Koppel Tableau en Python voor voorschrijvende analyse met TabPy



Dit blogbericht is al eens eerder gepubliceerd in Medium.
TabPy is een Python-pakket waarmee je Python-code direct kunt uitvoeren en resultaten kunt weergeven in Tableau-visualisaties, zodat je snel geavanceerde analysetoepassingen kunt implementeren. De tweezijdige oplossing van TabPy biedt het beste van twee werelden: toonaangevende datavisualisatiemogelijkheden én krachtige data science-algoritmen. Het gebruik van Python-algoritmen in Tableau heeft als groot voordeel dat gebruikers de parameters kunnen aanpassen en de impact hiervan op de analyse in real time kunnen evalueren wanneer het dashboard wordt bijgewerkt.
TabPy maakt hierbij vooral gebruik van een input/output-methode waarbij de data worden geaggregeerd volgens de bestaande visualisatie en de parameters voor aanpassingen worden overgedragen naar Python. De data worden verwerkt en de output wordt teruggestuurd naar Tableau om de huidige visualisatie bij te werken. Maar stel dat je de volledige onderliggende dataset nodig hebt voor een berekening terwijl op je dashboard slechts een geaggregeerde meetwaarde wordt weergegeven, of dat je meerdere aggregatieniveaus tegelijkertijd wilt weergeven. Of mogelijk wil je meerdere databronnen in één enkele berekening gebruiken zonder de responsiviteit van je dashboard aan te tasten.
In dit bericht laat ik je zien hoe je TabPy in de volgende scenario's optimaal kunt benutten:
- Realtime interactie: Je wilt een realtime gebruikersinterface, met een zo kort mogelijke verwerkingstijd en zo min mogelijk vertraging tussen de wijziging van een parameter en de resulterende weergave van de visualisatie.
- Meerdere aggregatieniveaus: Je wilt (meerdere) aggregatieniveaus weergeven in dezelfde Tableau-dashboards, maar je moet alle berekeningen uitvoeren tot op het meest precieze en meest gedetailleerde niveau, dat alle informatie bevat.
- Verschillende databronnen: De backendberekening is afhankelijk van meer dan een enkele databron en/of database.
- Dataoverdracht tussen Tableau en Python: Er is een aanzienlijke hoeveelheid data nodig voor elke optimalisatiestap, dus er moeten veel data worden overgedragen tussen Tableau en de Python-backend.
Een nieuwe TabPy-oplossing voor voorschrijvende analyse: Stapsgewijze instructies
Als je zowel Python als TabPy al hebt geïnstalleerd, kun je TabPy implementeren in drie stappen:
- Maak een concept voor een Tableau-dashboard
- Maak een backend voor berekeningsroutines in Python
- Gebruik deze om de Tableau-frontend te ontwerpen
Ik zal nu de drie stappen toelichten door middel van een use case dat als doel heeft de complexiteit te reduceren via productportfolio-optimalisatie.
De use case: Reductie van de complexiteit
De optimalisatie is voor een B2B-retailer die vooral is gegroeid door fusies en overnames. Vanwege deze anorganische groei heeft de retailer te maken met veel complexiteit: activiteiten in verschillende markten en een portefeuille van duizend SKU's onderverdeeld in verschillende categorieën en subcategorieën. Wat alles nog ingewikkelder maakt, is dat de SKU's worden gebouwd in verschillende installaties.
Het senior management van het bedrijf wil de marges vergroten door de minst winstgevende SKU's af te stoten, maar is bereid minder presterende items te blijven verkopen om een bepaald marktaandeel te behouden. De managers zijn ook bereid om de installaties boven de streefwaarde voor assetgebruik te laten draaien, in de wetenschap dat een te sterke verlaging van het gebruik een negatieve invloed zal hebben op de vaste-kostenbasis van elke installatie.
De data in dit voorbeeld bestaan uit een database op SKU-niveau waarin jaarlijkse volumes, kosten en opbrengsten worden gerapporteerd. De SKU's zijn georganiseerd in hiërarchische niveaus van categorie en subcategorie.
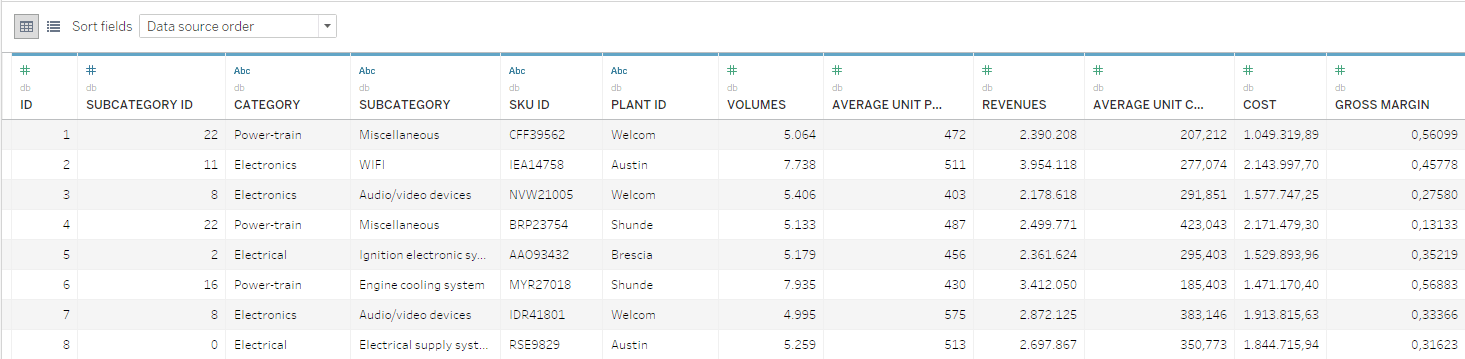
Vanuit wiskundig perspectief is de taak voor beheer van productportfolio-optimalisatie vrij eenvoudig. Bij de optimalisatie moet echter ook rekening worden gehouden met alle strategische aspecten en de diverse belanghebbenden die toegang hebben tot de informatie en de hulpmiddelen die nodig zijn om goed onderbouwde beslissingen te nemen.
De hieronder beschreven TabPy-benadering voldoet aan al deze vereisten.
1. Maak een concept voor een Tableau-dashboard
Dit moet zijn afgestemd op het probleem dat je wilt oplossen. In dit voorbeeld gebruiken we een eenvoudig optimalisatiealgoritme waarmee SKU's worden afgestoten op basis van de brutomarge op SKU-niveau.
-
Definieer de interactieve parameters in Tableau: Voor het gemak hebben we hier een tweede parameter gedefinieerd. Dit is de map waarin het Python-pakket met de optimalisatieroutines wordt opgeslagen. Dit type parameter is erg handig bij het definiëren van de aangepaste berekeningen, zoals we later zullen zien.
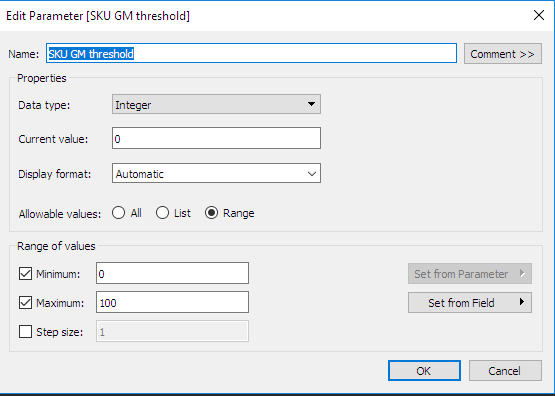
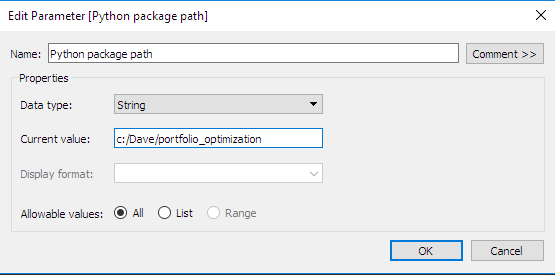
- Definieer de weergaven/aggregatieniveaus: Hier definiëren we twee aggregatieniveaus: een SKU-niveau en een subcategorieniveau. De definitie van aggregatieniveaus is essentieel omdat hiermee de handtekeningen van de Python-backendfuncties worden bepaald. Er moet voor elke berekening en elk aggregatieniveau een specifieke functie worden gedefinieerd. Voor elk aggregatieniveau moeten de volgende parameters worden gedefinieerd: geoptimaliseerde marges, geoptimaliseerde inkomsten en geoptimaliseerde volumes.
-
Definieer 'berekeningshooks' (callbacks) in Tableau: Wanneer de inputparameters, aggregatieniveaus en vereiste outputberekeningen zijn gedefinieerd, kunnen ook aangepaste berekeningen worden gedefinieerd. Voor het gemak zijn alle optimalisatieroutines gestructureerd in een Python-pakket voor portfolio-optimalisatie (portfolio_optimization), waarbij we functies hebben gedefinieerd om de geselecteerde hoeveelheden voor de specifieke aggregatieniveaus te retourneren. De eerder gedefinieerde parameter (het Python-pakketpad) wordt hierbij doorgegeven aan de functie en in het script gebruikt om aan te geven waar het portfolio-optimalisatiepakket is opgeslagen. Daarnaast wordt de huidige indexeerfunctie voor het aggregatieniveau (bijvoorbeeld voor het aggregatieniveau van de subcategorie, ofwel de subcategorie zelf) altijd doorgegeven aan de Python-backend om ervoor te zorgen dat de resultaten in de juiste volgorde worden geretourneerd. De inputparameter SKU GM-drempel wordt ook doorgegeven.
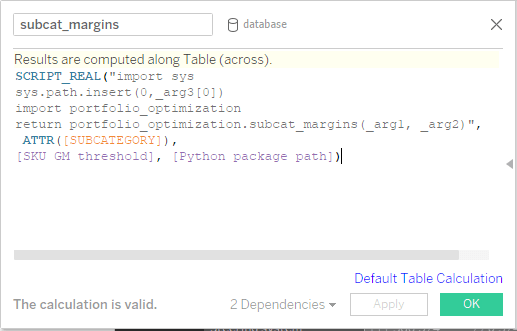
2. Maak een backend voor berekeningsroutines in Python
De Python-backend is verdeeld in twee functieklassen, gegroepeerd op basis van de uitvoeringscontext: functies die één keer worden uitgevoerd en functies die meerdere keren worden herhaald. De eerste klasse omvat bijvoorbeeld database-extractie en transformatie- en laadbewerkingen. Dergelijke functies worden 'eenmalige bewerkingen' genoemd. Daarnaast zijn er de functies die meerdere keren worden uitgevoerd, zoals alle Tableau-callbacks:
- Eenmalige bewerkingen: In dit voorbeeld wordt de database slechts eenmaal geladen, wanneer het script voor het eerst wordt uitgevoerd. De database wordt vervolgens via een globale variabele beschikbaar gemaakt voor alle andere functies. In Python wordt de lokale naamruimte gecontroleerd om te detecteren of er al een kopie van de database is geladen. Zonder deze voorzorgsmaatregel zou de database steeds worden geladen wanneer in Tableau een berekening wordt aangevraagd, wat de uitvoeringssnelheid hindert.
- Tableau-callbacks: Elke eerder gedefinieerde hook moet een bijbehorende functie hebben. Wij doen dit hier door afzonderlijke berekeningen voor inkomsten, volumes en marges in te voeren en door de indexeerfunctie die is doorgegeven als input voor de functie, te gebruiken voor indexering van de Pandas-functie groupby, die vervolgens wordt gebruikt om optimalisatieresultaten te aggregeren. Voor een hogere uitvoeringssnelheid wordt bij de callbacks een detector voor parameterwijzigingen geïmplementeerd. Een nieuwe optimalisatie wordt alleen gegenereerd als de parameter wordt gewijzigd en het resultaat ervan beschikbaar is voor alle callbacks die gebruikmaken van een globale variabele. De detectie van een parameterwijziging wordt geïmplementeerd via een persistente variabele die wordt gebruikt om de waarde van de vorige uitvoering op te slaan. Door deze methode wordt slechts een minimaal aantal dure bewerkingen uitgevoerd en wordt de uitvoeringssnelheid verbeterd.
3. Ontwerp de Tableau-frontend
Voor deze stap zijn alle fundamentele bouwstenen al gedefinieerd, inclusief aggregatieniveaus, aan te passen parameters en outputkolommen die worden geretourneerd door de backend van de berekening.
Voor eenvoudiger inzicht in de optimalisatie definiëren we twee afzonderlijke werkbladen waarin de portfolio voor en na het optimalisatieproces wordt getoond. Geef de twee werkbladen naast elkaar weer.
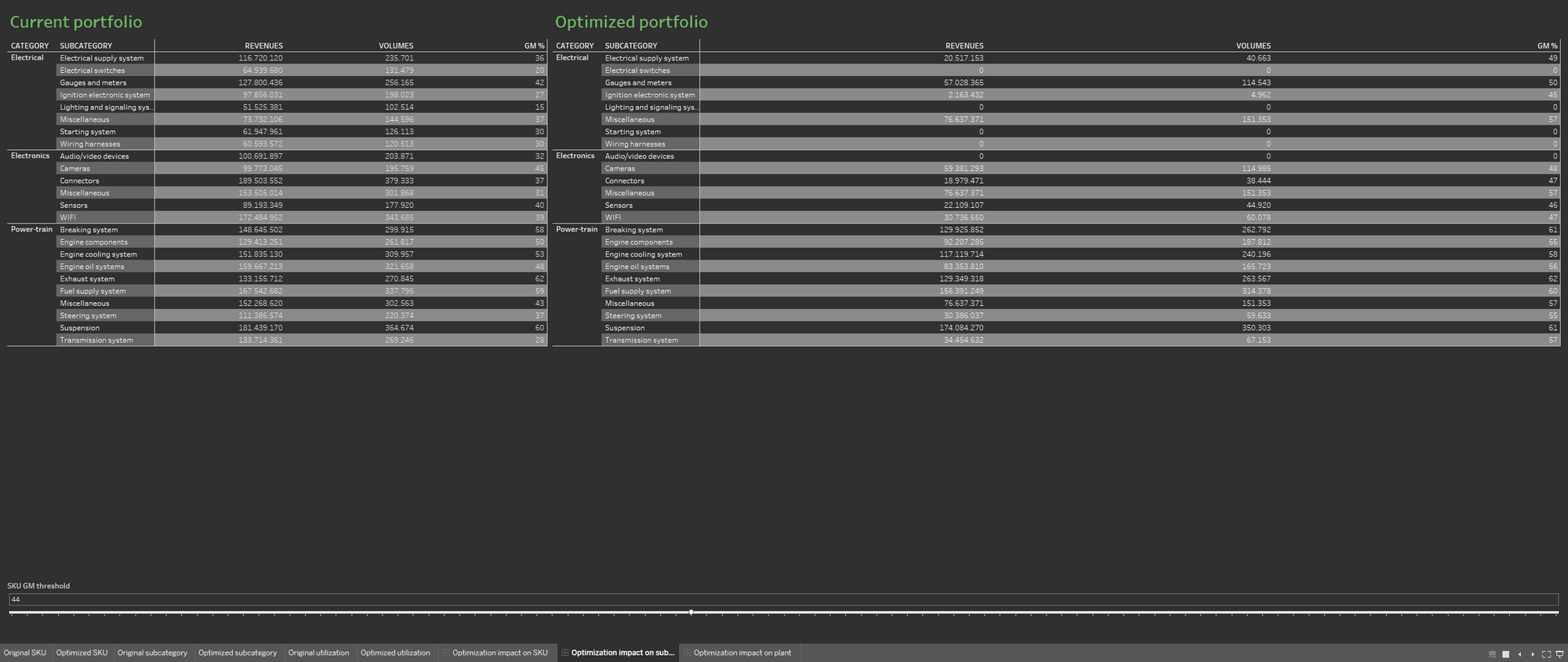
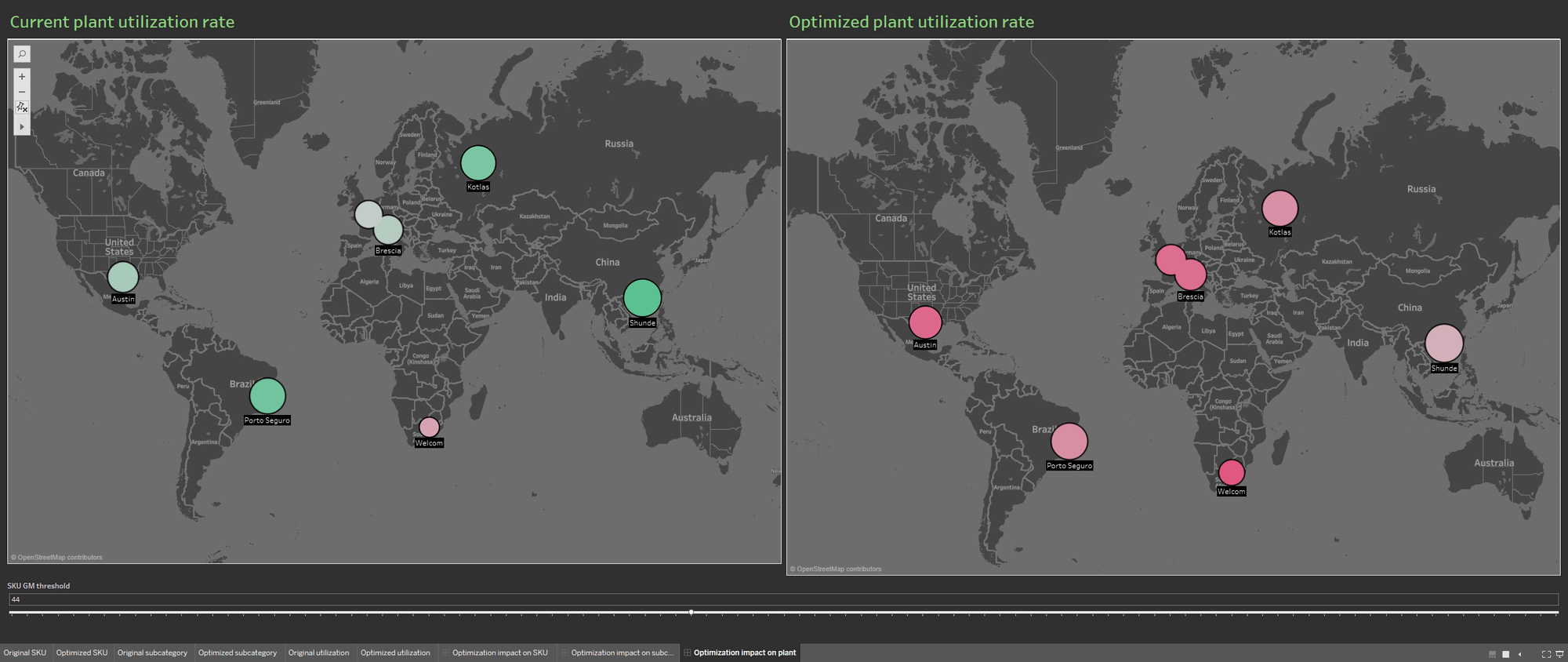
Door de beschikbaarheid van meerdere databronnen wordt de portfoliodatabase verrijkt: de visualisatie wordt gevuld met informatie over de huidige bezettingsgraad van de installatie en de bezetting die voortkomt uit een geoptimaliseerde portfolio. De twee informatievisualisaties worden naast elkaar weergegeven om de impact van de optimalisatie op de productie-installaties beter te demonstreren.
Meer voordelen van het gebruik van TabPy binnen teams
Naast de aanzienlijke zakelijke waarde van teams die in real time kunnen inspelen op krachtige data science-technieken, biedt deze nieuwe oplossing ook belangrijke voordelen voor de backend. Veel andere datavisualisatietechnieken moeten tijdens het hele proces worden begeleid door datawetenschappers en dit kan aardig in de papieren lopen. Met deze oplossing zijn datawetenschappers echter alleen nodig om het concept voor het Tableau-dashboard voor te bereiden en de berekeningsroutines voor de Python-backend te maken. Door het gebruiksgemak van Tableau kunnen veel meer personen de frontend ontwerpen, testen bij de eindgebruikers, en onderhouden.
Frontend-ontwerp is meestal een langdurig en iteratief proces waarbij meerdere discussies met de eindgebruikers nodig zijn. Met de nieuwe TabPy-oplossing kan de kostenefficiëntie aanzienlijk worden verbeterd doordat managers de teamsamenstelling kunnen variëren tijdens de uitvoering van het project. Deze oplossing zorgt er ook voor dat de onderliggende backend opnieuw kan worden gebruikt, zodat meer gebruikers hun eigen aangepaste dashboards in Tableau kunnen bouwen voor specifieke contexten, doelgroepen en situaties. Dit hergebruik van berekeningslogica en de onderliggende fundamentele bouwstenen is ook weer een manier om de totale kosten van datavisualisatie te verbeteren.
Als je meer wilt weten, dan kun je hier zowel het Tableau-dashboard als de Python-backend raadplegen. Voor meer informatie over deze oplossing kun je terecht bij de officiële TabPy Github-repo of deze Tableau Community-thread.
Verwante verhalen

VizQL Data Service: Extend Your Data Beyond Visualizations
 19 maart, 2025
19 maart, 2025
VizQL Data Service from Tableau: Use Your Data, Your Way
 8 augustus, 2024
8 augustus, 2024

When and How to Use Multi-fact Relationships in Tableau
 1 augustus, 2024
1 augustus, 2024