Tableau 및 Amazon Aurora를 통한 SQL 분석 사용




때는 분기 말이고 팀은 일주일 내내 거래를 성사시키느라 바빴습니다. 여러분은 할당량에 얼마나 근접했는지 알아야 하지만 문제가 있습니다.
여러분이 사용하는 추출 데이터 집합은 매일 밤 업데이트되고 여기에 오늘 마무리된 거래는 포함되지 않습니다. SQL 데이터베이스에 연결하지만 데이터베이스는 쓰기 작업 보호를 위해 잠겨 있습니다. 여러분은 상황을 모르는 상태에서 작업해야 하는데, 그 이유는 데이터베이스가 데이터를 저장하고 수집하는 동안 회사의 분석 요구 사항을 안정적으로 서비스할 수 없기 때문입니다.
이는 많은 사람에게 익숙한 상황입니다. 대부분의 조직에서 SQL 데이터베이스는 신성불가침 영역입니다. 날마다 DBA는 쓰기 작업을 보호하고 데이터베이스 스토리지 요구 사항을 준수하여 무슨 일이 있더라도 모든 데이터 요소는 미래를 대비하여 정확하게 기록되어야 합니다.
분석이요? 대부분의 경우 분석은 기다릴 수 있습니다. 추출은 이른 아침처럼 하루 중 바쁘지 않을 시간에 예약할 수 있습니다. 업무 시간(비즈니스 사용자가 실제로 질문을 할 때) 중 데이터베이스에 라이브로 연결하는 것은 위험하고 불필요합니다. 안타깝게도 그렇기 때문에 매우 조심스럽게 저장 및 관리되고 있는 데이터의 유용성이 제한됩니다.
적어도 최근까지는 그랬습니다. Amazon Aurora(읽기 복제본 포함)를 통해 Tableau 사용자는 데이터베이스에 직접 연결하여 원하는 시간에, 기본 데이터베이스에 대한 쓰기 작업에 영향을 주거나 방해하지 않고 자신이 원하는 분석을 수행할 수 있습니다.
Tableau와 Aurora가 함께 작동하는 방식
읽기 복제본은 본질적으로 읽기 작업에 할당된 Aurora DB 클러스터의 독립적인 엔드포인트이며, 데이터베이스가 활용하는 AWS 지역 내 3개의 가용 영역에 최대 15개까지 배포할 수 있습니다. 단일 리더 엔드포인트는 읽기 복제본에 대한 액세스를 제공합니다. 모든 읽기 요청은 Aurora 클러스터의 모든 읽기 복제본 간에 로드 밸런싱되며, 이를 통해 회사의 분석 요구 사항을 처리하면서 어느 한 읽기 복제본에 과도하게 로드가 가중되지 않도록 보장합니다.
읽기 복제본은 Tableau와의 직접 연결에 매우 유용합니다. 분석가가 모든 필드를 드래그 앤 드롭하거나, 데이터베이스 자체에 어떤 영향이 있을지 고려하지 않고 어떤 쿼리든 생성할 수 있기 때문입니다. Tableau의 최적화된 커넥터는 Aurora에 이미 최적화된 SQL을 생성하며, 그 결과 자동적으로 성능을 최적화하는 효율적이고 직접적인 SQL이 생성됩니다.
또한 Tableau 사용자는 계층, 폴더, 그룹, 계산을 생성하고 데이터를 정리 및 관리할 수 있도록 필드의 별칭을 수정할 수 있습니다. 사용자는 Aurora 읽기 복제본에 대한 직접 연결을 통해 해당 메타데이터 정의를 Tableau Server에 게시할 수 있습니다. 이렇게 하면 사용 권한이 있는 경우 누구나 연결하고 마음대로 사용할 수 있는 단일 버전 데이터를 효과적으로 확보할 수 있습니다.
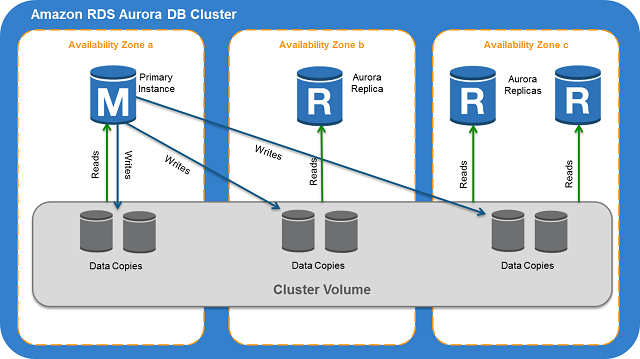 Aurora의 읽기 복제본 아키텍처
Aurora의 읽기 복제본 아키텍처
또한 Tableau Server는 삽입된 사용 권한이 Aurora 인스턴스에 이미 설정한 행 수준 사용 권한을 따르도록 허용합니다. 또는 Tableau Server 자체에 있는 모든 뷰, 통합 문서, 폴더 또는 그룹에 대한 사용 권한 수준을 설정할 수 있습니다. 사용 권한 지정 수준에 따라 권한 있는 사람들만 민감한 데이터를 보고 문제나 마찰 없는 실행을 보장할 수 있습니다.
간단히 말해서 Tableau와 Aurora는 대부분의 SQL 데이터베이스 사용에 따르는 분석의 제약을 해소할 수 있는 강력한 조합입니다. 따라서 데이터 분석이나 추출 업데이트를 기다리지 않아도 되며 단지 Aurora에 대한 직접적이고 안전하며 효율적인 연결, 드래그 앤 드롭 비주얼라이제이션 및 용이한 공유가 가능합니다.
Tableau와 Aurora의 작동 방식을 보려면 11월 2일에 열리는 심층 웹 세미나 및 데모에 참여해 보십시오.
관련 스토리

Supercharge Analytics with the Power of AWS-Hosted TabPy
 2024/10/14
2024/10/14

Tableau and dbt Labs: Strategic Partnership and Integration
 2024/10/08
2024/10/08
Tableau + AWS: Accelerating your digital transformation with Modern Cloud Analytics
 2023/11/27
2023/11/27
Tableau and AWS help customers digitally transform with Modern Cloud Analytics, combining technical resources and expertise with our vast partner networks.