Exploring Data Repositories with a Semantic Search Interface





Editor’s Note: This blog post talks about the motivation and main ideas in a published paper at the ACM Symposium on User Interface Software and Technology (UIST 2023), the premier conference for innovation and research in human-computer interfaces.
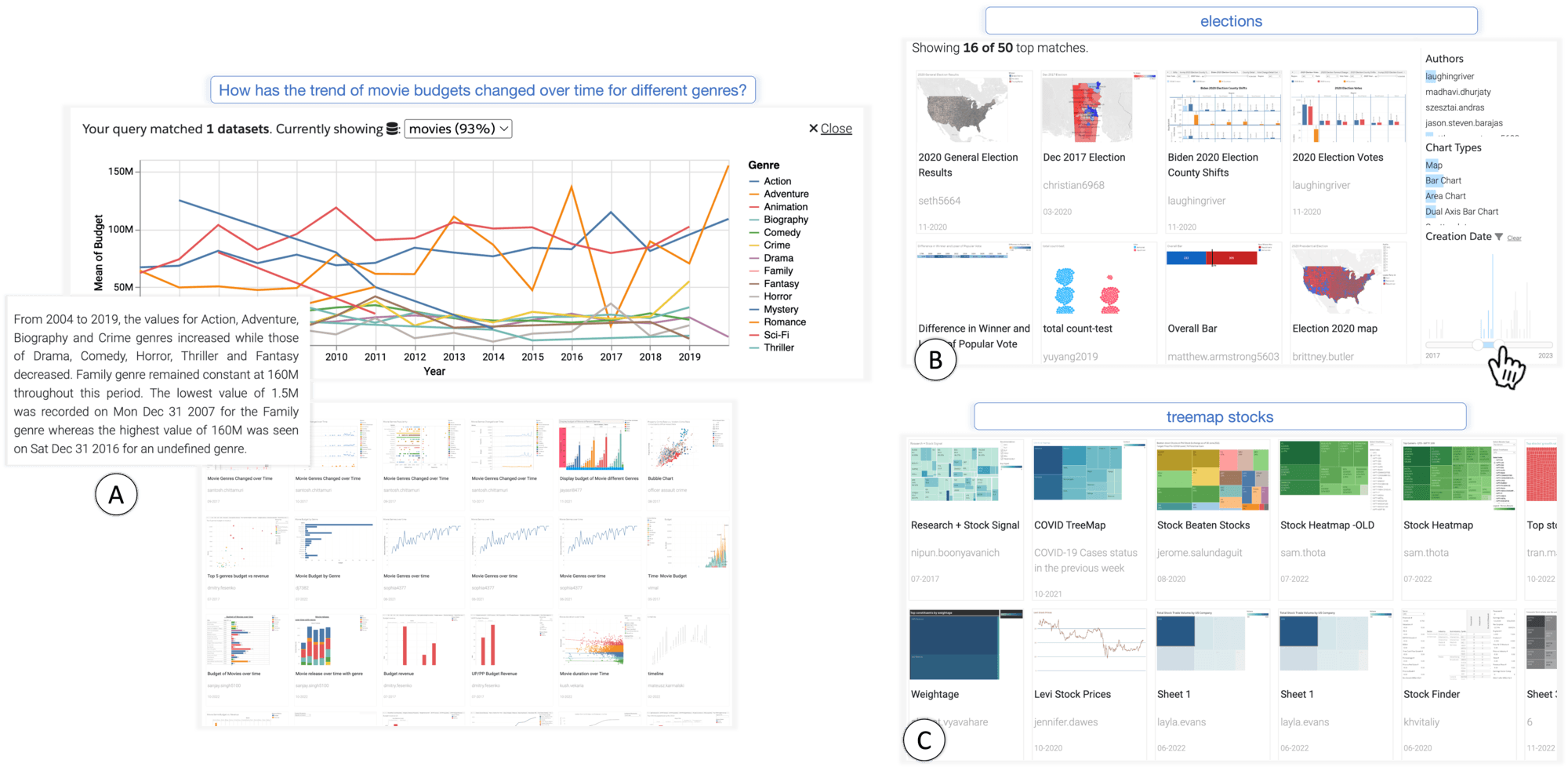
Figure 1: Examples of various semantic search scenarios supported in Olio. (A) Q&A. For an input query, “How has the trend of movie budgets changed over time for different genres?” Olio detects that it is a Q&A search with an analytical intent, ‘trend.’ A curated data source, ‘movies,’ is the top-scored match to the query, and the system generates a line chart response. A generated text summary describes the visualization as shown. Pre-authored visualization content is also displayed as thumbnails below the generated response as additional information. (B) Exploratory Search. Olio identifies the input query, “elections,” as a keyword search query and shows pre-authored visualizations with text content pertaining to ‘elections.’ (C) Design Search. The query “treemap stocks” is identified as a search of all content containing treemap visualizations pertaining to ‘stocks.’
The Shift in Searchers’ Expectations
Search engines have become an indispensable part of our lives. Whether we're looking for answers to questions, exploring new topics, or searching for specific content, our expectations of search interfaces have evolved. User expectations of search interfaces have evolved significantly over the years. In a study by Crook et al. in 2018, it was noted that users increasingly expect search engines to do more than retrieve content; they want answers to their questions, along with contextually relevant information that aids them in addressing their specific goals. This shift in expectations has brought to light the limitations of existing keyword-based search methods.
Traditional search engines were designed to retrieve content based on keywords. While these keyword-based search methods have been highly efficient for content retrieval, they are somewhat limited in scope. They often fall short when users pose structured queries that require focused and specific responses. On the flip side, natural language (NL) question & answering (Q&A) interfaces, which are designed for fact-finding inquiries, often do not support content or document discovery and retrieval as efficiently.
To bridge this gap, a hybrid approach known as semantic search has emerged. Semantic search goes beyond simple keyword matching by considering user intent and the meaning of words and phrases to determine the most relevant content, even if it's not explicitly present in the keywords themselves. Techniques such as entity recognition, word disambiguation, and relationship extraction are employed to interpret user intent and provide more targeted responses. This approach seeks to bridge the gap between keyword and Q&A search paradigms. For instance, while a keyword search might fetch documents related to "French press," a semantic search would be more apt for queries like “How do I quickly make strong coffee?”.
Challenges with Data Repositories
With an increasing number of data repositories on the web, there is a plethora of information that supports blending fact-finding responses with document retrieval. Platforms such as Observable, Tableau Public, and Microsoft Power BI Partner Showcase host vast numbers of visualizations, making them useful repositories for knowledge consumption and data discovery. Yet, these repositories present unique challenges.
Data repositories often suffer from the sparseness of searchable text. Visualizations, charts, and data sources typically have limited textual information in the form of titles, captions, and data values. This limitation necessitates alternative ways to index and search for content. Another challenge lies in the limited expressivity of current search features for data repositories. Users are predominantly limited to keyword searches based on visualization titles and authors. This stands in contrast to contemporary search interfaces, such as general web search, image and video search, and social networking sites that offer a rich set of search functionality, including textual content, visual features, dates, geographic locations, and different media types.
To design expressive search interfaces for data repositories that meet evolving user expectations, we need a deeper empirical understanding of user requirements. Key questions include: What are the goals users have in mind when searching within data repositories? How do they formulate their search queries? Is text alone sufficient, or should we consider complementary modalities? What metadata do users want to query for or use to filter search results?
Identifying Different Search Goals
To better understand the types of search tasks that users would find valuable when searching within data repositories, we conducted a series of interviews with 14 participants. Our goal was to gather a comprehensive perspective from a diverse group of users who brought practical experience with visualization repositories like Tableau Public, Microsoft Power BI, D3, and general familiarity with searching for visualizations on platforms like Google. Our formative interviews yielded valuable findings regarding user goals and the metadata features that hold significance in the context of data repositories containing both datasets and pre-authored charts. These insights helped us identify the following types of search goals for data repositories:
- Q&A search: Interpretation of analytical intent over various data sources.
- Exploratory search: Document-based retrieval methods on existing indexed visualization content.
- Design search: Leveraging visualization metadata.
- Facet-driven browsing: Allows users to refine their search results by various criteria like author, time range, or visualization type.
Introducing Olio: A Hybrid Search Tool for Data Repositories
Olio is designed as a hybrid search interface that supports semantic search behavior by dynamically generating visualization responses and pre-authored visualizations from data repositories. Figure 1 shows how Olio supports the three search goals informed by the interviews.
Now, let's dive into the Olio interface through a usage scenario. Imagine you're a user interested in housing prices in the USA. You start by landing on Olio's interface, which showcases a selection of data sources available for Q&A search. Each data source thumbnail provides metadata information upon hovering, offering you a glimpse into the available datasets, shown in Figure 2.
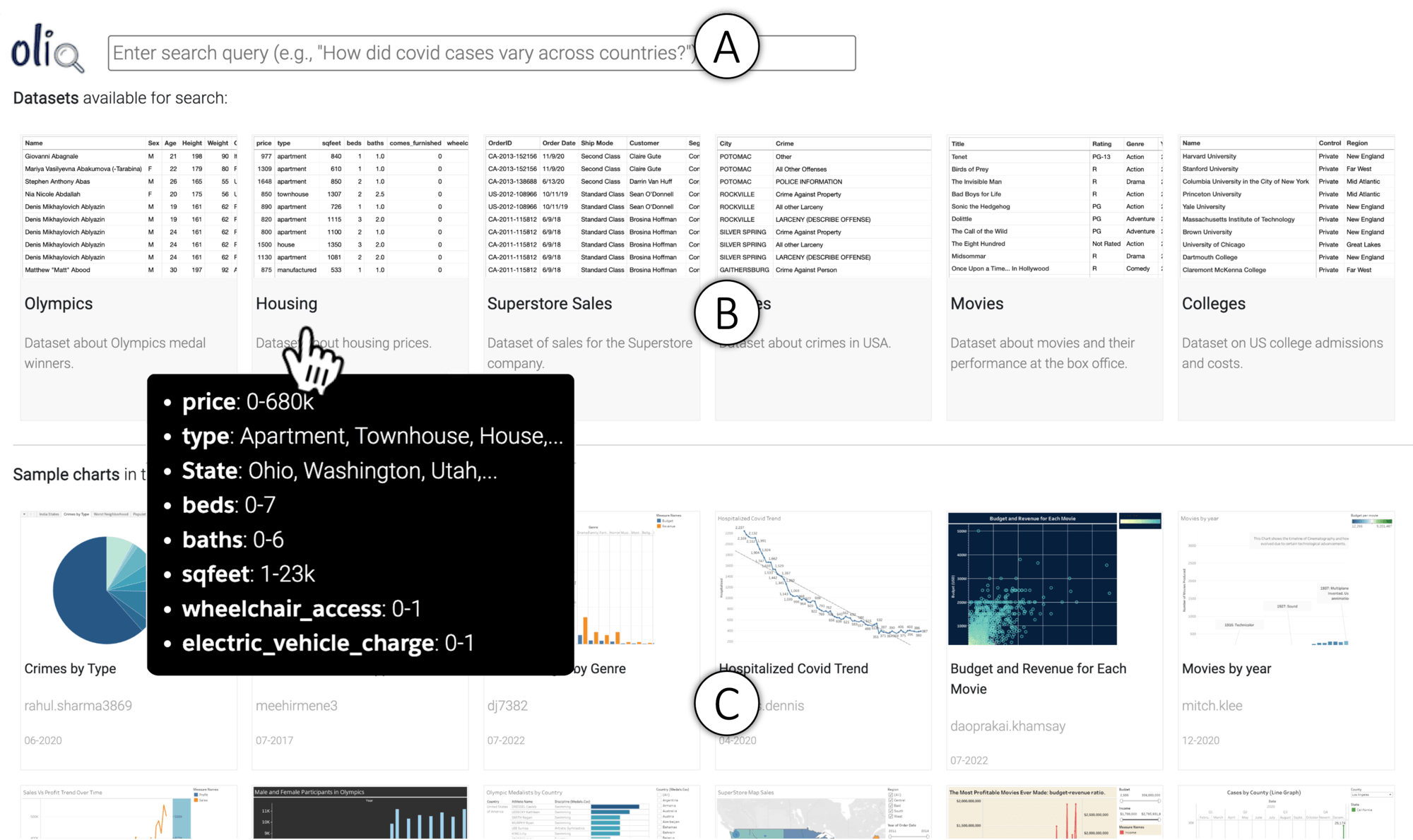
Figure 2: Olio’s landing screen. (A) A search input box with a placeholder query suggestion generated based on one of the available data sources. (B) Thumbnail previews of someavailable data sources. Here, hovering over the ‘Housing’ data source shows a tooltip displaying metadata about the data source’s attributes and values. (C) A sampling of pre-authored visualizations available for search.
You begin your search by typing "housing prices USA" into the input text box (Figure 3A). Here's where Olio's semantic search capabilities come into play. Olio's system detects that 'USA' is a geographic location and scours its data repository for a relevant data source. In this case, it finds a housing data source that matches your query.
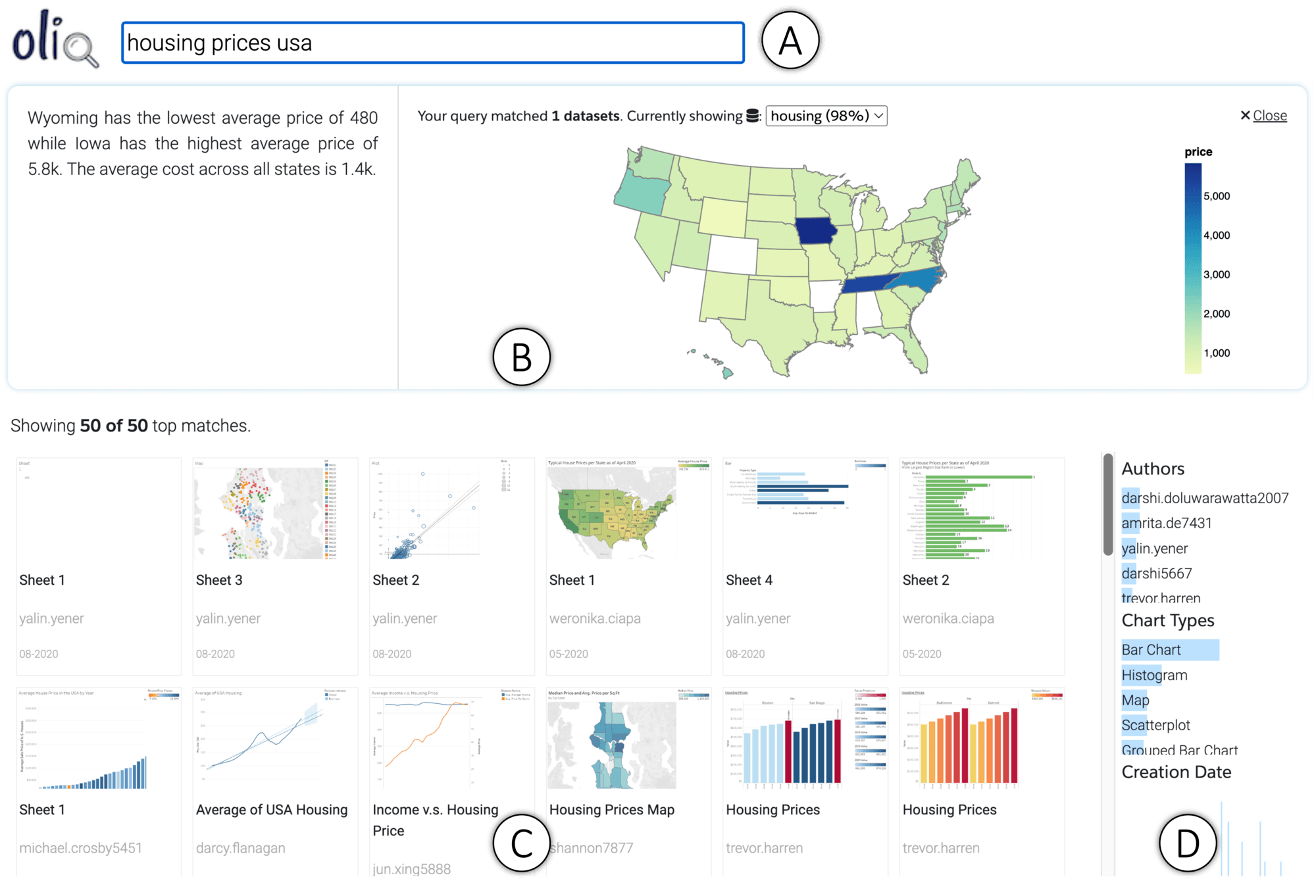
Figure 3: The Olio interface. (A) Search input box. (B) Dynamically generated content, including a chart on the right and text highlighting the key takeaway messages from the chart on the left. (C) Top 50 pre-authored visualizations that map to the input query. (D) Scented widgets that support dynamic filtering of the pre-authored content results.
A map is dynamically generated as a Q&A response to your query (Figure 3B), showing a visual representation of housing prices in the USA, along with a GPT-generated summary describing key statistical information from the chart.
Olio also matches keywords in the query against pre-authored visualizations in its repository. A grid of thumbnails appears, allowing you to preview and explore related visualizations (Figure 3C). Each thumbnail is hyperlinked to its corresponding visualization file, giving you the option to delve deeper or download it for further analysis.
To support organized exploration and filtering, Olio offers scented widgets on the right side of the exploratory search panel (Figure 3D). These widgets support faceted browsing of the pre-authored visualizations. You can further refine your search results by applying filters such as author name, visualization type, and creation date.
How Does Olio Work Under the Hood?
Olio is a web-based application powered by Python and a Flask backend connected to a Node.js frontend. The backbone of Olio's search prowess lies in Elasticsearch, an open-source Java search engine that is distributive, scalable, and performs near real-time query execution capabilities. At its core, Olio comprises several key components:
- Query Classifier: Olio takes as input an input search query that is passed to the query classifier. The classifier supports federated query search, which is the process of distributing a query to multiple search repositories and combining results into a single, consolidated search result. The query classifier passes the search tokens to a parser. The query classifier also passes the query tokens to the semantic search framework to determine if the query tokens match fields in any of the data sources (e.g., ‘prices’ mapping to the Price attribute in the housing data source).
- Parser: The parser determines if the query contains any analytic intents such as aggregation, correlation, temporal, or geospatial expressions.
- Semantic Search Framework: This framework performs the indexing and searching of content and metadata in the data repositories that is leveraged by both the Q&A and general search modules.
- Q&A Module: This module interprets the analytical intent expressed in the input search queries based on the list of top-matched data source(s) returned from the semantic search framework and dynamically generates visualization responses displayed in the Olio interface.
- General Search Module: This module displays thumbnails of pre-authored visualization content and enables two types of searches: exploratory and design
In summary, Olio bridges traditional keyword-based search and the evolving user expectations of semantic, context-rich search experiences. Its dynamic generation of visualizations and interface design cater to the diverse needs of today's users, making it a promising solution for the data-rich landscape we navigate.
Looking Ahead
Using Olio as a design probe, we conducted a preliminary user study with 11 participants to qualitatively assess the overarching idea of combining dynamically generated visualizations with pre-authored charts when searching data repositories. Overall, participants noted that the hybrid search paradigm was useful and provided a richer analytical experience for targeted and open-ended exploration.
However, there are plenty of interesting research directions to move this work forward. As people actively explore data and create analytical artifacts, we need to explore ways to support a broader repertoire of search goals within these data repositories. Search precision depends on the availability and curation quality of data sources. Future work should also explore techniques to help with data curation, such as metadata enrichment, entity recognition, synonyms, and relational extraction. Finally, trust is an important issue, and users would benefit from information that communicates the provenance of data sources used to generate the visualization responses and how to support built-in data privacy for indexing and searching of content. As we move forward, it is essential to continue refining and expanding upon tools and interfaces like Olio to meet the evolving needs of users during data exploration.
Storie correlate
Once Again, with Style: Understanding and Supporting Partial Reuse in Dashboard Authoring
 5 Giugno, 2026
5 Giugno, 2026
From ‘Here’ to ‘There’: Exploring Proximity Semantics in Multimodal Data Exploration
 3 Giugno, 2026
3 Giugno, 2026

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 14 Aprile, 2026
14 Aprile, 2026