You can now choose multiple table storage for extracts




Update: This feature is now available! Check out the latest release of Tableau.
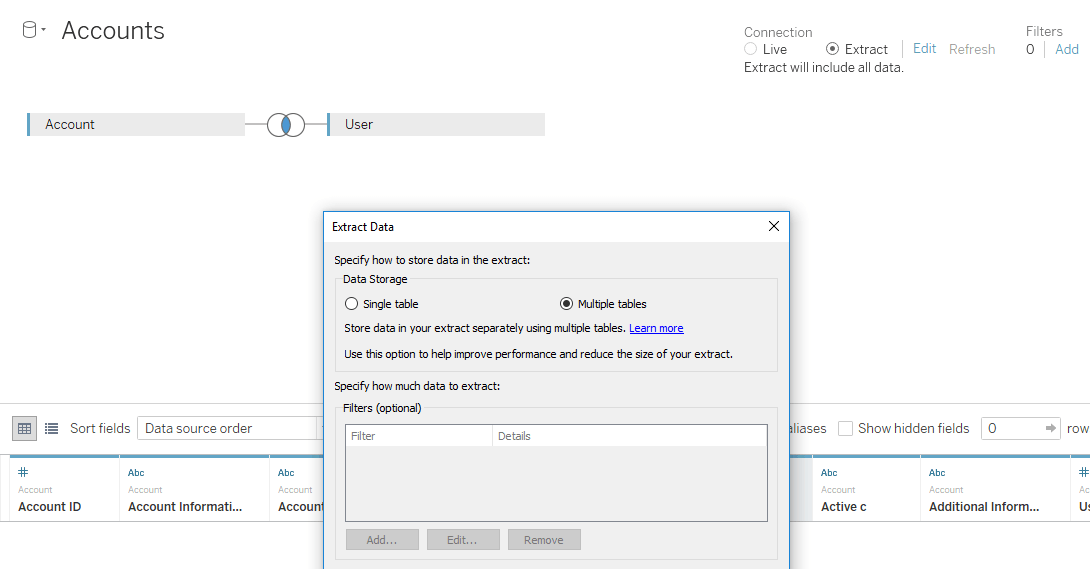
We’re introducing a new performance feature for some extracts in the newest Tableau beta (2018.3)—multiple table storage. When creating extracts, you can now select a new “multiple tables” storage option. When selected, the individual database tables will be stored in the .hyper extract file separately, mirroring the database structure. In certain cases, this will result in smaller extract file sizes, faster extract creation, and potentially faster queries.
How does it work?
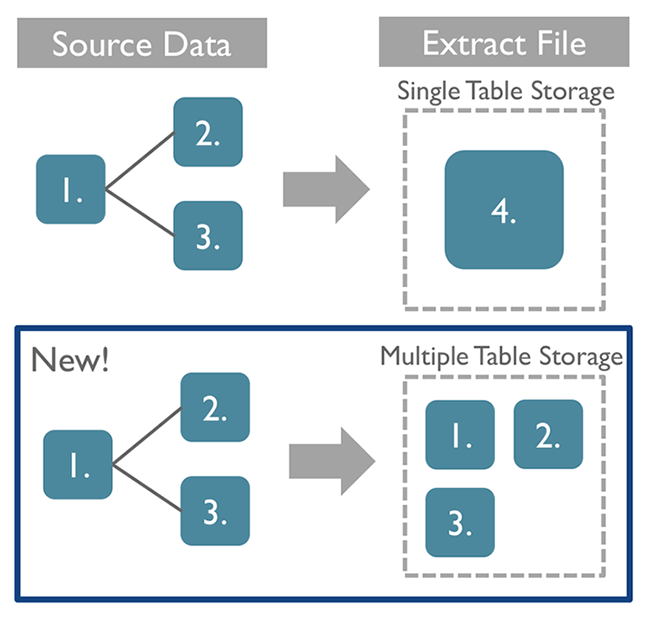
This feature changes how data is stored in the extract file behind the scenes. Previously, extracts always joined all data tables together to produce one output data table, regardless of the number of tables in the data tab. Now, with the new "multiple tables" option, users can choose to store each table independently in the extract file. There is still only a single extract file produced and stored on disk—the tables comprising it are stored separately within the single file.
When should I use multiple table storage?
Single table storage (the default storage type) and multiple table storage each have better file size and performance characteristics in different scenarios, so we allow you to choose.
The storage type affects file size because certain types of joins cause data storage redundancy. Previously, Tableau stored the result of the join, so it would store all the redundant data, often resulting in large extract files. If the number of rows after your join is larger than the sum of the rows in your input tables, then your data source is a great candidate for multiple table storage. Joins that are likely to cause data storage redundancy include joins between fact tables and entitlement tables in some row-level security scenarios.
In addition to file size differences, multiple table storage and single table storage can affect extract creation speed and visualization query speed. For single table storage, your source database will perform the join during extract creation. With multiple table storage, however, Tableau Desktop will perform the join inside Tableau’s data engine during visualization query time. So, multiple table storage extracts may initially be created faster because they only require copying the individual tables, without requiring a join. On the other hand, multiple table storage extracts might be slower during query time because of the join required at that time.
These performance differences are more noticeable with large amounts of data. If you are working with a large data set, you'll want to experiment with both techniques to determine which gives you the best performance and size benefits.
If you can’t decide which to use, stick with the default, single table storage, because multiple table storage has some functional limitations—including no incremental refresh and no extract filters. We plan to address these limitations in future releases.
Example 1: Superstore and entitlements table
Here's an example where multiple table storage results in substantial performance improvements.
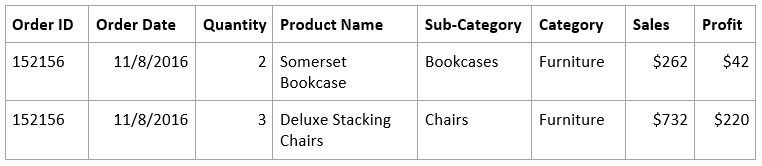
My data is an Excel file with two tables:
- Extrapolated Superstore table with 50k rows (each row is an order)
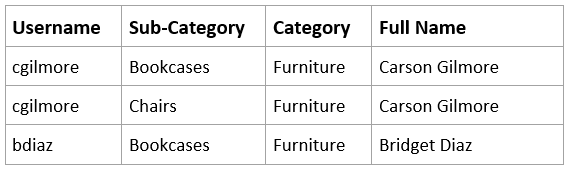
- Entitlements table with 1300 rows that maps users to the sub-categories that users have permission to view
I join the tables via an inner join on "Sub-Category" and measure the results.

The multiple table storage extract performs substantially better because it prevents data storage redundancy at extract creation time.
Example 2: Superstore and dimension table
Here's an example where multiple table storage results in performance degradations; single table storage is the preferable storage type for this scenario.
My data is an Excel file with two tables:
- The same extrapolated Superstore table with 50k rows (each row is an order)

- Dimension table with additional product information for only the Bookcases sub-category
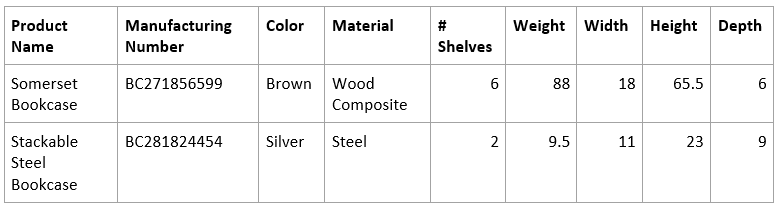
I join the tables via an inner join on "Product Name" and measure the results.

In this scenario, the inner join on "Product Name" does an implicit filter on the Superstore table. So, all the non-bookcase orders are omitted from the single table extract file, resulting in a smaller file size.
Note: These time measurements were done with the same computer: Windows 10 with 32GB RAM, 16 cores; dual processors – (2) Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz, 2401 MHz, 8 core(s), 16 logical
Enhancement for some row-level security scenarios
One important use case for multiple table storage is row-level security scenarios where entitlement tables are joined and extracted with your data. Previously, joining an entitlement table and a fact table into a single table would result in too many rows for extract creation to be feasible. Now, these tables can be stored separately in the extract file—before the join—so the extract creation is much faster.
For more information about row-level security and how multiple table storage can be leveraged, refer to Bryant Howell’s blog post.
Be a part of the latest and greatest
We are working hard to get Tableau 2018.3 out the door, but we appreciate your feedback to catch any issues and to ensure the highest quality for new features.
Join the Tableau pre-release community to:
- Participate in alpha and beta programs for early access to new features, versions, and products.
- Engage directly with the Tableau development team through user research, product discussions, and feedback activities around topics you care about.
- Explore the Ideas forum to see which ones have been incorporated based on your feedback and continue to add feature requests to inspire our development team! We couldn’t do it without you.
Not all functionality described above may be available in the beta program today. Some features will be added in the coming weeks. The beta program is available for existing Tableau customers. Customers with an active maintenance license can upgrade for free when Tableau 2018.3 is released.
関連ストーリー
What is Tableau Prep?
 2026/04/30
2026/04/30
あらゆる業務環境でインサイトを取得: Microsoft 365 用の Tableau アプリ登場
 2026/03/16
2026/03/16
今あるものから始まるエージェンティック エンタープライズ構築
 2025/10/15
2025/10/15