MyALPO: What we learned from building a personalized portal to Tableau Server




Note: This is the second installment of a three-part series on MyALPO, an internal tool that provides a personalized homepage for every Tableau Server user. The first part outlines how we designed MyALPO.
Last week, we introduced you to MyALPO, our internal portal to our enterprise deployment of Tableau Server. MyALPO provides a personalized homepage for every user so people can quickly and easily find what they need. With more and more people authoring workbooks and data sources to Tableau Server, this scalable solution has proven immensely valuable to our users.
We don’t plan to productionalize MyALPO, but we’d like to share what we learned along the way.
User-specific views
We designed this tool to give users a focused portal to all relevant content on Tableau Server. In choosing content to highlight, we focused on each user’s recent views and favorites. This subset of views is essentially what users look for when they visit Tableau Server.

There were two major steps to building this into the portal. We first needed a separate database that contained a subset of data from the Tableau Server repository, manipulated and stored in a way that best fit our portal needs. We needed this because most of this data didn’t have to be in real-time, and the constant usage of the portal would have slowed Tableau Server with all of the queries hitting it.
We also needed a way to display the views in the portal that matched the experience we have in Tableau Server. To do that, we utilized some of the functionality of the REST API. Here’s the API resource that I’ll be referencing throughout this write-up.
There are no set requirements to creating an external database for your portal. You can leverage the technologies available to you and design around your data needs. We used two methods which I’ll outline, but you can use whatever method you choose as long as you have access to the data you need.
Method #1: Leveraging the Repository Backup for Slightly-Stale Data
The first method was for data that we didn’t mind being slightly stale, like the user’s favorite and most-frequented views. We leveraged the nightly backup of Tableau Server that we were already storing.
Within that backup, there is a backup of the Postgres repository of Tableau Server. Every night, we take that Postgres backup and use it to rebuild a static Postgres database that mirrors the state of the repository that night. We make calls against this repository, and based on our needs and resources, we build within the database additional tables that help with the analytic workload that we will need.
We query against this database from our portal for data that we are comfortable being, at most, one day stale. This allows us to do a lot of analytic processing on the back end at night when resources are available, and to not stress the live repository during the day.
2. Running Simple Queries Against the Live Repository for Fresh Data
The other method that we use is to grab data that we need much fresher than on a daily cycle. We built a separate program to run simple queries against our Tableau Server repository and save the results to new tables in a static database.
We made sure to test that the queries run against the repository all ran very quickly—all under a second—so as not to hold up server resources. We use this method to create a list of recently-visited views. An example of the tables we store are: views, workbooks, events, asset list, users, and a few other custom tables.
From the static database, we can query it to provide us user-specific data, such as the user's favorite and recent views. To get user-specific data, we first have to know who the user is. We accomplish this with a login system to our portal. We use the Tableau REST API sign-in call to get both user-specific information (such as username, user luid, and site id) as well as an authentication token to make some necessary calls later against the REST API. This call is made when the user signs in to the portal.
Right after this call, we query our static database to get lists of views the specific user has favorited and recently viewed. Depending on the questions you are asking and how you’ve set up your static database, these queries should be fairly simple. The content that we specifically need for our purposes are the workbook luid, view luid, view name, and view repository url.
Given these results from our static database, we can construct a call to the REST API to query “view preview image.” We can then display the resulting image in our portal along with any names or links that we want. We have chosen to run this process at the load of the page, but it could also be done with a user trigger on the portal site.
Content discovery section

A core feature of our portal is the view discovery tool. We wanted to create a personalized list of suggested views for each user. To compile this list, we look at which content the user’s peers are looking at. For us, that meant looking at what was being viewed within a user’s department. For you, the equation might also include content being viewed by the manager’s team, project team, or sub-department.
To create the list of suggested content, we used Tableau to analyze the events data within our static database. This creates a daily view of content to track based on the user’s department’s behavior.
We can then take this view and embed it within the portal. In the embed code, we pass to Tableau the username, from the login, as a passed parameter. Within the view we take that passed parameter and, using a calculated field, figure out the department in which that user resides.
We then filter the events data to only leave the events in which the user was in the specified department. With this data, you can slice and dice it to fit your company’s needs.
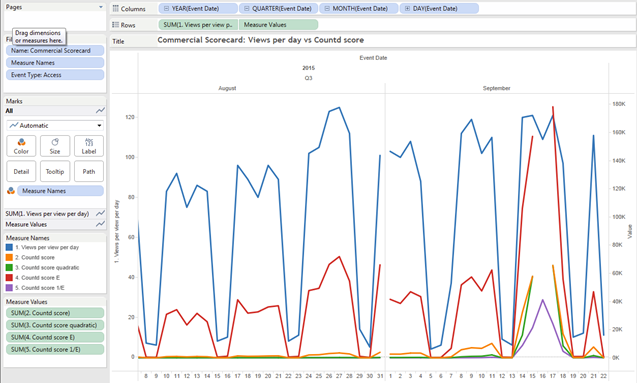
In our case, we’ve learned that we need multiple ways to display this data. The concept of relevancy is very hard to quantify because different users, different needs, and different data lend themselves to different metrics. Sometimes you may need to know what is new and popular in your Tableau Server instance. Other times you may need to see the most-viewed content.
Another business-specific problem is that you might have time thresholds in your data. A view may be relevant one day then useless the next because the business has entered a new time cycle.
We built and tested many algorithms to find multiple methods of ranking our content to show relevancy for our business. Your organization’s needs, user base, schedules, and data will all shape how you choose to display and rank content to help users find the most relevant pieces.
Your thoughts?
Next week, I’ll outline how we built the search functionality, which posed one of the biggest technical challenges. In the meantime, let us know how you’ve been managing the growth of your Tableau Server deployment in the comments below.
Learn more about building a culture of self-service analytics
Data Diaries: A Hiring Guide for Building a Data-Driven Culture
Data Diaries: How VMware Built a Community around Analytics
Data Diaries: Defining a Culture of Self-Service Analytics
Building a Culture of Self-Service Analytics? Start with Data Sources
In a Culture of Self-Service Analytics, Enablement Is Crucial
Boost Your Culture of Self-Service Analytics with One-on-One Support
관련 스토리
How EMD Serono is improving patient care with personalized, AI-powered insights from Tableau
 2024/09/30
2024/09/30

Embedded Analytics: Should you build or buy?
 2022/06/07
2022/06/07
Data fabric’s value to the enterprise
 2022/05/11
2022/05/11