Tableau Prep フローが R と Python のカスタムスクリプトを新たにサポート




更新: Tableau の最新バージョンがリリースされました。このリリースの最新のイノベーションをご覧ください。
Tableau Prep Builder は、データ探索とデータ準備のパワフルなツールです。フローの複雑さは、作成するユーザーによって大きく異なります。Prep Builder はさまざまなユースケースに簡単に対処できますが、簡単には設定できない高度なシナリオもやはりあります。
この差を埋めて、Tableau Prep のさらに興味深い使い方ができるようにするために、Tableau Prep のフローから Python と R のカスタムスクリプトが実行できるようになります。この機能は現在、次回の Tableau 2019.3 リリースのベータ版で提供されています。
ユーザーは、フローのどのステップでもスクリプトを接続し、希望するスクリプト言語の力を最大限に活用して、データの形式変換、リモートソースにある他の情報の参照、さらには入力値に対する複雑な機械学習パイプラインの実行が可能です。
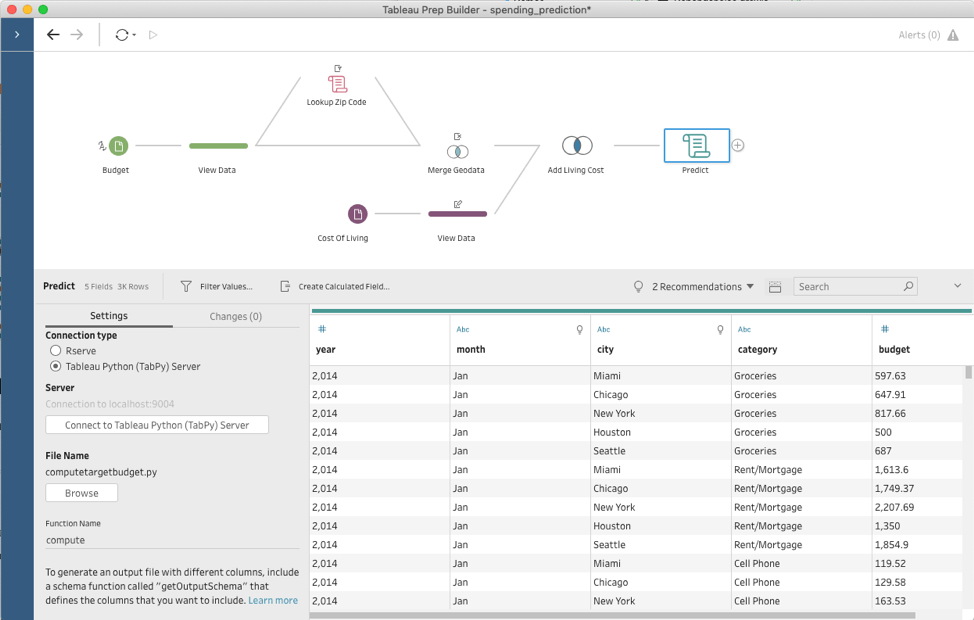
Tableau Prep フローのどのステップでも R や Python のカスタムスクリプトが追加可能
このブログの例では、Python スクリプトを実行できるように Prep Builder を構成する方法を説明し、地理的なルックアップの実行など、この新機能の優れた活用方法をご紹介します。
「What-if」シナリオの探索では、さまざまなカスタムスクリプトを使うことができます。しかし、ここの目的は、米国のいろいろな場所での出費や生活費のデータを比較して、他の都市に引っ越した場合に費用がどうなるかを予測することです。作成しているフローでは、ここ数年分をまとめた出費データ、生活費データ、都市に対応する郵便番号を使っています。
TabPy の設定
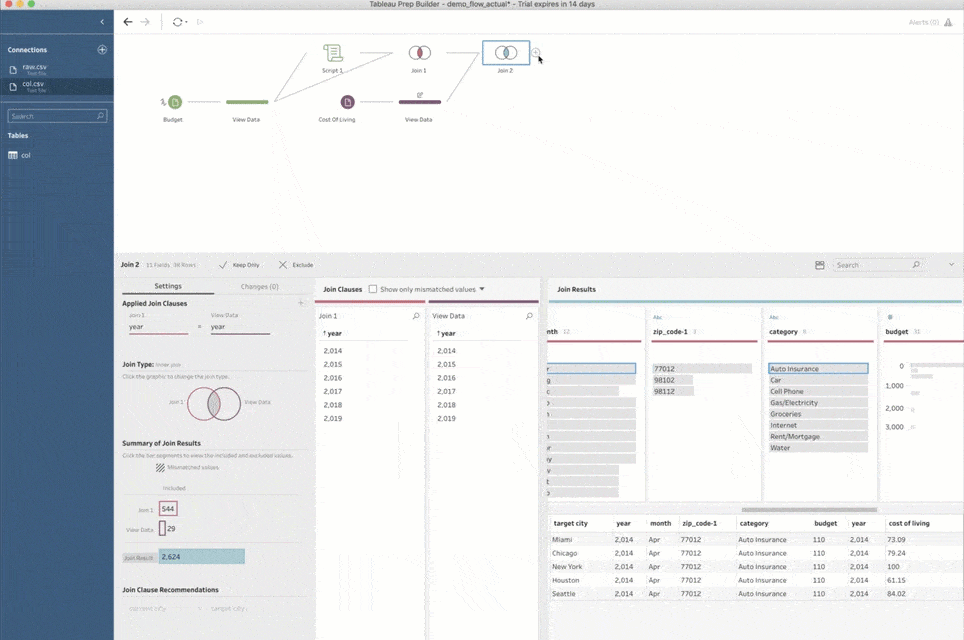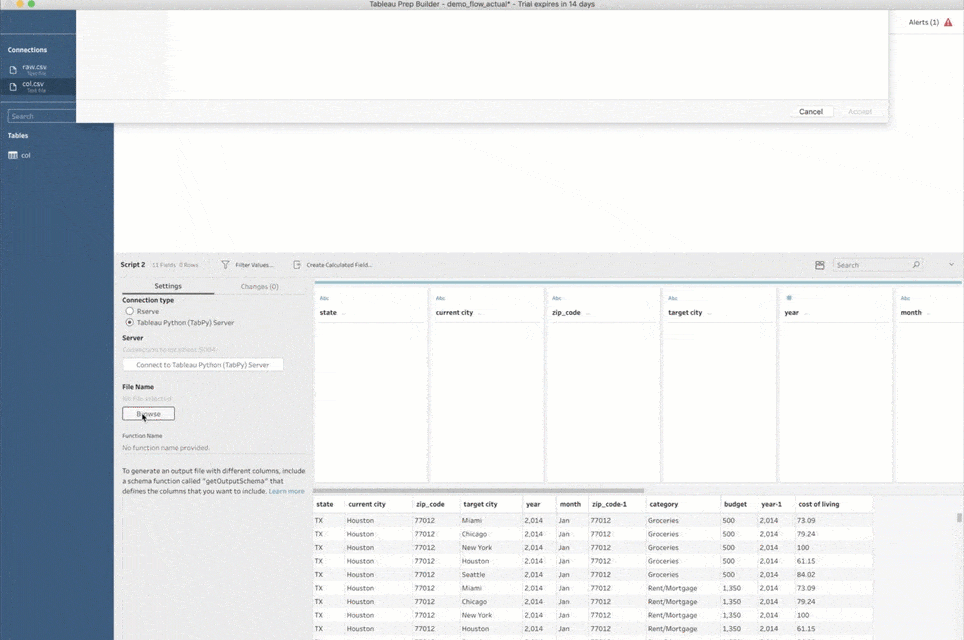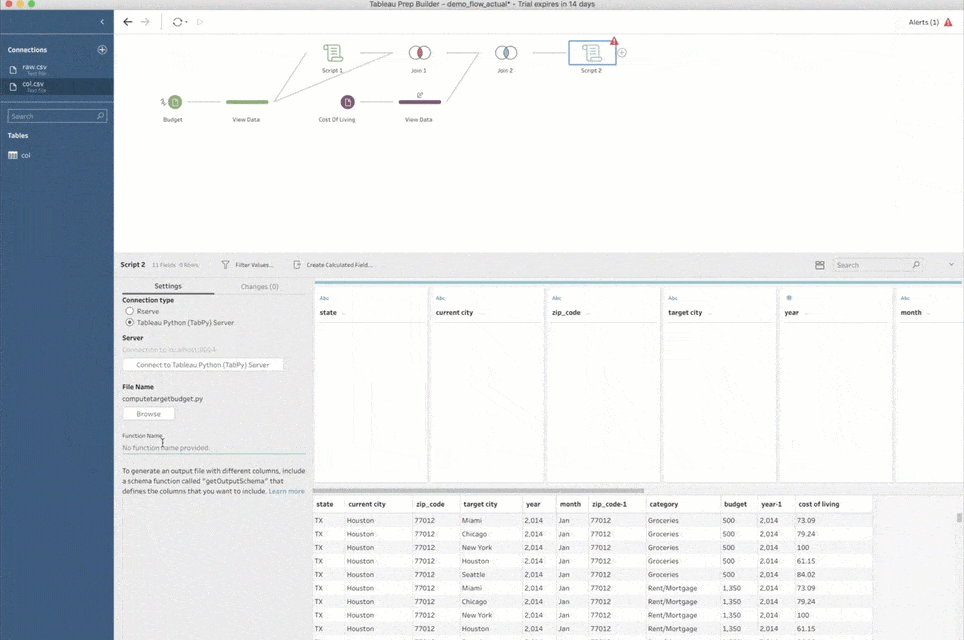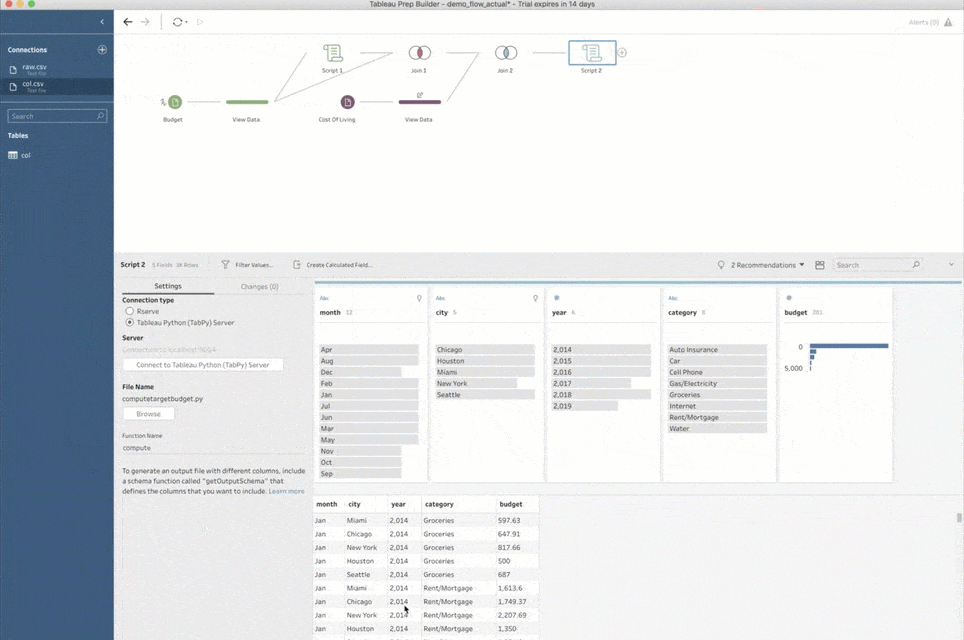
Tableau Prep Builder では、Python コードを実行するためにオープンソースツールの TabPy を使います。スクリプトの実行は高度な機能であり、設定はユーザーによって大きく異なるため、すぐに使える状態の TabPy は Prep Builder に含まれていません。しかし、心配は不要です。設定はとても簡単で、ここから始めることができます (英語)。すべてが期待通りに構成された場合、TabPy サーバーに接続するためのポート番号が一番下に表示されます。既定の値は「9004」です。
他の言語と同じように、Python を便利に使うにはサードパーティーのライブラリが欠かせません。Prep でも「pandas」ライブラリをインストールする必要があります。「pandas」は、Python との間でデータをやり取りするために使う、効率的なデータフレームを提供します。インストールはとても簡単で、Python に付属しているツールの「pip」を使用します。先ほどの出費の問題には、「requests」というライブラリも必要です。そこで、両方ともインストールするために
> pip install pandas requests
を実行した後、TabPy サーバーを再起動します。Python の別のライブラリが必要になった場合はいつでも、「pip」を使ってインストールし、TabPy を再起動してください。
この時点ですべての構成が終わったので、問題の答えを出すことに取りかかりましょう。
地理的なルックアップの実行
各都市での出費を予測するために、ここでは生活費指数を使っています。この指数は都市の出費の相対的な高さを示し、ニューヨーク市の値を 100 として、それと比較したパーセンテージで表されます。私が持っている出費の生データでは、都市ではなく郵便番号が使われているため、郵便番号を変換する手段が必要です。そこで Python 統合機能を活用して、各郵便番号の都市をプログラムで調べます。
この作業はシンプルで、スクリプトのステップを追加し、Python スクリプトのファイルを指定して、そのファイルから呼び出す関数の名前を入力するだけです。Prep Builder は、1 つ前のステップの全入力データを TabPy に送り、データを引数にしてその関数を呼び出します。そしてスクリプトのステップで、返されたデータセットを表示します。
先ほどの郵便番号変換の具体的な例で、スクリプトの内容を見てみましょう。これがスクリプトファイルです。
import requests API_KEY = "" URL = f'https://www.zipcodeapi.com/rest/{API_KEY}/info.json' def lookup(df): result = pd.DataFrame(columns=['zip_code','city', 'state','area']) for zip in df['zip_code'].unique(): response = requests.get(f'{URL}/{zip}/radians').json() zip_code = response['zip_code'] city = response['city'] state = response['state'] result = result.append({ 'zip_code' : zip_code, 'current city' : city, 'state' : state }, ignore_index=True) return result def get_output_schema(): return pd.DataFrame({ 'zip_code' : prep_string(), 'current city' : prep_string(), 'state' : prep_string() });
このスクリプトファイルでは、「lookup」と「get_output_schema」という 2 つの関数が定義されています。
「lookup」関数は実行の本体であり、実際のデータ変換を行います。これが、Prep Builder のユーザーインターフェイスで設定する関数です。この関数は、入力を「pandas」のデータセットとして扱い、「zip_code」 (郵便番号) 列を使って、対応する「city」 (都市) と「state」 (州) を zipcodeapi.com (英語) にリクエストします。結果は、元の郵便番号、現在の都市、州という 3 つの列を持つ、もう 1 つの「pandas」データセットになります。なお、入力の他の列は使いません。入力に「zip_code」列があれば、データの残りの部分がどのようになっていてもこのスクリプトは問題なく動作します。
2 番目の「get_output_schema」関数は、スクリプトの処理結果として期待されるデータを Prep Builder に理解させる役割を持っています。スクリプトを細かく見ると、この関数は「lookup」関数とまったく同じ列を持つ「pandas」データフレームを返しますが、期待されるデータ型を Prep Builder に教えるための「prep_string()」という値を持っていることがわかります。もちろん、「prep_int()」や「prep_bool()」などの別の型もサポートされています。
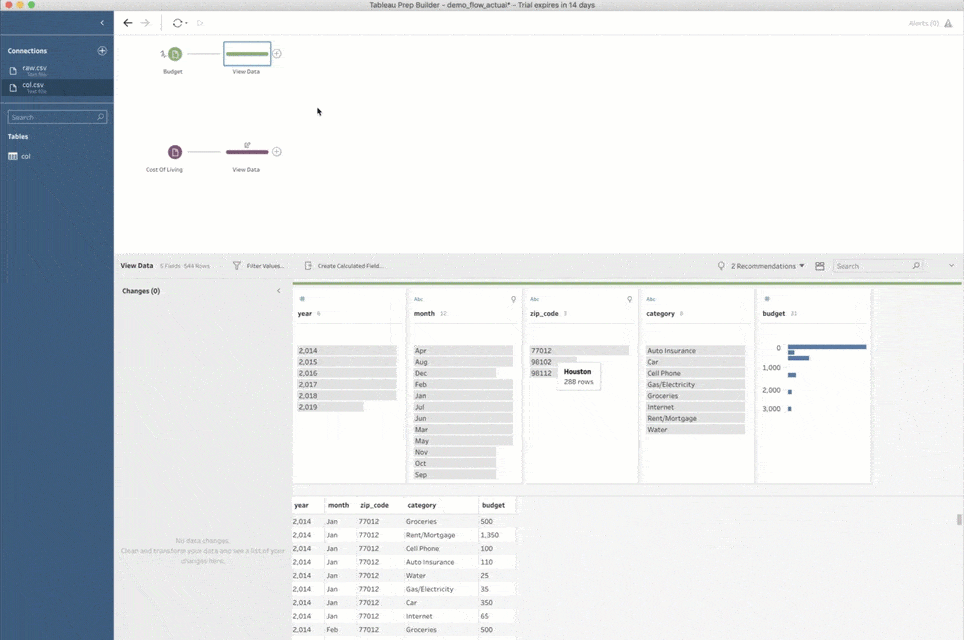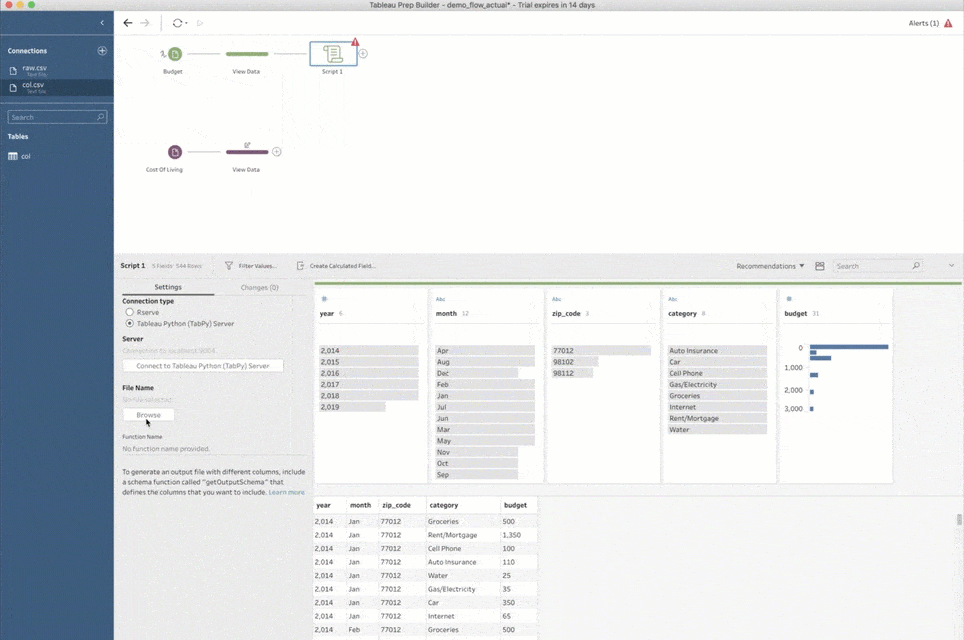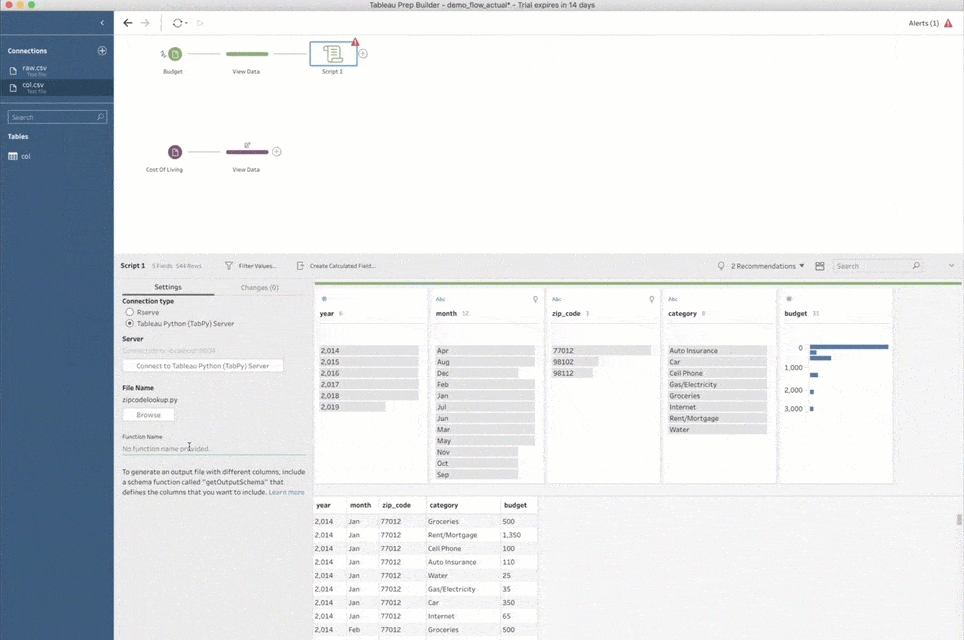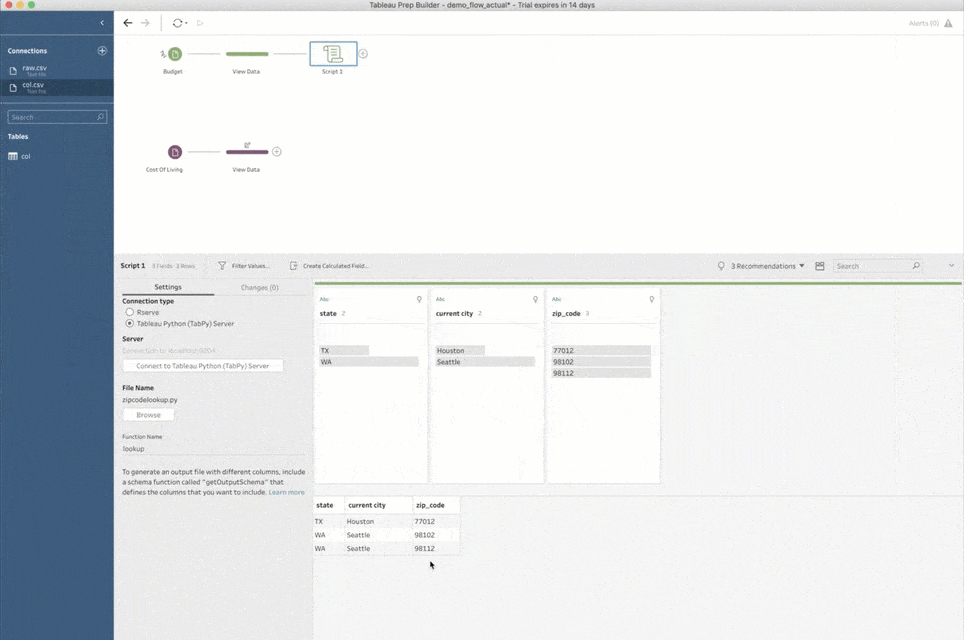
次に進む前に、もう 1 点述べておきます。スクリプトのステップをフローに初めて追加するときは、TabPy への接続方法も Prep Builder で指定する必要があります。それには、[接続タイプ] で [Tableau Python (TabPy) Server] を選択し、[Tableau Python (TabPy) Server に接続] をクリックします。そしてポップアップウィンドウで、TabPy インスタンスのサーバー名とポート番号を指定してください。上で説明したようなローカル設定の場合、サーバーは「localhost」、ポート番号は「9004」です。
予測モデリングのためのデータセットの準備
上のセクションのスクリプトを使うと、正確な都市名と州名で、とても簡単に出費データを補完できます。スクリプトの戻り値を元の入力に結合するとデータがマージされ、さらに処理を進められます。
しかし、出費を予測できるようにするには生活費データを追加する必要があります。その情報を取得するための似た API もありますが無料では入手できないため、ここでは代わりに、必要なデータがある固定値の csv ファイルを使うことにしました。もちろん、そのような情報を取得できるようにする API を利用できる場合は、先ほどの郵便番号のルックアップのときのように、それを代わりに使うことをお勧めします。
私が持っているデータにあるのは、都市名、それぞれの生活費指数、指数の取得年のみです。ここでは 5 都市の 2014 ~ 2019 年のデータを集めましたが、私の質問のようなものでは十分なサンプルになるはずです。
今は特定の場所と時点のデータに基づいて複数の都市の出費を予測しようとしているので、必然的に 1 対多の関係に相当します。出費データセットの各レコードは、各出費エントリが作成されたのと同じ年に対する、各「対象」都市とその指数です。この場合、Prep Builder の内部結合で簡単に表すことができます。
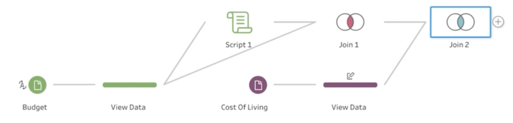
データ準備のステップが視覚的に表示されるフローペイン
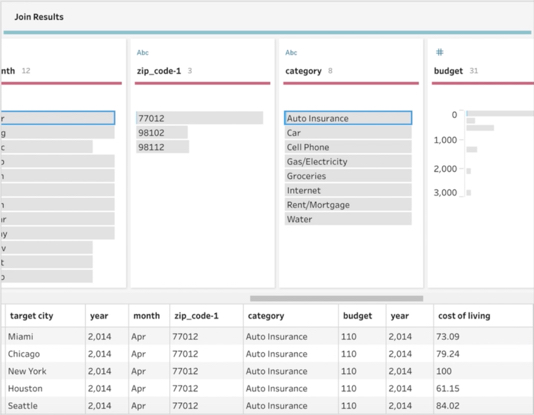
内部結合の結果が表示されるプロファイルペインとデータグリッド
出費の予測
全データをマージしたので、ついに出費見込みの予測に取りかかることができます。その方法の具体的なロジックは、場合によって大きく異なります。たとえば、シンプルな計算のこともあれば、出費データを分析して経時的な出費パターンの微妙な相違点を推測する、高度な機械学習モデルのこともあります。いずれにしても、Python はその作業で大きく役に立ちます。Python は、複雑なデータ変換を可能にするだけではなく、複雑な機械学習パイプライン作成のための素晴らしいライブラリも持っています。ここでは、別のスクリプトを作成し、そのスクリプトでデータセット全体を使って出費を予測することが簡単にできます。また、この作業とスクリプトはまったく異なってはいますが、Prep Builder ですべてを設定するプロセスは、郵便番号のルックアップで行ったことと同じです。
そして、出力データソースを作成して、予測結果を Tableau Server にパブリッシュすることができます。さらに素晴らしいのは、Prep Conductor のジョブとして、完成したフローのスケジュールを設定して、自由な頻度で機械学習パイプラインを更新することが簡単だという点です。
注意点: 完成したフローは Tableau Online にパブリッシュすることもできますが、スクリプトが含まれるフローの Tableau Prep Conductor による実行は、Tableau Online ではまだサポートされていません。
まとめ
Prep Builder でこの新しいスクリプト作成機能がサポートされたことによって、Prep Builder に組み込まれた機能をはるかに超える、複雑なデータ変換シナリオの実現がこれまでになく簡単になりました。この機能は、シンプルな計算から複雑な機械学習モデル、インターネットからのデータ取得まですべて扱うことができます。
ベータ版の段階で、非常にポジティブなフィードバックがコミュニティから寄せられました。カスタムスクリプト作成のサポートには大きな需要が明らかにあり、さまざまな背景を持つユーザーが独自のスニペットを作成して、Prep Builder をさらにパワーアップしています。私自身も、この統合はとてもうれしく思っています。独自の Python スクリプトを書き始めて Tableau Prep に統合することがどれほど簡単か、おわかりいただける内容になっていれば幸いです。
2019.3 ベータ版でお客様自身のアイデアを試し、Python と R の統合機能を実際に体験するには、プレリリースプログラムにご参加ください。
関連ストーリー
Extend Access to Embedded Tableau Content with On-Demand Access
 2026/07/22
2026/07/22
What is Tableau Prep?
 2026/04/30
2026/04/30
あらゆる業務環境でインサイトを取得: Microsoft 365 用の Tableau アプリ登場
 2026/03/16
2026/03/16