
Hadoop とビッグデータは密接に関連しており、同時に言及される場合がほとんどですが、そうでない場合でも常に近くに存在しています。ビッグデータに関しては、広範囲のデータが含まれるため、ほぼすべての情報が相互に関連している可能性があります。ビッグデータは、現代のデジタル世界で取り組まなければならない分野として、急速に台頭しています。Hadoop はそのデータから答えを見つけ出す 1 つの方法にすぎません。
データを可視化してビジネスを加速!
Hadoop とは
Hadoop はオープンソースのフレームワークであり、大量のデータを保存して解析するすべてのコンポーネントに対応することを目的としています。これは、汎用的でアクセシブルなソフトウェアライブラリアーキテクチャであり、低コストで導入して、必要に応じて分析できるため、ビッグデータを処理するにあたって魅力的な方法です。
Hadoop の歴史は、2000 年代初期にさかのぼります。より高速に検索結果を表示する検索エンジンインデックス作成の一環として、開発されました。同時期に、Google も発展しつつありました。Google は革新的な Web 検索で開始しましたが、Hadoop はテクノロジーアーキテクチャ内に新たな機会を見出し、データの保存と処理の技術的側面に焦点を当てました。このプロジェクトは、開発者の息子が持っていたおもちゃの象の名前にちなんで「Hadoop」と名付けられました。
データを可視化してビジネスを加速!
こちらの記事を見た方は、下記のページにも興味をお持ちです。
Hadoop 登場の背景
Hadoop の登場には、検索エンジンの開発の歴史が背景にあるといえます。検索エンジンは、1990 年代終わり頃から、高性能なシステムの開発が進められてきました。その結果、検索エンジンでは、インターネット上の HTML や PDF などの大量の文書を収集する「Web クローラー」が常に稼働しています。また、検索結果を高速に表示するために、「インデックス」を作成して設置しています。
この「インターネット上の大量文書を集めてインデックスを作る」という、一連の作業を実行するために考え出されたのが、「データを分割して複数のコンピューターで計算し、同時並行的に処理する」という方法です。2000 年代初め頃は Nutch と呼ばれるオープンソースの検索エンジンにこの技術が用いられました。
やがて 2006 年頃に Nutch プロジェクトは分割されます。Web クローラーの部分は Nutch として残り、分散コンピューティング環境における並列動作という部分が Hadoop となりました。
そして 2008 年、Hadoop はオープンソースのプロジェクトとして公開されます。Hadoop は、あらゆる種類の大量のデータを高速に、しかも低コストで保管・処理することができるフレームワークです。また、そのコンピューティングモデルは、データを最大数千台のコンピューターで分散並列処理することで、必要に応じてノード(コンピューター)を追加するだけで順次処理能力を拡大(スケールアウト)させることができます。
2010 年頃にはビッグデータが注目されるようになり、膨大でさまざまな種類のデータを処理するという需要が生まれます。そこで Hadoop の技術も注目を集めることとなりました。ビッグデータを扱うために、大量のデータを格納して分散処理できる Hadoop の性能が活用されるようになったのです。
データを可視化してビジネスを加速!
Hadoop の仕組み
Hadoop は大規模なデータを並列分散処理するフレームワークです。そのベース部分は大きく分けて MapReduce(分散処理エンジン)、HDFS(ファイルシステム)、Hbase(データベース)という 3 つのコンポーネントから成り立っています。下記で紹介する、これら 3 つのコンポーネントを組み合わせることで、ビッグデータのような膨大なデータを処理することを可能にしているわけです。
MapReduce(分散処理エンジン)
分散処理エンジンである MapReduce は、大規模なデータを効率的に分散処理するためのプログラミングモデルでありフレームワークです。そもそもは Google が検索結果の分析のために最初に使用したもので、その Google が 2004 年に発表した論文中で、MapReduce の詳しい仕組みが解説されました。
一方、オープンソースの検索エンジンだった Nutch は、1 台のコンピューター上では問題なく動作していたものの、何百万ものインターネット上の文書を処理するという点で課題を抱えていました。MapReduce の仕組みは、その課題に対し申し分のない解決策を提供するものだったのです。そこで 2005 年には早くも MapReduce が Nutch に統合され、さらにその後、Hadoop プロジェクトとして発展していきます。
Hadoop において、MapReduce はファイルシステムまたはデータベースに格納されたデータにアクセスするために使用されます。例えばファイルシステムである HDFS 上の、数百万行の文書ファイルにアクセスし、数十台のコンピューター(サーバー)で分散処理して、文書に登場する単語の数を結果として導き出して生成する、といったことを行います。MapReduce であれば、ペタバイト規模のデータであっても小さなチャンクに分割し、ノードの数を増やして同時に並列処理することができます。その後、すべてコンピューターからデータを集約、統合してアプリケーションに返します。
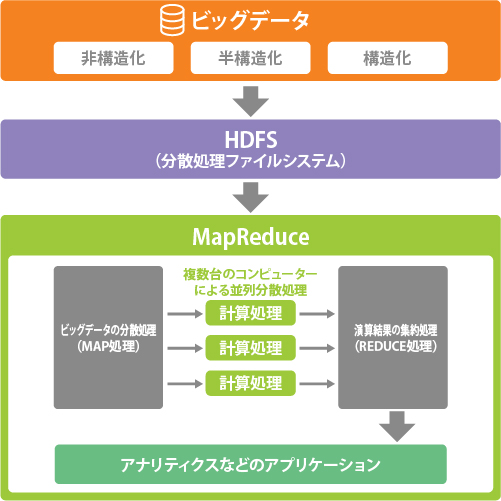
HDFS(分散処理ファイルシステム)
HDFS は、分散処理ファイルシステムのことです。その特徴は、複数のコンピューターのローカルディスクを、あたかも1つのストレージのように扱って管理できることにあります。大容量のデータファイルを、一定の大きさのブロックに分割して配置し、複数のストレージに分散して保存します。さらに読み込みや書き込みを並列で実行できるため、アクセススピードも高速です。
ユーザーは通常のローカルディスクを扱うのと同じように HDFS を利用できるため、データが分割されていることを意識するようなことはほとんどありません。
Hbase(データベース)
Hbase は、HDFS 上に構築された、列指向の分散型データベース管理システムのことです。よく知られているリレーショナル型とは異なる構造を持つ、NoSQL 型システムの代表格です。
Hbase は分散コンピューティング環境を前提に設計されており、シャーディングと呼ばれるデータを複数のノードに分散して記録する処理を自動的に行います。高い拡張性、リアルタイムスピード、柔軟性を持ち、負荷に対してスケーラブルに対応できることも特徴です。
データを可視化してビジネスを加速!
Hadoop の役割とあらゆるところで使われている理由
Hadoop は、保存されたデータを解析するために連携するパーツの集合体です。次の 4 つのモデルで構成されます。
- Hadoop Common: 大半のユースケースをサポートする基本的なユーティリティ
- Hadoop 分散ファイルシステム (HDFS): アクセスしやすい形式でデータを保存する
- Hadoop MapReduce: 大規模なデータセットをマッピングしてデータを処理した後、絞り込んで特定の結果を表示する
- Hadoop YARN: リソースとスケジューリングを管理する
Hadoop はアクセシブルで導入が簡単なため、広く利用されています。手頃な価格で便利なほか、多くのオプションを提供するモジュールが搭載されています。Hadoop は複数のマシンによる拡張が簡単にできるため、ほぼどのようなサイズのデータセットにも対応できます。また、それが採用するデータを保存して処理する方法により、Hadoop は、拡張し続けるデータストレージを可能とする、魅力的なエンタープライズソリューションとなります。
Hadoop を使用して、ハードウェアの柔軟性と低コストな分析を実現
大量のデータを保存する場合、その負荷に対応するためのリソースとハードウェアの維持管理に多額のコストが発生するという問題に直面します。Hadoop が広く普及して採用されている理由は、はるかにアクセシブルで、ハードウェアを柔軟に使用できるためです。Hadoopは、「コモディティハードウェア」を採用しています。これは、すぐに使える低コストのシステムを意味します。Hadoop の実行には、独自のシステムや高価なカスタムハードウェアは不要であるため、低コストで運用できます。
Hadoop では、データを処理するにあたって、高価なハードウェアに依存することなく、複数のマシン間で処理能力を分散させます。このシステムは、ほぼあらゆるサイズのデータセットに対応するように拡張できます。Hadoop を使用すると、IT のカスタムニーズに最適な数と種類のハードウェアを購入できるため、多くの場合、IT プロフェッショナルがこの構造のメリットを最も活用することができます。
データウェアハウス(DWH)とデータレイクでのデータの保存
Hadoop は処理能力を分散させるだけでなく、データの保存方法と分析方法を変革します。
従来、データは「データウェアハウス」に保存されていました。名前が示すように、データウェアハウスは、情報に基づいて保存および整理されたデータセットの大規模な集合体です。アナリストはその後、これらの新たに保存された表とデータセットにアクセスします。これらは構造化されており、データは必要に応じてアクセスできるようにパッケージ化されています。この際、すべてのデータを分析して適切に保管し、必要なときに呼び出せるようにしなければなりません。
データウェアハウスシステムは、特定の表にアクセスするユーザーにとっては便利ですが、事前に実施する分析や保存に時間がかかり、リソースを大量に必要とする可能性があります。さらに、データウェアハウスを誤用した場合、効率の低下につながります。すぐに使用されないデータや明確な役割がないデータは、忘れられてしまったり、分析から除外されてしまったりする可能性があります。ストレージを拡張していくことで、コストが高額になる可能性があります。アナリストや IT プロフェッショナルがデータウェアハウスの構造上のメリットを活用するには、データウェアハウスを拡張するための意図的な戦略が必要となります。
一方、データレイクは対極の存在です。データウェアハウスが制御およびカタログ化されているのに対して、データレイクはすべてのデータが自由に流れる巨大なダンプとなっています。分析や使用の対象であるか、いつか使用される可能性があるかどうかにもかかわらず、すべてのデータが保存されます。データは未加工の形でインポートされ、必要な場合にのみ分析されます。Hadoop はハードウェアの面で非常に経済的であるため、大量のデータを保存または分析する際に、必要に応じて簡単に拡張できます。ただし、これはデータウェアハウスの主なメリットである、事前にパッケージ化された表と承認済みのデータセットをいつでも使える状態に維持することが難しくなります。データレイクを拡張することは、ガバナンス戦略と教育の拡張を意味します。
これらのデータの保存方法には、いずれも独自のメリットがあります。企業は大抵、さまざまなデータニーズに対応するため、データウェアハウスとデータレイクの両方を使用しています。
データを可視化してビジネスを加速!
IoT(モノのインターネット)での Hadoop の役割

Hadoop が提供するソリューションの 1 つは、ストレージと膨大な量のデータを分析する機能です。ビッグデータはますます大きくなり続けています。5 年前には、現在の規模の半分を若干上回るくらいのデータが作成されていました。そして、15 年前に 24 時間で作成されていたデータ量は、現在約 3 分間で作成されているデータ量を下回っています。
このデータ生成における大幅な増加は、「モノのインターネット」、略して IoT と呼ばれるテクノロジーの波が大きな理由となっています。これは、日常にある物がインターネットに接続され、インターネット経由で操作できる環境を指します。初期には、スマートフォン、スマートテレビ、アラームシステムなどが登場しました。今では、インターネット対応の冷蔵庫、食器洗い機、サーモスタット、電球、コーヒーメーカー、セキュリティカメラ、ベビーモニター、ペットモニター、ドアロック、掃除機ロボットなどのスマート家電に移行しています。これらの家電は生活の利便性を向上しながら、実行されるあらゆる操作についてのデータを追跡して保存します。
IoT はまた、専門家、企業、政府にも導入されています。建物を効率的に運用するスマートエアコンや、警察官と民間人の安全を保護するボディカメラのほか、政府が地震や山火事など、自然災害に迅速に対応するための環境検知装置などがあげられます。
総括すると、これらの機器はすべて、膨大な量のデータを記録するにあたって、柔軟に監視を行い、手頃なコストで拡張できる必要があります。そのため、Hadoop などのシステムは多くの場合、IoT データを保存するうえで重要なソリューションとなっています。Hadoop は唯一の選択肢ではありませんが、拡大し続ける IoT 需要により、最も普及されていると言えます。
データを可視化してビジネスを加速!
効果的に運用できれば便利なビッグデータストレージ
ビッグデータが大きくなるにつれて、データを効果的に保存できるだけでなく、効果的に使用されるようにする必要があります。世界中のすべてのデータを保存できますが、無意味に価値のないデータを集めるだけでは無駄になります。Hadoop は他のデータストレージ方法よりも優れていますが、データストレージはデータ分析やビジネスインテリジェンスに代わるものではありません。
大量のデータを収集すれば、その分ストレージのコストが上がります。また、そのデータを使用してインサイトや価値を引き出さなければ、内実を伴わないデータ収集とストレージ戦略で、多額のコストを無駄にするだけです。わかりやすい例えとして、金鉱採掘の観点でデータについて考えることができます。金を採掘するために土地を購入しても、実際に採掘しなければ、大金を無駄にするだけです。広く採用されている Hadoop などのシステムでは、その土地を少し安く購入できるということにすぎません。
企業成長を加速させる BI ツールを導入しましょう!
自分のデータから価値ある情報を引き出そう!

データ分析を簡単にする Tableau でデータの価値を最大化しましょう! Tableau の無料トライアルを今すぐお試しください。
Tableau 無料トライアルをダウンロードHadoop の将来性
Hadoop はこれまで、大規模データを生成する多くの有名IT企業で利用されてきました。Hadoop の 1.0 がリリースされた 2011 年 12 月以降はさらに普及が進み、2019 年にはその市場規模は 267億4,000 万ドルだったと評価されています。
しかし現在では、Hadoop の主要技術である MapReduce の、後発ともいえる分散処理エンジンがいくつも現れています。Hadoop に続く高速化された分散処理のフレームワークとして、Spark の名前を聞いたことがある人も多いでしょう。
また、近年のクラウドサービスの爆発的な広がりも影響を与えています。オンプレミス環境が主流だった時代に普及した Hadoop をそのまま利用し続けるのは、時代にマッチしなくなってきているのです。例えば、オンプレミスで大規模なデータレイクを構築し、Hadoop をミドルウェアとして使うには、多くの社内リソースを要します。
それでも、Hadoop の並列分散処理技術の有用性は現在でも高く評価されています。前項で解説したように、IoT データの格納先やビッグデータストレージとして Hadoop はなおも主要な選択肢の 1 つとなっています。オンプレミス環境での Hadoop 利用を必要とする企業も一定数存在します。
一方、Amazon EMR や Azure HDInsight などのメジャーなベンダーが提供するクラウド型 Hadoop サービスも登場しています。クラウド化は、Hadoop の利用形態を大きく変化させる要因の 1 つとなっています。今後、クラウド内にデータレイクを構築し、機械学習などを駆使してさまざまなデータを分析するような形態は、さらに当たり前のものとなっていくでしょう。そこで Hadoop が依然、有力な技術として生き残り、活用される可能性も十分に考えられます。
企業成長を加速させる BI ツールを導入しましょう!
Hadoopの新しい役割に注目を
2000 年代初期に生まれた Hadoop は、大規模なデータを並列分散処理する魅力的なフレームワークとしてその名を知られ、すぐにビッグデータを処理する基盤として利用されるようになりました。
多くの企業がオンプレミス環境に Hadoop 処理系を用いたデータレイクを構築し、増え続ける大量のデータを保存し、データを分析してビジネスに役立てるようになりました。この事実は、Hadoop が新しいデータ活用の時代を支えてきた技術の 1 つであることを示しています。
そして現在は、IoT が人々の生活に近いところで利用され始め、機械学習などの新しい分析アプローチも身近なものとなっている時代です。ビッグデータやデータ活用の領域ではめまぐるしい変化が起きています。その中で Hadoop がどのような新しい役割を果たしていくのか、クラウド化によってこれまでとはまた違った能力を発揮していくのか、目を離すことなく注目していくべきです。
企業成長を加速させる BI ツールを導入しましょう!
Tableau は、様々な日本企業にご導入いただいております
すべてのカスタマーストーリーはこちらからご覧ください。


