Hinter den Kulissen der Tableau Kino Tour – Teil 2: Die Filmreihen




tl;dr - Die Tableau Kino Tour 2017 begeistert die Besucher mit Visualisierungen rund um Film und Fernsehen. Dabei kommt immer wieder die Frage nach den Daten, die hinter den gezeigten Dashboards stecken. Dies ist Teil 2 einer Schritt-für-Schritt-Anleitung und behandelt die Analyse der Filmreihen.
Dieser Beitrag erschien ursprünglich am 26. Januar 2017 auf konstantingreger.net.
Im letzten Quartal 2016 haben wir als würdigen Nachfolger der Tableau Stadion Tour 2015/16 die Tableau Kino Tour 2016/17 aus der Taufe gehoben. Nach bisher sehr erfolgreichem Tourverlauf befinden wir uns mit drei verbleibenden Terminen in Hamburg, Köln und München auf der Zielgeraden.
Da immer wieder die Frage nach den Daten kam, die hinter der Kino Tour stecken, und auch weil es tatsächlich ein sehr interessantes und spaßiges Projekt war, diese Daten zu generieren und analysieren, habe ich die einzelnen Schritte vom Download der Quelldaten bis zum fertigen Produkt zusammengefasst. Aus Copyright-Gründen dürfen wir die fertigen Daten leider nicht einfach so zum Download anbieten, aber mit der Schritt-für-Schritt-Anleitung sollte es nicht allzu schwierig sein, das zuhause selbst nachzustellen.

Tableau Kino Tour
Dies ist der zweite Teil in einer dreiteiligen Serie zu den technischen Hintergründen der Tableau Kino Tour. Teil 1 beschäftigt sich mit dem Auslesen und Nutzbarmachen der IMDb-Daten, hier geht es um Filmreihen, der dritte Teil wird sich mit den Daten zum “Tatort” beschäftigen.
In den letzten Jahren wurde es unter Filmstudios und Produzenten immer populärer, einen oder meist gleich noch mehrere Teile nachzuschieben, sobald ein Film erfolgreich war. Neudeutsch spricht man dann von einem Franchise – um nicht zu sehr in Anglizismen zu verfallen sprechen wir im Kontext der Tableau Kino Tour lieber von Filmreihen. Die Idee ist ja an sich auch nichts neues, mehrteilige Filme oder Fortsetzungen gibt es schon sehr lange. Man denke nur an “Star Wars”: Der erste Film 1977 wurde noch als einzelnes Werk konzipiert, dann wurden nach dem großen Erfolg zwei weitere Teile produziert, 16 Jahre später nochmals drei Teile, und dann wiederum 10 Jahre später nochmals drei Teile – wovon bisher allerdings erst einer tatsächlich veröffentlicht wurde, auf die restlichen beiden müssen wir uns noch ein wenig gedulden.
Im Zusammenhang mit “Star Wars” bietet es sich auch an, gleich noch zwei Fachtermini zu erklären: Da wäre einerseits das Sequel, also die Fortsetzung – hier steht der spätere Film inhaltlich-chronologisch nach dem früheren Film. Beispiele hier sind Star Wars Episoden 5 und 6, die, bezogen auf die Story, nach Episode 4 stattfinden. Andererseits gibt es das Prequel, also den Vorläufer – hier steht dementsprechend der spätere Film inhaltlich-chronologisch vor dem älteren Film. Beim Beispiel “Star Wars” wiederum sind die Episoden 1-3 Prequels zur Original-Saga.
Dann gibt es Filme, bei denen ursprünglich gar nicht geplant war, mehrere Teile zu produzieren. Um das Beispiel “Star Wars” nicht zu überstrapazieren: “Zurück in die Zukunft” war im Original nur ein Film, erst der große Erfolg hat dazu geführt, dass noch zwei weitere Drehbücher geschrieben wurden. Und selbstverständlich gibt es Mehrteiler, die einfach aufgrund der umfangreichen Originalvorlagen in mehreren Teilen produziert wurden. Beispiele hierfür sind die “Herr der Ringe”-Trilogie oder auch die einzelnen “James Bond”-Filme.
Aber genug der grauen Theorie! Ein weit verbreitetes Vorurteil bei Filmreihen ist, dass eigentlich immer nur der erste, also der originale Teil wirklich gut ist, die Fortsetzungen dagegen immer schlechter werden. Im Rahmen der Kino Tour haben wir also unter anderem die Frage gestellt: Ist bei Filmreihen immer der erste Film der Beste? Leider enthalten die IMDb-Daten (s. Teil 1 dieser Reihe) keine Informationen zu mehrteiligen Filmen bzw. solchen Franchise-Serien. Hier war also initial einiges an Handarbeit notwendig, um verwertbare Daten zu erstellen. Dass dies zu einer gewissen portion Subjektivität führt und natürlich auch im Ergebnis nicht ganz fehlerfrei ist, sei uns bitte nachgesehen. Das Gute am Offenlegen unserer Arbeit und Daten ist ja, dass jede/r filmverrückte Daten-Geek den Datensatz selbst erweitern und korrigieren kann.
Schritt 1: Die zu untersuchenden Filmreihen zusammenstellen
Alles ging also damit los, dass wir uns eine Liste von Filmreihen zusammengeschrieben haben, die wir gerne analysieren wollten. Ursprünglich war sie noch viel länger, aber für die folgenden haben wir dann tatsächlich Daten gesammelt:
Wir verwenden hier die englischen Namen der Reihen, und im weiteren Verlauf auch die englischen Originaltitel der Filme, da uns das die Arbeit mit den IMDb-Daten erheblich vereinfacht. Es gibt dort zwar auch eine Tabelle mit den deutschen Filmtiteln (german-aka-film-titles.list.gz), aber die haben wir zum aktuellen Zeitpunkt nicht eingelesen und verarbeitet.
Schritt 2: Die Daten zu den Filmreihen zusammenfassen
Einführung
Die Informationen zu den Filmreihen und den einzelnen Filmen darin haben wir dann im Team verteilt (neudeutsch: crowdsourcing) von den jeweiligen Wikipedia-Seiten gesammelt. Zu jedem Film haben wir folgende Attribute gesucht:
Die meisten Felder sind selbsterklärend, mit “Ära” haben wir versucht, Eigenschaften der einzelnen Filme zu identifizieren, die es erlauben die Filme innerhalb einer Filmreihe zu gruppieren. Bestes Beispiel sind die verschiedenen Hauptdarsteller in den zahlreichen “James Bond”-Verfilmungen oder in den “Batman”-Filmen.
Das alleine war schon eine Menge Arbeit, aber in dieser Form konnten wir die Informationen leider noch nicht mit den IMDb-Daten zusammenbringen. Es fehlt der eindeutige Schlüssel. Natürlich könnte man über den Filmtitel und das Veröffentlichungsjahr eine solche Verbindung herstellen, aber jeder Hobby-Datenbankadministrator weiß, dass eine Schlüsselbeziehung zwischen zwei Relationen niemals über Textfelder gebildet werden sollte, sondern immer nur über einen eindeutigen Schlüssel. Glücklicherweise haben wir in unseren IMDb-Daten einen solchen Schlüssel, nämlich die idproductions in der Tabelle productions. Diese für alle 151 Filme herauszufinden ist nicht allzu lustig, der Prozess lässt sich aber mittels einer entsprechenden Tableau-Arbeitsmappe (Rechtsklick > Ziel speichern unter...) halbwegs schmerzfrei gestalten:
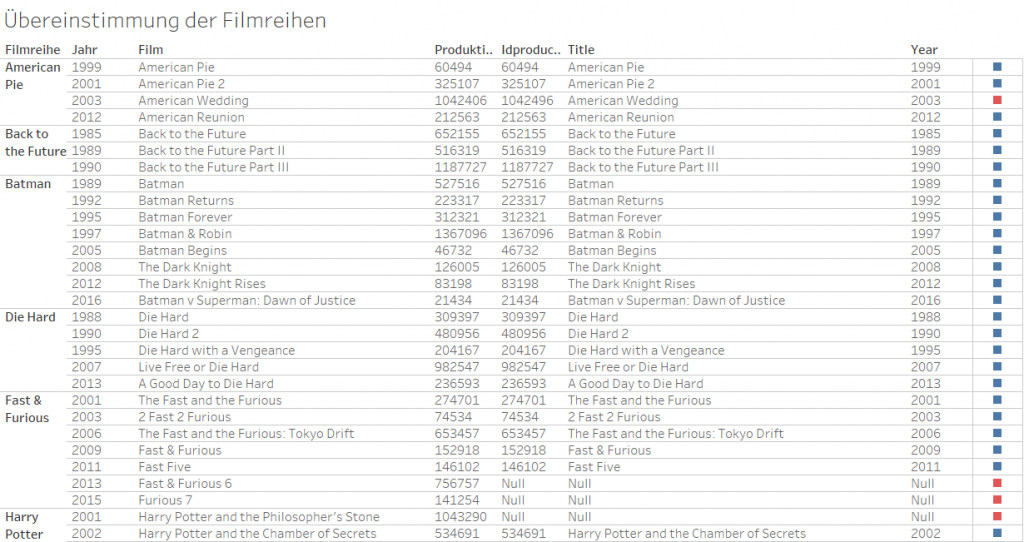
Tableau-Arbeitsmappe: Übereinstimmung der Filmreihen
Zugegeben, das Arbeitsblatt ist nicht schön, erfüllt aber seinen Zweck. Beim ersten Aufruf wird Tableau sowohl nach dem Speicherort der Datei sequels-de.txt (Rechtsklick > Ziel speichern unter...) fragen, als auch nach dem Passwort (oder insgesamt den Verbindungsparametern) zu PostgreSQL-Datenbank, in der die IMDb-Daten liegen. Hier haben wir genau die Verschmelzung hergestellt, von der ich ein paar Absätze weiter oben für den Produktiveinsatz abgeraten habe: Nämlich über die Filmtitel (Film in sequels-de.txt und Title in der Datenbank) sowie die Jahre der Veröffentlichung (Jahr in sequels-de.txt und Year in der Datenbank).

Verbindung zwischen der Datei SEQUELS-DE.TXT und der Film-Datenbank
Schritt 3: Fehler in den Daten korrigieren und korrekte IDs suchen
Das funktioniert in den meisten Fällen ganz gut, allerdings treten dabei auch Fehler auf:
Auftreten von NULL-Werten
Im oben gezeigten Beispiel passen u.a. offensichtlich die Titel der letzten beiden Teile der “Fast & Furious”-Reihe nicht, zudem wird auch der erste “Harry Potter”-Film nicht erkannt. Hintergrund ist hier, dass die Filme nicht nur in einzelnen Ländern unterschiedliche (lokalisierte) Titel tragen, sondern teilweise auch unter mehreren englischen Titeln laufen. So heißt beispielsweise der erste Harry Potter-Film (auf Deutsch “Harry Potter und der Stein der Weisen”) in den USA “Harry Potter and the Sorcerer’s Stone”, während er im Vereinigten Königreich unter dem Titel “Harry Potter and the Philosopher’s Stone” lief (s. die entsprechende Information auf der IMDb-Website). In der IMDb wird zumeist der US-amerikanische Titel geführt (Ausnahmen s.u.), von der Wikipedia-Seite hatten wir aber offensichtlich den britischen Titel übernommen. Das Problem lässt sich aber recht einfach beheben, indem wir den Titel in der Datei ersetzen, so wie er in den IMDb-Daten auftaucht. In der diesem Blog-Artikel zugehörigen Datei sequels-de.txt (Rechtsklick > Ziel speichern unter...) haben wir diesen Fehler natürlich schon behoben – sollte aber jemand noch zusätzliche Filmreihen oder Teile von fortgeführten Reihen einfügen wollen, könnte dieses Problem wieder auftauchen.
Ein bestimmter Film, dessen Titel nicht automatisch in unserer IMDb-Datenbank gefunden wurde, lässt sich mit folgender SQL-Abfrage finden:
SELECT * FROM productions WHERE title ILIKE '%furious%' AND episode_title IS NULL ORDER BY year
Da beispielsweise “Fast & Furious 6” nicht gefunden wurde, suchen wir nach “furious”. Der PostgreSQL-Befehl ILIKE erlaubt es uns dabei, unabhängig von Groß- und Kleinschreibung nach dem Begriff “furious” an beliebiger Stelle in den Filmtiteln (title) zu suchen. Zudem schließen wir der Übersichtlichkeit halber alle Fernsehserien aus (episode_title IS NULL), da wir uns hier nur für Filme interessieren. Bei Filmen ist der Folgentitel leer, also filtern wir nach NULL-Werten. Das Sortieren der Ergebnisse nach dem Jahr der Veröffentlichung (ORDER BY year) macht es uns dann noch einfacher, den gesuchten Film auch chronologisch richtig einzuordnen. Hier kommen zwar 61 Datensätze zurück, wir können den richtigen aber schnell identifizieren und so idproduction 577381 übernehmen.
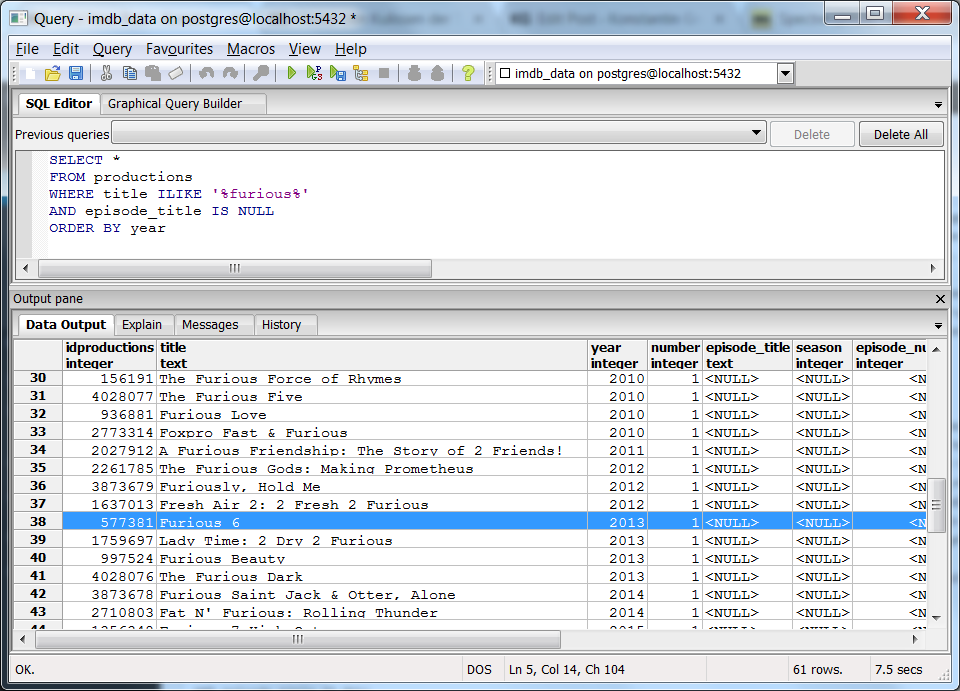
Abfrage nach Filmtiteln, die FURIOUS enthalten.
Auftreten von *
Da wir hier mit einer Datenverschmelzung in Tableau arbeiten, treten bei uneindeutigen Beziehungen die berühmten * auf. Hier beispielsweise beim “James Bond”-Film “Spectre” aus dem Jahr 2015. Dies kann passieren, wenn es zwei oder mehr Produktionen mit demselben Titel (hier “Spectre”) aus demselben Jahr gibt. Ob bzw. dass dies der Fall ist können wir auf zwei Arten überprüfen. Der einfachste Weg führt über die Original-IMDb-Website, die es erlaubt nur nach exakten Titel-Treffern zu filtern:
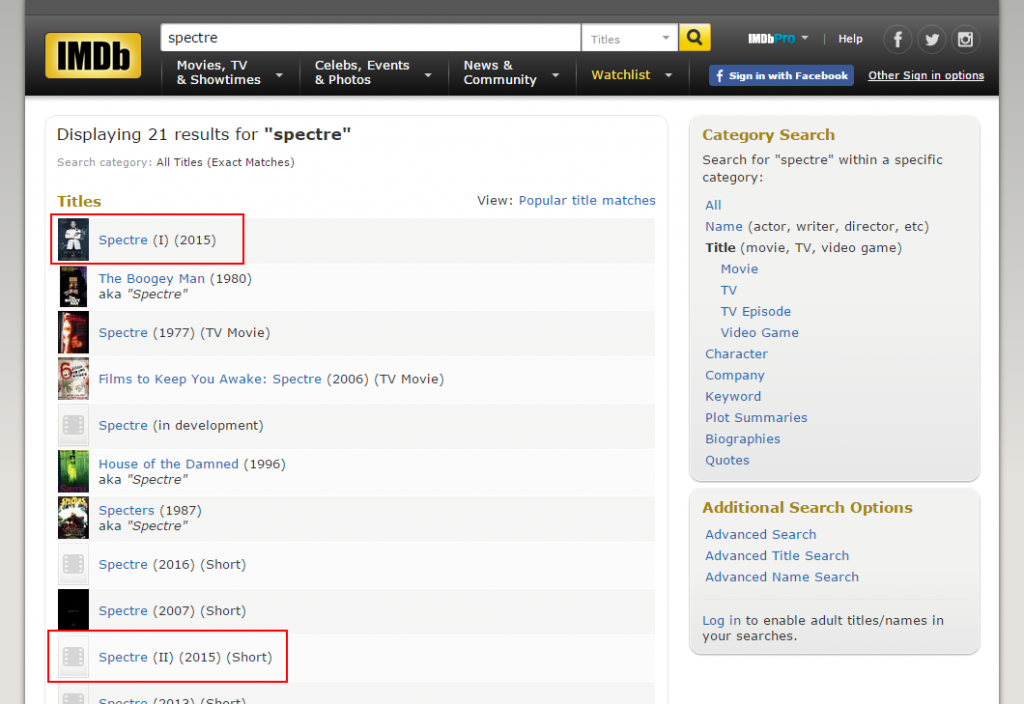
Exakte Titel-Treffer der IMDB-Datenbank für "SPECTRE”
Hier können wir auch sofort sehen, dass es sich bei dem gesuchten Film um den oberen Treffer handelt. Offenbar gibt es aber tatsächlich noch einen zweiten Film mit dem Titel “Spectre” aus dem Jahr 2015 – allerdings ein Kurzfilm. Da die IMDb-Extrakte, aus denen wir unsere Datenbank aufbauen, aber leider nicht die IMDb-IDs der Produktionen vorhalten (mehr dazu weiter unten), hilft uns das erstmal nicht weiter, da wir die korrekte idproductions immer noch nicht kennen. Diese verrät uns nur ein Blick in die Datenbank, beispielsweise mittels folgender Abfrage:
SELECT * FROM productions WHERE title = 'Spectre' AND year = 2015 ORDER BY year
Im gezeigten Fall liefert diese Abfrage dann zwei Treffer zurück (hier exemplarisch in pgAdmin III) – genau die, die wir schon auf der IMDb-Website identifiziert hatten:
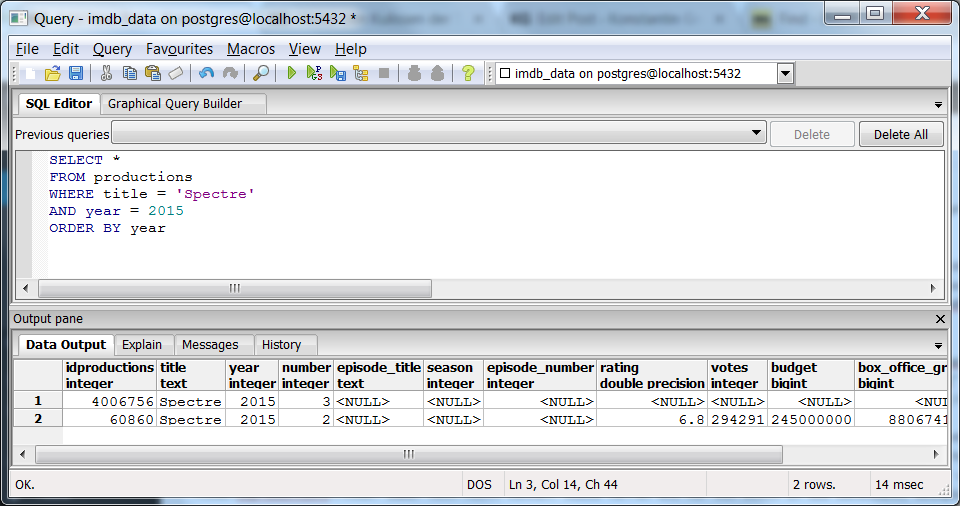
Datenbankabfrage nach Titel "SPECTRE" aus dem Jahr 2015
Ein guter Hinweis auf den tatsächlich gesuchten Film ist die Tatsache, dass nur einer der beiden (der untere) Informationen zu Bewertungen, Budget usw. enthält – für kleinere Produktionen liegen diese Informationen nur selten vor. Ein weiterer, hieb- und stichfester Beweis ist aber der Inhalt des Feldes number. Um der Tatsache von gleichlautenden Filmtiteln (und übrigens auch Personennamen) zu zollen, hat die IMDb ein System mit römischen Ziffern eingeführt. So ist im Screenshot der IMDb-Website oben hinter dem gesuchten “Spectre”-Flim eine römische Eins zu sehen, der Film wird in der IMDb also als “Spectre (I) (2015)” geführt und ist damit eindeutig. Der “Spectre”-Kurzfilm hingegen führt die Ziffer “(II)”. Jetzt ist es nur noch essentiell zu wissen, dass das Skript zum Auslesen der IMDb-Daten zur auf der Website gezeigten Ziffer immer noch eins hinzuaddiert. (Zu den technischen Hintergründen des Skripts plane ich einen Extra-Artikel.) Der von uns gesuchte Bond-Film “Spectre (I) (2015)” wird also in unserer Datenbank unter der number 2 geführt. Damit haben wir jetzt die korrekte idproductions zweifelsfrei identifiziert (hier: 60860) und können sie in die Datei sequels-de.txt übernehmen.
Ein roter Marker
Dieser Marker ist das Ergebnis eines simplen Vergleichs zwischen der Produktions ID aus der Datei sequels-de.txt und der idproductions aus der Datenbank. Dieser ist leider notwendig, da die IMDb-Extrakte, wie oben schon erwähnt, leider nicht die Original-IDs der IMDb enthalten. Das wäre beispielsweise die tt2379713 für den oben behandelten “James Bond”-Film “Spectre”. Hätten wir diese IDs in unserer Datenbank, wäre der Abgleich mit den Filmen aus unserer Filmreihen-Datei nur ein einziges Mal zu erledigen. Leider liegt es aber in der Natur unseres Extraktions-Skriptes, dass sich bei geänderter Datenbasis (also bspw. nach einer Aktualisierung der IMDb-Extrakte auf dem Server) die idproductions ebenfalls ändern. Sie werden i.d.R. höher, bleiben aber in einem vergleichbaren Zahlenbereich – was bei der manuellen Anpassung in der Datei sequels-de.txt ein guter Anhaltspunkt für Flüchtigkeitsfehler sein kann. (Übrigens würde es uns das Vorkommen der originalen IMDb-IDs in den Daten auch endlich erlauben, aus unseren Tableau-Visualisierungen heraus auf die IMDb-Website zu verweisen… Entsprechende Requests wurden bereits zahlreich im Rahmen der Umfrage zu einer IMDb-API gestellt, bisher aber seitens der für die Extrakte Verantwortlichen noch nicht umgesetzt.)
Das Heraussuchen und Eintragen der korrekten Produktions IDs in der Datei sequels-de.txt ist leider insgesamt recht stupide Handarbeit…
Fertig!
Am Ende stehen aber eine komplette und korrekte Datei sequels-de.txt (Rechtsklick > Ziel speichern unter... – diese Version passt zum IMDb-Extrakt vom 30.12.2016), die wir nun endlich mit unseren IMDb-Daten zusammenbringen und visuell analysieren können. Schauen wir uns also einmal an, ob wirklich immer der erste Film einer Reihe der Beste ist:

Tableau: Ist der erste Film immer der erfolgreichste?
Auch wenn es sich hierbei wie gesagt hierbei nur um eine sehr subjektive Auswahl von Filmreihen handelt, wird selbst aus dieser kleinen, nicht-repräsentativen Stichprobe ersichtlich: Nicht immer. Während bei die drei oberen Reihen (“American Pie”, “Zurück in die Zukunft” und “Stirb Langsam”) der Mythos zutrifft, zeigen den unteren drei Reihen (“James Bond”, “Star Trek” und “Star Wars”), dass dies nicht immer so ist. Zusammenhänge zwischen Gesamtlänge der Filmreihe, Zeitpunkt und Abstände zwischen den Veröffentlichungen, ob es sich um eine geplante Reihe handelt oder nicht – all dies könnten Anregungen für eigene, weitere Untersuchungen sein. Alle notwendigen Dateien liegen übrigens auch auf meinem dazugehörigen GitHub-Repository, speziell im Unterordner tableau-kino-tour.
Das war also der relativ einfache aber aufgrund viel händischer Arbeit nicht ganz einfach umzusetzende Weg zur Analyse der Filmreihen, wie in der Tableau Kino Tour gezeigt. Gemeinsam mit den im ersten Teil vorgestellten IMDb-Daten lassen sich schon viele interessante Informationen zu Filmen, Fernsehserien und Filmreihen analysieren und visualisieren. Im dritten und letzten Teil werde ich dann noch zeigen, wie wir die Daten des letzten Teils, die Daten zum “Tatort” gesammelt und aufbereitet haben!
Wer bis hierher durchgehalten und mitgemacht hat: Vielen Dank für’s Lesen, viel Spaß mit den Daten, und vielleicht sieht man sich ja bei einer der noch ausstehenden Stationen der Tableau Kino Tour!
Zugehörige Storys
VizQL Data Service from Tableau: Use Your Data, Your Way
 8 August, 2024
8 August, 2024

When and How to Use Multi-fact Relationships in Tableau
 1 August, 2024
1 August, 2024

Top data books of 2021
 12 Dezember, 2021
12 Dezember, 2021