Leverage the power of Python in Tableau with TabPy




TabPy is a new API that enables evaluation of Python code from within a Tableau workbook.
When you use TabPy with Tableau, you can define calculated fields in Python, thereby leveraging the power of a large number of machine-learning libraries right from your visualizations.
This Python integration in Tableau enables powerful scenarios. For example, it takes only a few lines of Python code to get the sentiment scores for reviews of products sold at an online retailer. Then you can explore the results in many ways in Tableau.
You might filter to see just the negative reviews and review their content to understand the reasons behind them. You might to get a list of customers to reach out to. Or you might visualize overall sentiment changes over time.
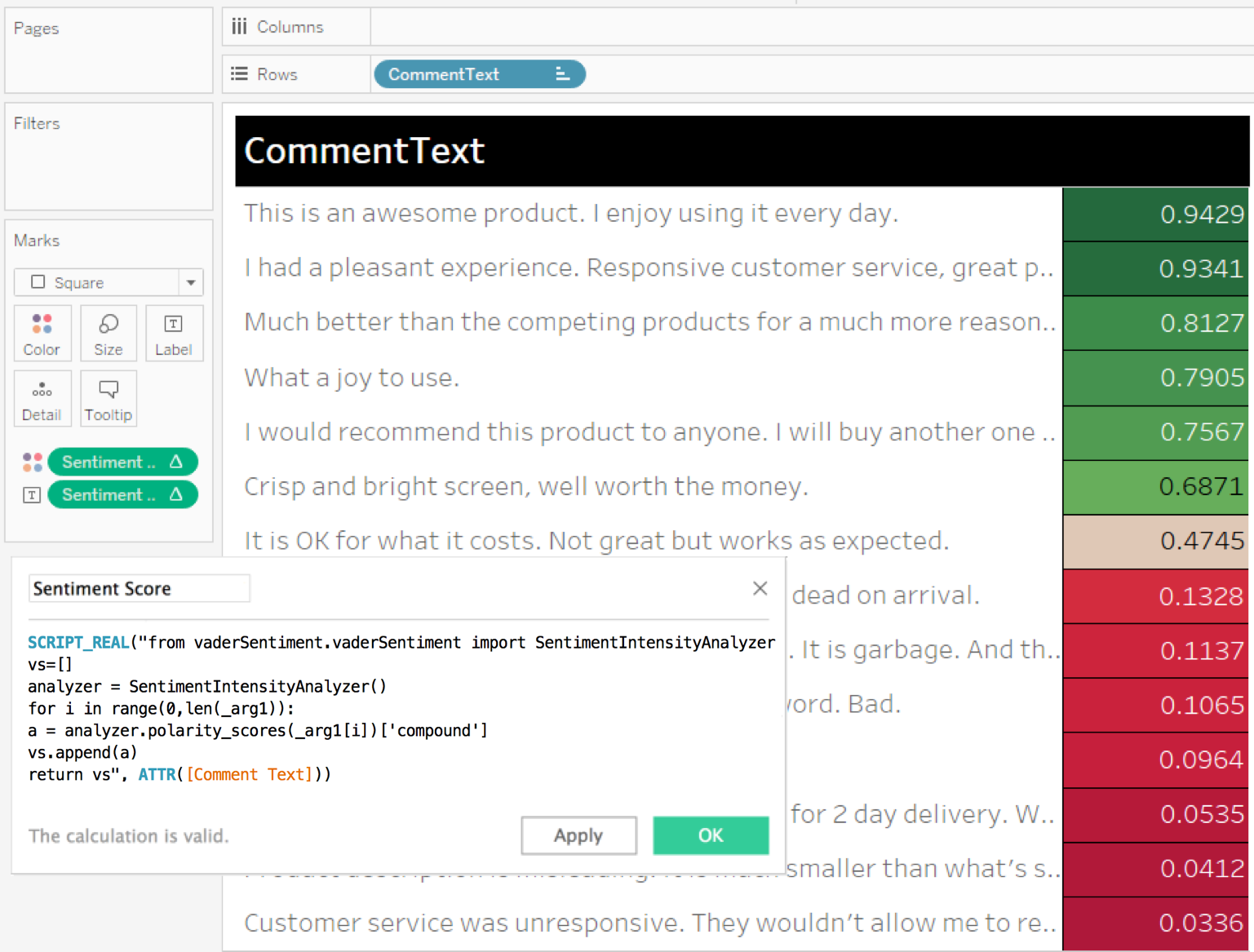
Other common business scenarios include:
- Lead scoring: Create a more efficient conversion funnel by scoring your users' behavior with a predictive model.
- Churn prediction: Learn when and why users leave, and predict and prevent it from happening.
You can easily install the TabPy server on your computer or on a remote server. Configure Tableau to connect to this service by entering the service URL and port number under Help > Settings and Performance > Manage External Service Connection in Tableau Desktop. Then you can use Python scripts as part of your calculated fields in Tableau, just as you’ve been able to do with R since Tableau 8.1.
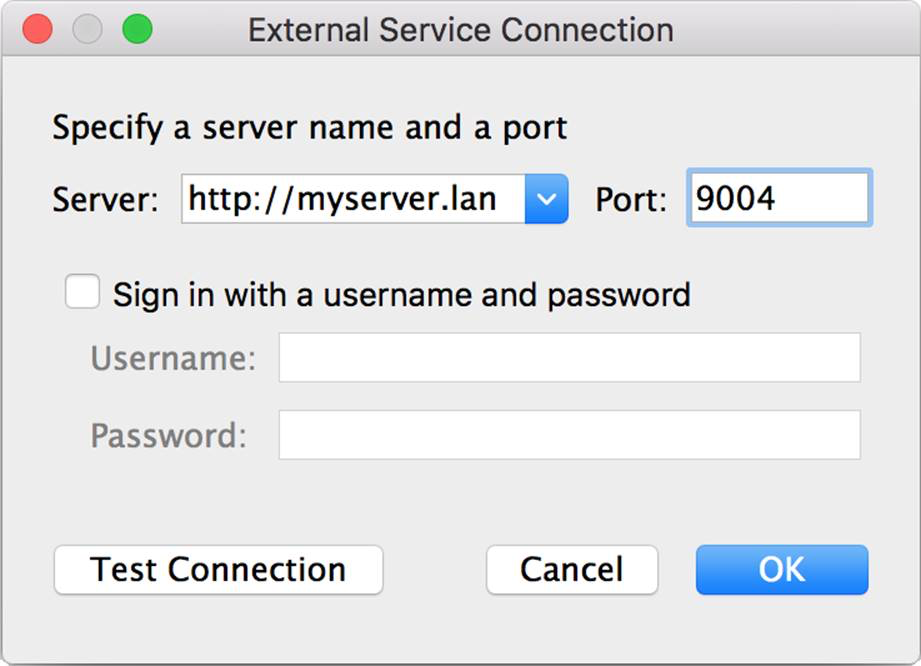
TabPy uses the popular Anaconda environment, which comes preinstalled and ready to use with many common Python packages including scipy, numpy, and scikit-learn. But you can install and use any Python library in your scripts.
If you have a team of data scientists developing custom models in your company, TabPy can also facilitate sharing those models with others who want to leverage them inside Tableau via published model.
Once published, all it takes to run a machine-learning model is a single line of Python code in Tableau regardless of model type or complexity. You can estimate the probability of customer churn using logistic regression, multi-layer perceptron neural network, or gradient boosted trees just as easily by simply passing new data to the model.
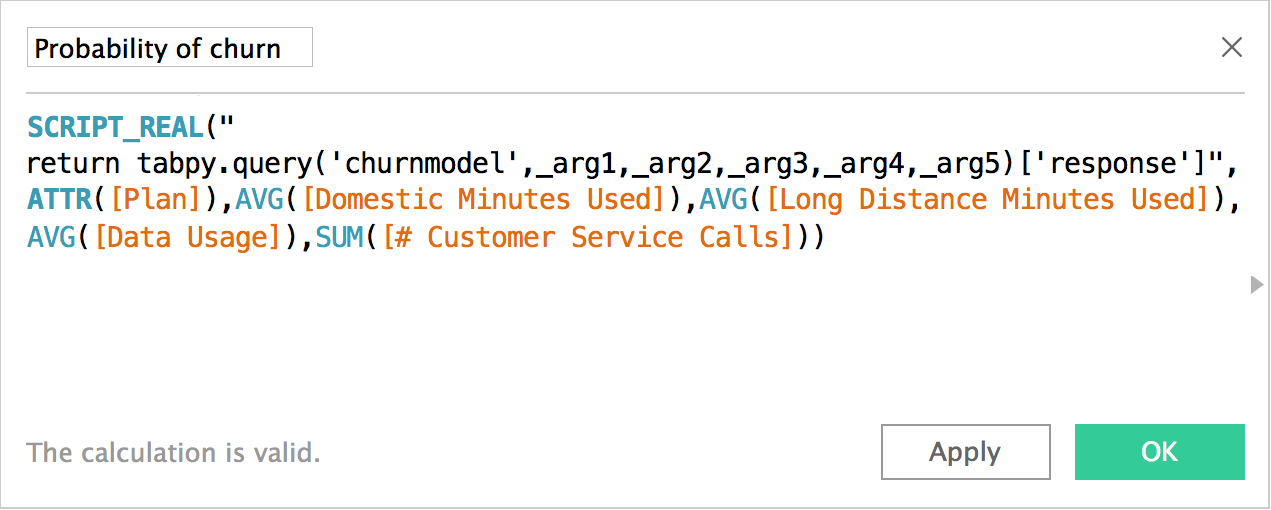
Using published models has several benefits. Complex functions become easier to maintain, share, and reuse as deployed methods in the predictive-service environment. You can improve and update the model and code behind the endpoint while the calculated field keeps working without any change. And a dashboard author does not need to know or worry about the complexities of the model behind this endpoint.
Together, Tableau and Python enable many more advanced-analytics scenarios, making your dashboards even more impactful. To learn more about TabPy and download a copy, please visit our GitHub page.
Do more with Tableau and Big Data
Find out how Tableau solves many of the problems Big Data can present to organizations of any size.
Learn more.
Historias relacionadas

The Tableau+ Bundle with Premium AI, Enterprise Capabilities, and Premier Success
 24 Junio, 2026
24 Junio, 2026
What is Tableau Prep?
 30 Abril, 2026
30 Abril, 2026
Insights Wherever You Work: Meet the Tableau App for Microsoft 365
 16 Marzo, 2026
16 Marzo, 2026