/或資料庫
- 在 Tableau 和 Python 之間傳送的資料:每個最佳化步驟都需要大量資料,因此必須在 Tableau 和 Python 後端之間傳送大量資料。
用於規範分析的全新 TabPy 方法:逐步指示
為了執行 TabPy,我們假設已經安裝 Python 和 TabPy,因此您需要執行三個步驟:
為了逐步完成這三個步驟,我設計出透過產品組合最佳化來降低複雜度的使用案例。
使用案例:降低複雜度
最佳化的對象是 B2B 零售商,主要是透過併購 (M&A) 來成長。由於這種非計畫性的成長,零售商面臨許多複雜度,必須經營多個市場,而且本身的產品組合由分為多個類別和子類別的一千個 SKU (庫存單位) 組成。更複雜的是,SKU 是在不同的工廠中建立而成。
公司的資深管理階層希望透過移除利潤最低的 SKU 來增加利潤,不過願意繼續將業績不佳的 SKU 售出來保持一定的市佔率。他們也願意將製造工廠的營運保持在目標資產使用率以上,因為他們知道過度降低使用率會對於每間工廠的固定成本基礎造成負面影響。
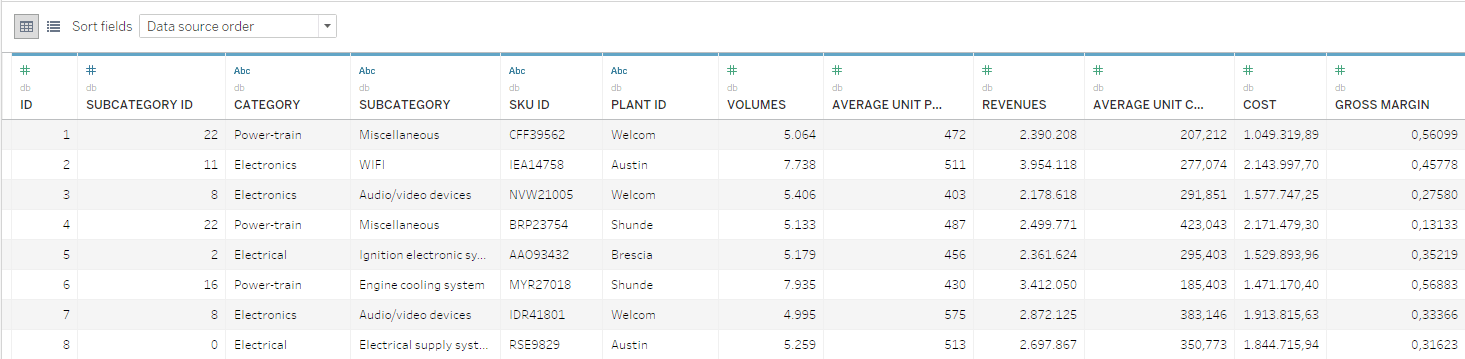
這個範例中可用的資料是由 SKU 等級資料庫組成,其中報告年度交易量、成本和收入。SKU 是按照類別和子類別階層進行劃分。
從數學的角度來看,產品組合最佳化管理工作相當簡單。不過,最佳化也必須考量策略的一切細微差異,並廣納相關各方共同參與,這些相關各方可以獲得做出明智決定所需的資訊和工具。
所有這些要求都可以透過以下所說明的 TabPy 方法加以解決。
1.準備初步的 Tableau 儀表板
首先,必須克服需要解決的問題。在這個範例中,簡單的最佳化演算法將會根據在 SKU 等級中評估的毛利來移除 SKU。
-
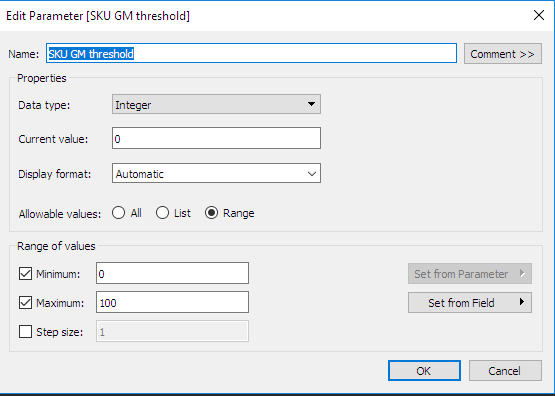
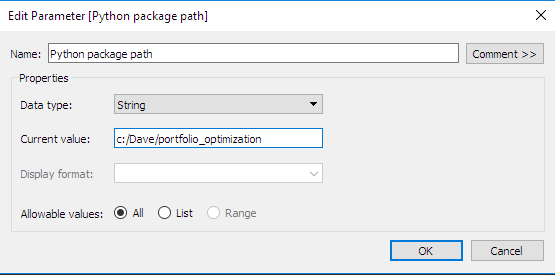
在 Tableau 中定義互動式參數:注意,我們已經定義第二個便利參數。這是即將儲存具有最佳化常式之 Python 套件的目錄。如我們將在下一節所見,這種類型的參數可以用於定義自訂計算。
- 定義彙總的檢視/等級:我們在這裡定義兩個彙總等級:SKU 等級和子類別等級。定義彙總等級相當重要,因為這會決定 Python 後端函數的簽章。必須為每個計算和彙總等級定義特定功能。對於每個彙總等級,必須定義下列函數:最佳利潤、最佳收入和最佳交易量。
-
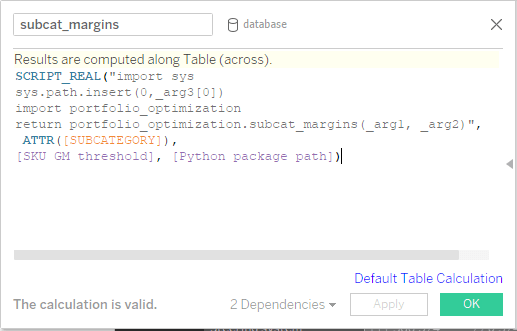
在 Tableau 中定義計算勾點 (回呼):定義輸入參數、彙總等級和所需的輸出計算後,即可定義自訂計算。為了方便起見,所有的最佳化常式均已在 portfolio_optimization Python 套件中完成結構建立作業,我們會在其中定義函數以傳回對針對定彙總等級選取的數量。值得注意的是,先前定義的參數 (Python 套件路徑) 已傳送到函數,而且在腳本中用於表示組合最佳化套件的儲存位置。此外,目前的彙總等級索引器 (例如,對於子類別彙總等級,子類別本身) 一律傳送到 Python 後端,才能確保按照正確的順序傳回結果。另外,系統也會傳送輸入參數 SKU GM 閾值。
2.在 Python 中建立後端計算常式
Python 後端分為兩個函數類別,這兩個類別是根據執行方式進行分組:執行一次的函數和重複執行多次的函數。第一個類別是資料庫擷取、轉換和載入操作等等。此類功能稱為「一次性操作」。另一個類別是多次重複的功能,例如所有的 Tableau 回呼:
- 一次性操作:在這個範例中,腳本第一次執行時,資料庫僅載入一次。然後,資料庫即可供其他所有將該資料庫儲存於全域變數中的函數使用。為了偵測資料庫是否已經載入,Python 會檢查本機名稱空間是否已經有該資料庫的副本。如果沒有這種預防措施,Tableau 每次要求計算時都會載入資料庫,進而對執行速度造成負面影響。
- Tableau 回呼:先前定義的每個勾點都必須具有為本身提供服務的函數。在我們的案例中,對於收入、交易量和利潤提供個別的計算,並使用做為函數輸入而傳送的索引器,對 Pandas groupby 函數建立索引,然後將該函數用於彙總最佳化結果,即可取得回呼。值得注意的是,為了提高執行速度,回呼會使用參數變更偵測器。只有在變更參數時才會產生新的最佳化,而且其結果可供運用全域變數的全部回呼使用。參數變更的偵測是透過永久變數來進行,該變數將用於在前一次執行時儲存其值。這種方法可確保盡可能減少使用高成本操作,藉以提高執行速度。
3.設計 Tableau 前端
透過這個步驟,我們定義所有的基本部分,包括彙總等級、要調整的參數,以及計算後端傳回的輸出欄。
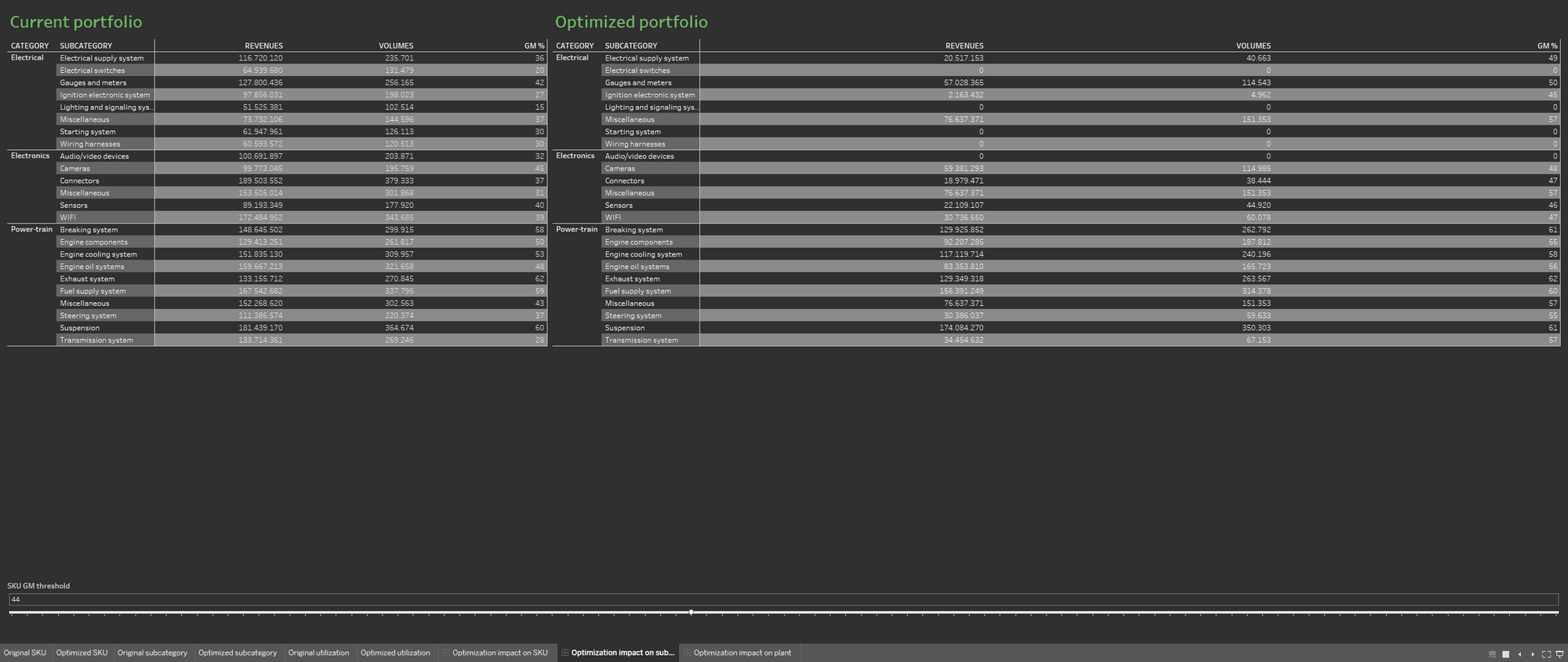
為了更容易討論最佳化,請定義兩個個別的工作表,以便顯示最佳化過程前後的組合。並排顯示兩個工作表。
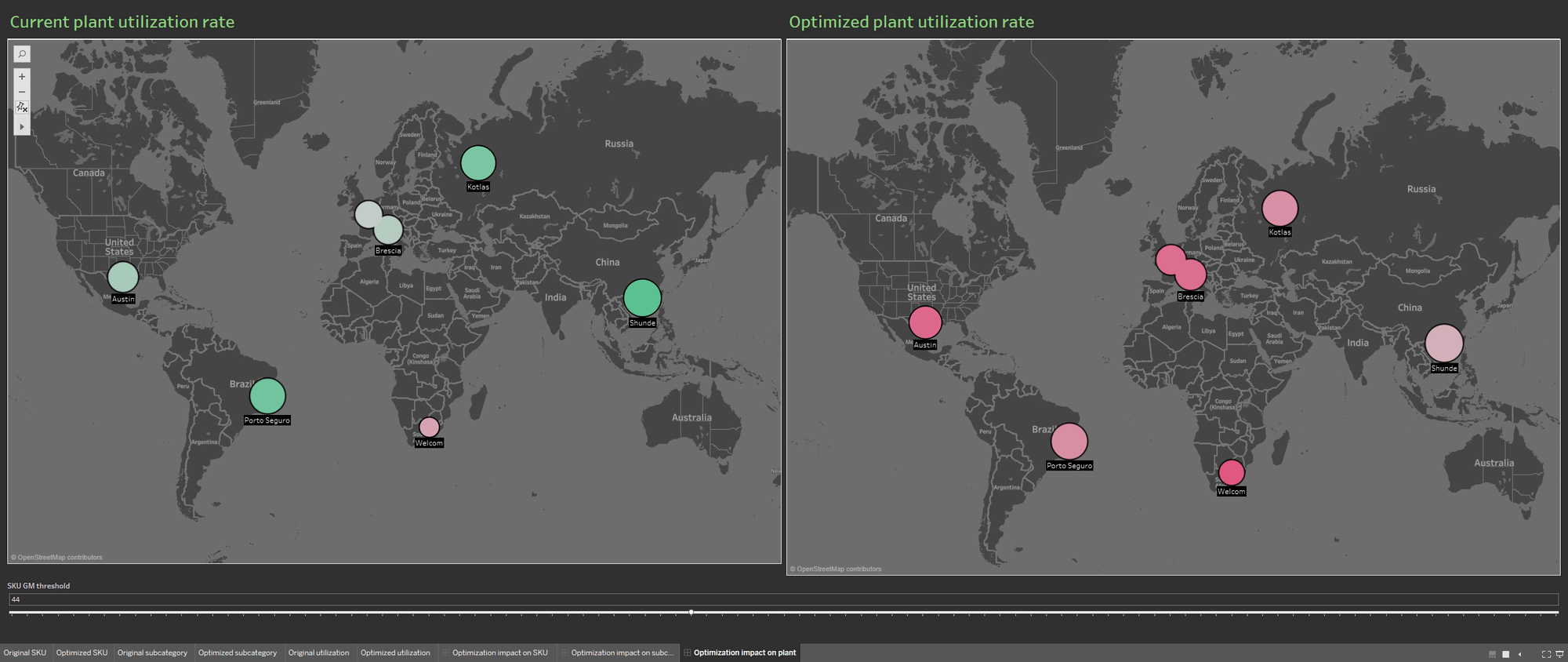
系統會透過在視覺化內容中填入目前工廠使用率和從最佳化組合衍生的使用率有關的資訊,提供多個資料來源以供使用,藉此讓組合資料庫更為豐富。同樣地,系統會並排顯示兩個資訊視覺化,以便更忠實地呈現最佳化對生產工廠的影響。
在團隊中使用 TabPy 所發揮的更多效益
除了團隊能夠與強大的資料科學技術進行即時互動所產生的龐大商業價值之外,這種全新的方法也具有顯著的後端效益。其他許多資料視覺化技術在整個過程中都需要高成本的資料科學人員參與。不過,這種方法僅需要資料科學家資源備妥初步的 Tableau 儀表板並建立後端 Python 計算常式。Tableau 的易用性有利於更多的資源能夠設計前端,並且由最終使用者進行測試和維護。
前端設計通常是漫長而且反覆的過程,需要與最終使用者進行多次討論。全新的 TabPy 方法可供經理在專案執行期間更換團隊組成的人員,因此顯著改善成本效率。這種方法也確保底層後端的高度可重新使用性,因此眾多使用者可以在 Tableau 中建立自己的自訂儀表板,以便適應特定的脈絡、受眾和情況。計算邏輯和基本部份的這種重新使用是改善資料視覺化整體成本的另一種方法。
如果您有興趣想要深入研究,此處將提供 Tableau 儀表板和 Python 後端。如果您需要這個方法有關的更多資訊,請參閱官方 TabPy Github 存放庫或造訪這個 Tableau Community 討論串。
相關文章
VizQL Data Service from Tableau: Use Your Data, Your Way
 2024/08/08
2024/08/08

When and How to Use Multi-fact Relationships in Tableau
 2024/08/01
2024/08/01

Top data books of 2021
 2021/12/12
2021/12/12