Best Practices to Improve the Performance of Your Data Preparation Flows
Learn about design best practices for your Tableau Prep flows that you can use to make your Prep flows run faster.




Tableau Prep is a citizen data preparation tool that brings analytics to anyone, anywhere. With Prep, users can easily and quickly combine, shape, and clean data for analysis with just a few clicks.
In this blog, we’ll discuss ways to make your data preparation flow run faster. These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables. Give these tips a try and let us know what you think.
Bring in the right data
The more data you bring into your data preparation flow, the more computationally expensive it will be. A simple yet powerful way to minimize the time needed for Prep to load your data and run your flow is to only work with the data you need.
Let’s look at a real-world example of a Tableau data set. This database table—dating back to 2019—contains a whopping 14.5 billion records! Oftentimes, analyzing older data (in this case, data from five years ago) isn’t necessary. Doing so can significantly increase the time it takes to load your data and run your flow. In this example, the SQL query took over 38 minutes to complete in the native database portal.
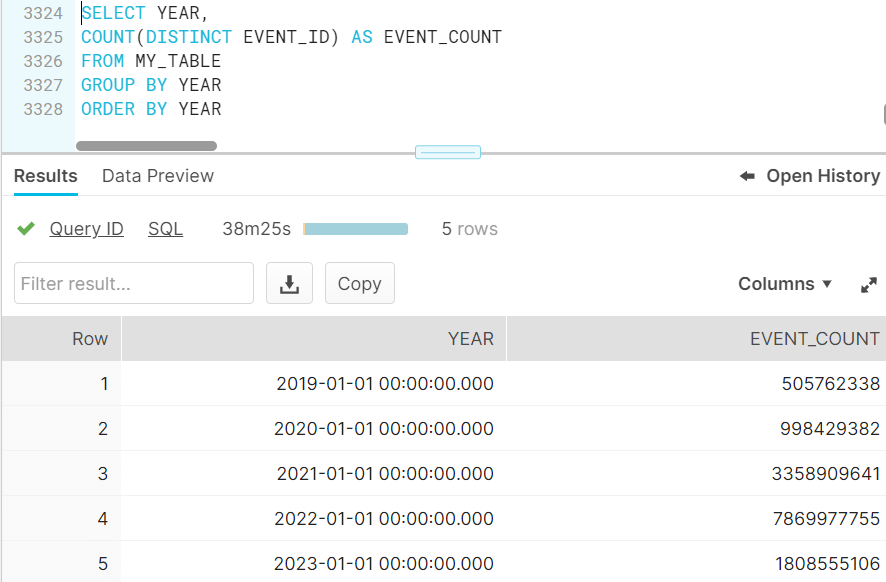
Filter on the Input step
You can help Prep run faster by removing columns and filtering out data that isn’t essential to your workflow in the Input step. These actions guarantee that unnecessary data won’t be loaded into memory while authoring your Prep flow and will limit the amount of data queried when you run your Prep flow. Performing the actions after the Input step, say within the Clean step, won’t provide the same benefit. Learn more about how Prep works under the hood in this blog post.
With the Tableau Prep 2023.1 release, you can bulk select and remove multiple columns.
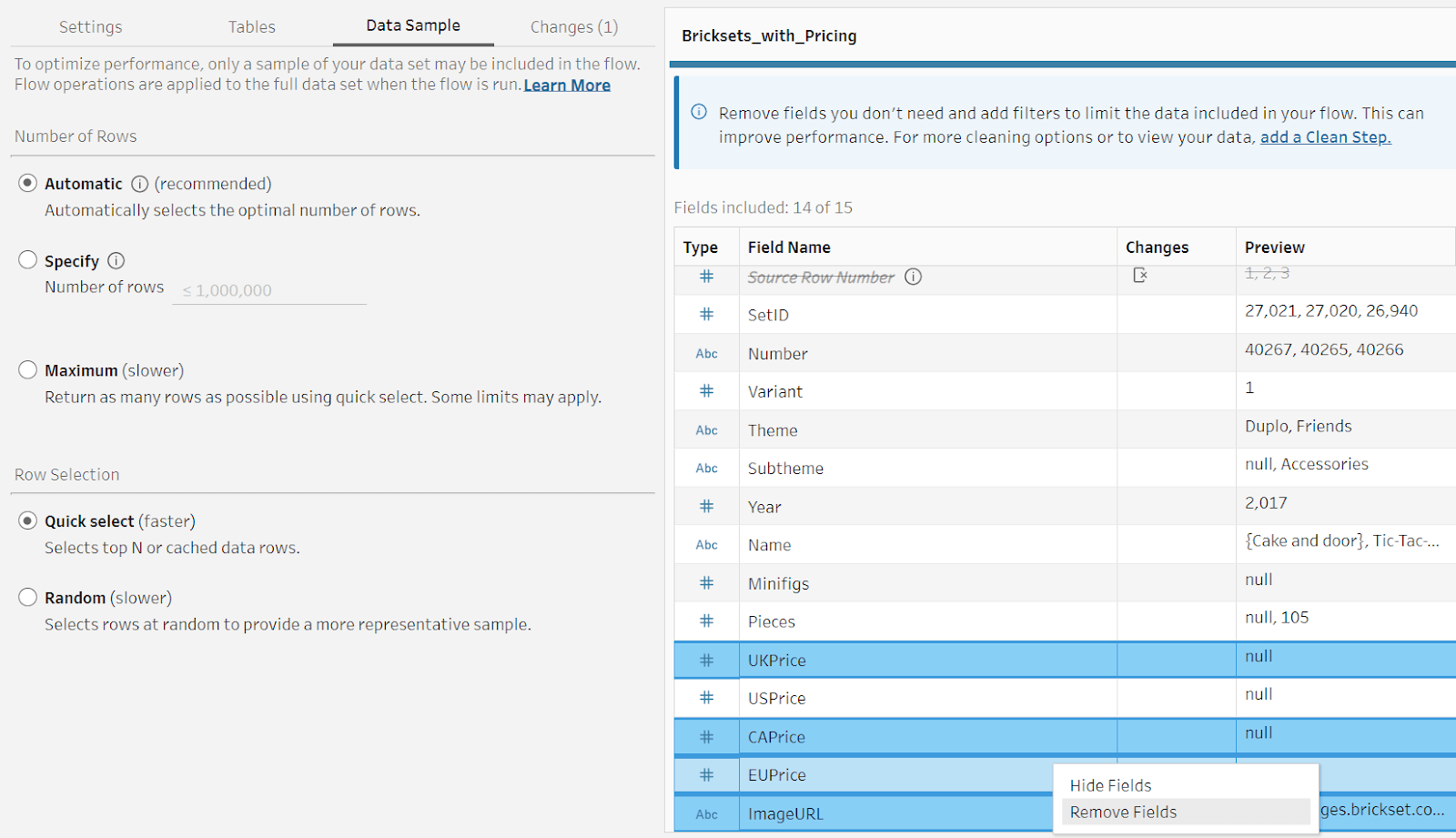
You can also add no-code relative date filters for DateTime data types in the Input step.
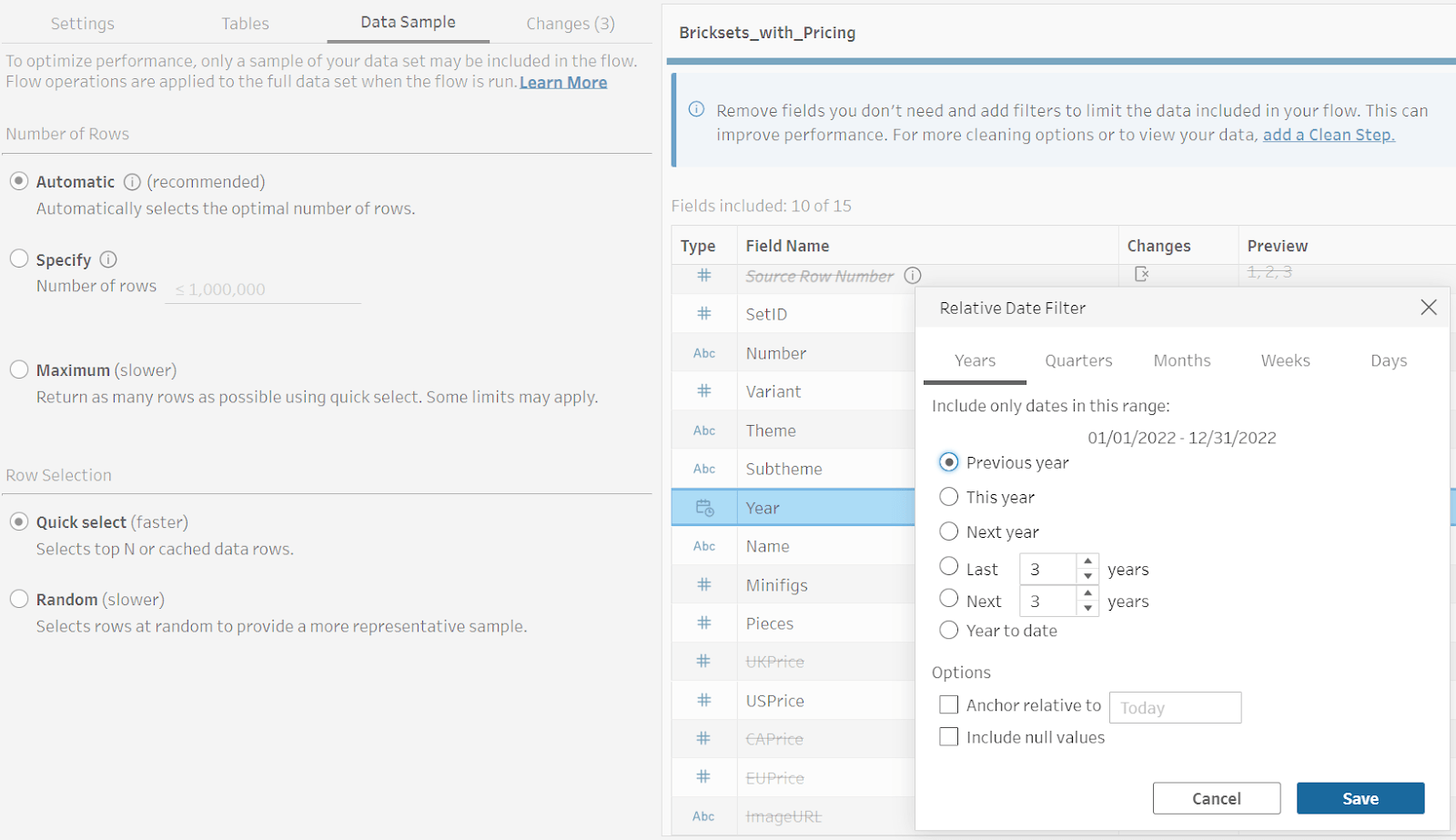
These improvements help you quickly remove columns and easily filter to the time period required for your analytics.
Sampling
By default, while authoring flows, Prep automatically applies sampling to limit the amount of data it processes. When you run your flow, changes are always made to the entire data set—and not to a sample—so you can walk away with a clean, ready-to-analyze data set.
The algorithm used to determine the sample size calculates the maximum number of rows based on the number of columns in the Input step and their respective data types. Often the maximum number of rows is greater than the number of rows in your data set. If that’s the case, then sampling won’t be applied. A badge is displayed when sampling is applied.
As you may have guessed, the algorithm that determines the maximum number of rows is rather complex. We can use a heuristic to describe its behavior. In all cases, the number of rows is capped at roughly 1 million. For most data types, your data set can have up to 4 columns and still maintain the 1 million row limit. If your data set has 8 columns, then the maximum number of rows is halved to 500,000. If your data set has 16 columns, then the maximum number of rows is halved again, to 250,000, and so on. To increase the maximum number of rows, you can remove unnecessary columns in the Input step.
When sampling is applied, the top rows, sorted by source row order, are queried and appended to already cached rows. If you’d like to get a more representative sample, you can change the sampling method to random in the Data Sample tab within the Input step.
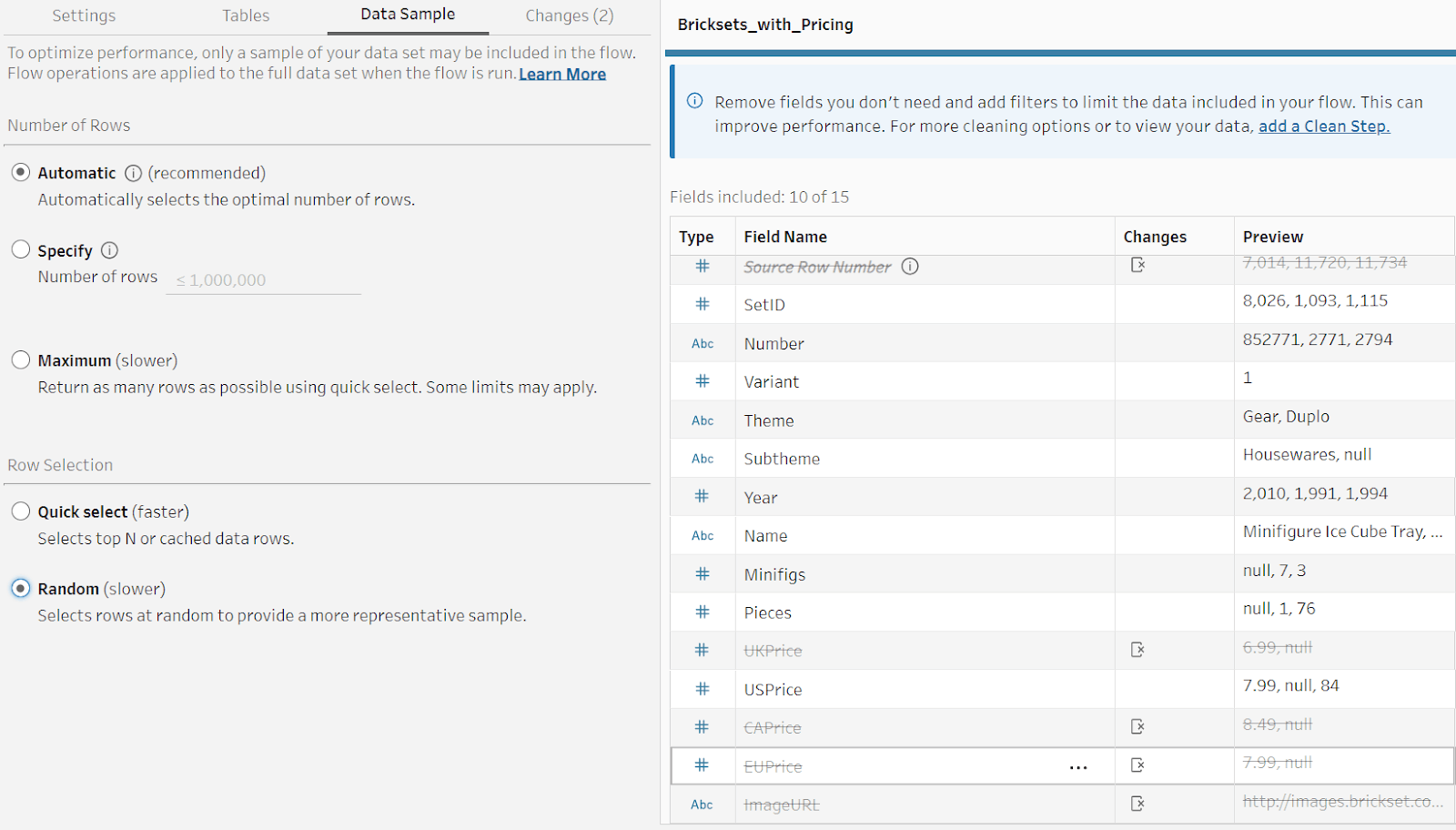
To further refine the sample, you can filter values in the Input step. Let’s say, for example, that you’re only interested in deals closed in 2022. In this case, filtering on the deal year equal to 2022 in the Input step will force sampling to be applied only to those deals versus deals from every year.
Often, your data only needs high-level restructuring, which doesn’t require insight into every individual row of data. Say you only need to pivot rows to columns or union a few tables together. In scenarios like this, you can reduce the sample size by specifying the number of rows to a small number—say 100 rows in the Data Sample tab within the Input step.

Consider your data type
Any data you bring into Prep will be assigned a data type. Prep makes an educated guess, but you have the ability to change this classification. A number or Boolean data type is easier for Prep to query than a string data type because there are fewer possible values to be parsed. For example, you might have a numeric ID in your data that Prep has classified as a string data type rather than a number type. You can change the data type from a string to a number (whole) data type to reduce query time in the Input step or subsequent steps throughout the flow.
Identify flow objectives
When designing your Prep flow, focus on a few key objectives. Consider dividing your steps into separate flows to organize your work if it isn't necessary for the cleaning operations to live in a single flow. Individual steps or even entire flows can be brought together later through Join or Union steps. You can also use Tableau Prep Conductor to schedule tasks to run one after the other with Linked Tasks. Note, Prep Conductor is an add-on and is licensed through Tableau Data Management.
Take advantage of incremental refresh
With incremental extracts, you can configure your flows to refresh incrementally, meaning only new rows will be retrieved when the data is refreshed. Incremental refreshes save you time and resources, especially on larger outputs. You can still schedule a full extract refresh as well, for example, on a weekly or monthly cadence.
Say you have transactional data—months of daily sales orders collected in a data set that gets updated with new data every day. You don’t need to update the historical data in your flow; instead, you only need to process the new rows. Prep can save you time and resources through incremental extracts, by processing only the new data every day instead of the entire data set every time the flow is refreshed.
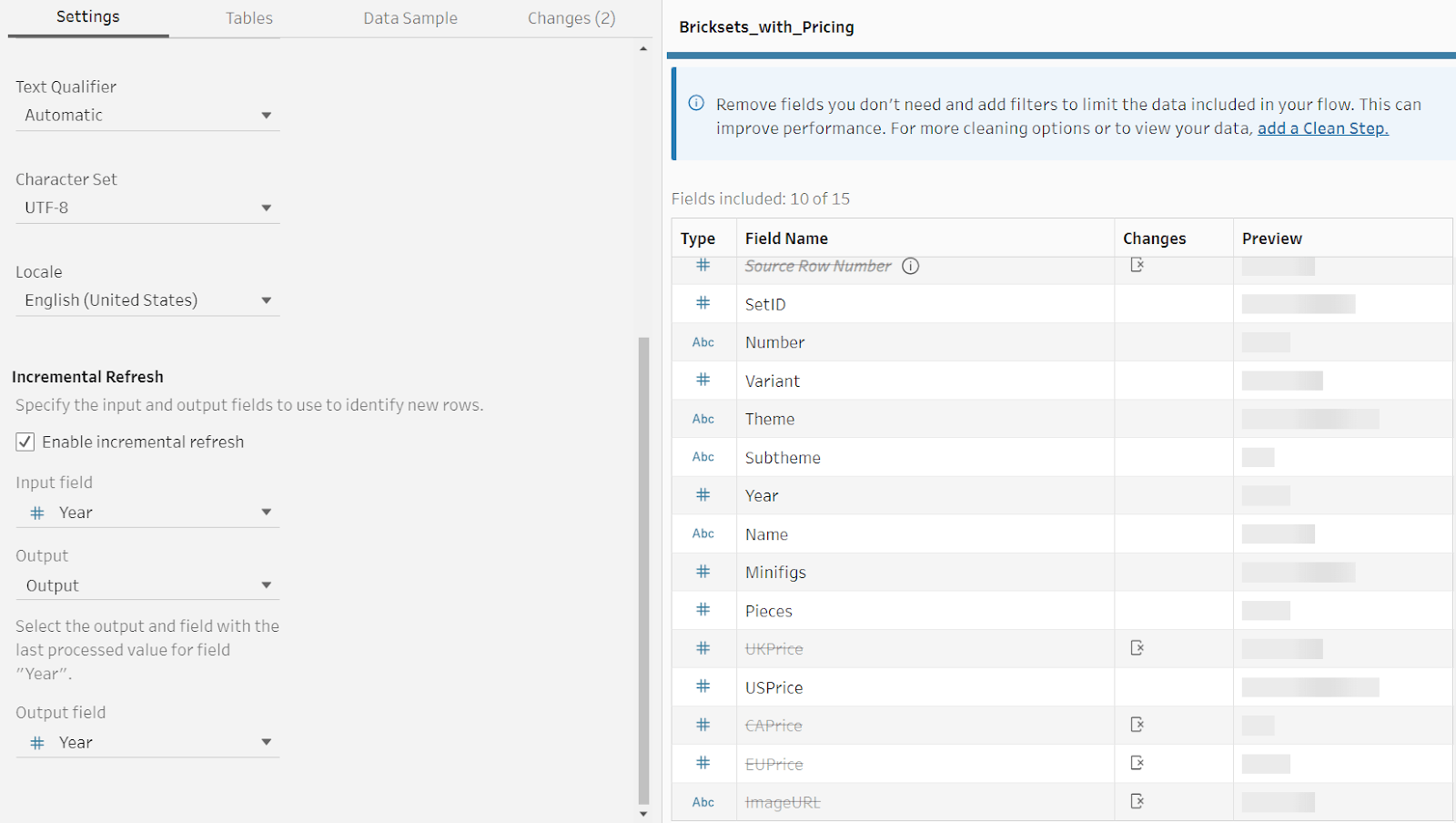
Pause your flow
At times, you may not need interactive feedback as you author your flow. If you need to perform minor changes in which you don’t need feedback, you can pause your flow. Just be aware that you won’t immediately see the results. When your flow is paused, interactive updates are paused, although data schemas are still validated.
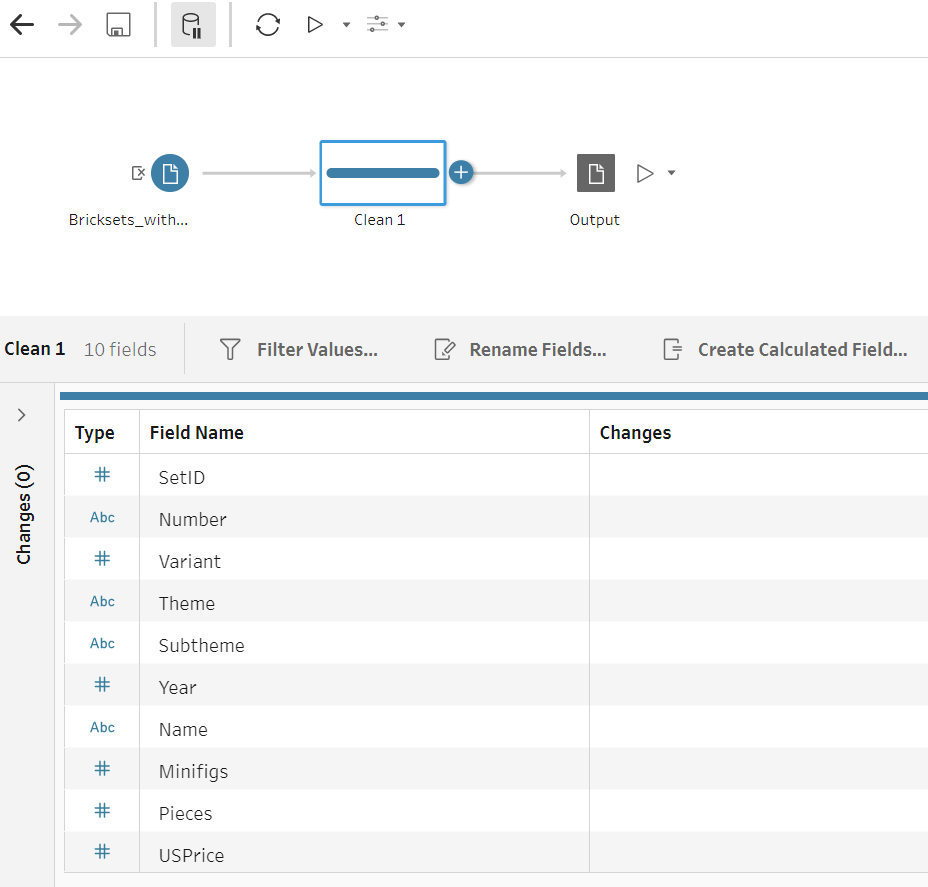
Consider your output file type
Using the Output step, you can configure your Prep flow to output data to a number of destinations, including databases, CSV files, and Tableau extracts. In testing, we found that a large data set took 2 hours and 47 minutes to output as a CSV, but only 11 minutes to output as a Hyper extract. Extracts are better equipped to handle large data sets, and unless your workflow requires a flat file, we recommend using a Hyper extract. If you’re using Prep Conductor to publish your flows, outputting to an extract will also allow you to publish and maintain a single source of truth for your data on Tableau Cloud or Tableau Server.
Articles sur des sujets connexes
Extend Access to Embedded Tableau Content with On-Demand Access
 juillet 22, 2026
juillet 22, 2026

The Tableau+ Bundle with Premium AI, Enterprise Capabilities, and Premier Success
 juin 24, 2026
juin 24, 2026
What is Tableau Prep?
 avril 30, 2026
avril 30, 2026