Die Welt ist wieder in Goldgräberstimmung. Die Goldminen des 21. Jahrhunderts sind die Datenberge der Unternehmen, und mittels Data Mining wird das Gold abgeschürft. Was ist Data Mining? Wo kommt es zum Einsatz? Wie kann man diese Daten analysieren? Welche Probleme können auftreten? Welche Tools kommen zum Einsatz? Diesen Fragen geht dieser Artikel nach.
01. Was ist Data Mining?
Data Mining beschäftigt sich mit der Möglichkeit, in Datenbeständen versteckte Muster und Strukturen aufzudecken. Das geschieht mittels systematischer Anwendung statistischer Methoden und verfolgt das Ziel, neue Erkenntnisse, Querverbindungen und Trends zu erkennen.
Data Mining hilft Ihnen, Ihr Unternehmen besser zu verstehen. Es liefert Hinweise, wie Sie mehr Umsatz erzielen, Kosten einsparen können oder welche Investitionen den besten Ertrag bringen.
Beispiel: Ein Einzelhändler erkennt aufgrund der Daten aus einem Kundenbindungsprogramm, welche Kunden mehr Geld ausgeben und welche weniger. So kann er sich mit seinen Marketingmaßnahmen auf die Kunden fokussieren, mit denen er bessere Umsätze generiert. Das spart Zeit und Geld.
02. Wofür wird Data Mining angewendet?
CRM, Marketing
Am häufigsten wird Data Mining im Marketing und Customer Relationship Management (CRM) eingesetzt. Die Unternehmen verfügen hier über umfangreiche Datenbestände. Es ist noch gar nicht lange her, dass man das wertvolle Potential entdeckt hat.
Beim CRM geht um die Beziehungen eines Unternehmens zu seinen Kunden. Diese sollen möglichst effizient gestaltet und ein mögliches Kundenverhalten vorhergesehen werden. Beispielsweise lassen sich zu diesem Zweck Kunden in Kundengruppen zusammenfassen. Das nennt man Kundensegmentierung oder auch Kundenclustering. Kunden aus dem gleichen Segment kann man die gleichen bzw. die für sie am besten geeigneten Produkte anbieten. Beliebt sind auch gezielte Werbeaktionen wie Kundenmailings, bei denen es um eine möglichst hohe Antwortquote geht.
Handel
Der Handel nutzt Data Mining, um das Kaufverhalten mittels Warenkorbanalyse zu untersuchen. Wir alle kennen das aus dem Online-Handel als „andere Kunden kauften auch“. Data Mining unterstützt den stationären Handel auch bei der Verkaufsraumgestaltung oder der Bestellmengenplanung.
Banken und Versicherungen
Banken und Versicherungen haben schon früh Data Mining für die Risikoanalyse genutzt, um beispielsweise folgende Fragen zu beantworten: Ist der Kunde kreditwürdig? Kann man ihm eine Kfz- oder Lebensversicherung anbieten? Data Mining hilft auch beim Aufdecken von Betrug oder Betrugsversuchen.
Text Mining
Text Mining ist eine Unterform des Data Minings. Damit lässt sich Wissen aus Texten extrahieren, verarbeiten und nutzen, beispielsweise indem Hypothesen daraus abgeleitet werden. Text kann somit als „Wissensrohstoff“ betrachtet werden. Text Mining ist damit auch der Wegbereiter für das Semantische Web.
Pharmaindustrie
In dieser Branche haben Datenverarbeitung und -analyse eine besonders große Bedeutung. Die Entwicklung von Medikamenten könnte durch Data Mining noch erheblich verbessert werden. Wissenschaftler arbeiten auf dem Weg zur personalisierten Medizin auch daran, mittels Data Mining Einblicke in das Entstehen von Krankheiten zu bekommen und herauszufinden, warum Medikamente bei manchen Menschen wirken und bei anderen nicht. Die Ergebnisse könnten in der Zukunft die Entwicklung von Test und Medikamenten beschleunigen.
03. Wie werden Data Mining Daten analysiert?
Um das meiste aus seinen Daten herauszuholen, benötigt man einen optimalen Arbeitsprozess. Der am häufigsten verwendete und branchenübergreifende Prozess nennt sich CRISP-DM und steht für CRoss-Industry Standard Process for Data Mining (Abb. 1).
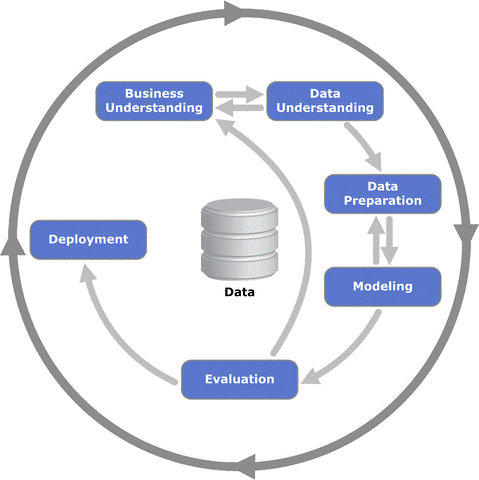
Abb. 1: Das Prozessdiagramm stellt die Beziehung zwischen den verschiedenen Phasen des CRISP-DMa dar. Illustration von Kenneth Jensen, basierend auf IBN SPSS Modeler CRISP-DM Guide [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
Wie man in der Abbildung erkennen kann, handelt es sich nicht um einen linearen Prozess, sondern es wird häufig zwischen den Phasen hin- und her gewechselt.
Die sechs Phasen des CRISP-DMs sind:
- Business Understanding (Geschäftsverständnis)
- Data Understanding (Datenverständnis)
- Data Preparation (Datenvorbereitung)
- Modeling (Modellierung)
- Evaluation (Evaluierung)
- Deployment (Bereitstellung)
Jede Phase ist gleich wichtig für die Qualität des Ergebnisses.
Achtung: Die Datenvorbereitung erfordert die meiste Zeit. Oft nimmt sie mehr Zeit in Anspruch als alle anderen Phasen zusammen.
In der ersten Phase legen Sie Ziele und Anforderungen fest. In der zweiten Phase sind die vorhandenen Daten zu sichten. In der dritten Phase müssen sie in das richtige Format für Modellierung und Analyse gebracht werden.
In Phase vier gilt es, vorausschauende Modelle zu entwerfen, um das Unternehmen besser zu verstehen und das Betriebsergebnis zu verbessern.
Diese Modelle basieren auf Mustern, die mittels statistischer Methoden sowie durch Maschinelles Lernen (Machine Learning) in den Daten gefunden werden.
04. Welche Probleme können beim Data Mining auftreten?
Fehlerhafte Daten
Die Qualität der Daten ist eine wichtige Voraussetzung für ein aussagekräftiges Data Mining-Ergebnis. Wenn Daten nicht vollständig vorliegen oder fehlerhaft sind, wirkt sich das negativ auf das Ergebnis aus. Entscheidungen, die auf einer fehlerhaften Grundlage gefällt werden, können möglicherweise schwerwiegende Folgen haben.
Datendiebstahl und -missbrauch
Der Schutz persönlichen Daten vor Diebstahl und Missbrauch sowie die Einhaltung gesetzlicher Bestimmungen wie der Datenschutzgrundverordnung müssen auch beim Data Mining oberste Priorität haben. Zudem müssen die Unternehmen die gesammelten Daten gut vor Angreifern schützen. Spektakuläre digitale Einbrüche bei Sony, dem FBI oder auch kürzlich beim Auswärtigen Amt zeigen, wie groß die Gefahr für Datendiebstahl ist.
05. Methoden und Konzepte von Data Mining-Werkzeugen
Gute Data Mining-Werkzeuge sollen dem Anwender helfen, möglichst schnell verwertbare Muster in Daten zu finden. Dabei kommen vor allem folgende Methoden zum Einsatz:
Klassifizierung
Die betrachteten Objekte werden bestimmten Klassen zugeordnet. Mit Entscheidungsregeln legt man die Zuordnung fest und wendet diese auf bestimmte Objektmerkmale an.
Beispiel: Ein Kreditinstitut möchte die Kreditwürdigkeit eines neuen Kunden ermitteln. Die Einstufungen der vorhandenen Kunden und die durch Data Mining ermittelten Aussagen helfen bei der Entscheidung über neue Kreditanträge.
Die vier wesentlichen Klassifikationsverfahren im Data Mining sind Entscheidungsbäume, neuronale Netze, die Bayes-Klassifikation und das Nächste-Nachbarn-Verfahren.
Abhängigkeitsanalyse
Bei der Abhängigkeitsanalyse oder auch Assoziationsanalyse wird nach interessanten Abhängigkeiten zwischen den untersuchten Objekten gesucht.
Beispiel: Bei der Warenkorbanalyse werden mittels statistischer Analysemethoden Kundenprofile erstellt.
Clusteranalyse
In Clusteranalysen werden Ähnlichkeitsstrukturen in meist großen Datenbeständen gesucht. Ähnliche Objekte werden in Gruppen zusammengeführt, sogenannten „Clustern“.
Beispiel: Bei der Taxonomie in der Biologie wird über eine Segmentierung von verwandten Arten eine Ordnung der Lebewesen ermittelt.
Prognose
Hier trifft man Vorhersagen für die Zukunft auf Basis von Werten aus der Vergangenheit.
Beispiel: Prognose für Finanzkurse oder Sportergebnisse. Das Unternehmen FiveThirtyEight hat sich beispielsweise auf Prognosen spezialisiert und erfreut sich nicht nur in Zeiten der Fußballweltmeisterschaft wachsender Beliebtheit.