Tableau
Tableau は、信頼できる意思決定をデータに基づいて行えるよう支援します。必要なときに提示されるインテリジェントなインサイトを誰もが利用できるようにして、いっそう迅速でスマートなアクションを実現。適応力があるコネクテッド時代の分析プラットフォームを活用して、あらゆる一歩でイノベーションを起こしましょう。
ビデオを見るTableau 製品のポートフォリオ
Tableau Cloud
完全ホスティング型でクラウドベースの分析プラットフォームです。データに接続して、強力なビジュアル分析機能で分析し、インサイトをセキュアに共有することができるうえ、サーバーやインフラストラクチャの管理は不要です。
Tableau Server
セルフホスティング型の分析プラットフォームです。データと分析環境を完全な管理下に置くことができ、自社インフラストラクチャにもクラウド (プライベートやパブリックのインスタンス) にも導入が可能です。
Tableau Next
AI、信頼できるデータ、モジュラーアーキテクチャ、ワークフローの直接統合機能を組み合わせた、オープンな分析プラットフォームです。取得したインサイトから、これまでになく迅速でスマートなアクションをとることができます。
Tableau Desktop
柔軟性の高い管理された分析環境です。いつでもどこでもオフラインであっても、データの探索やモデリング、視覚化を行って、インテリジェントなインサイトを迅速に取得し、アクションに移すことができます。
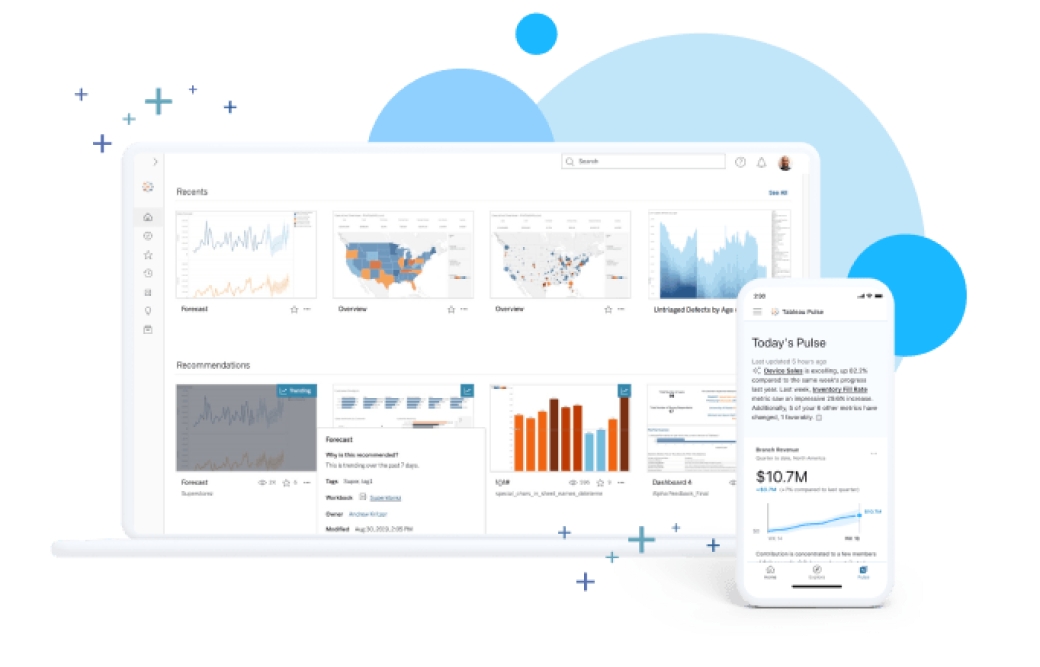
データ活用を始めて Tableau でビジネスを推進
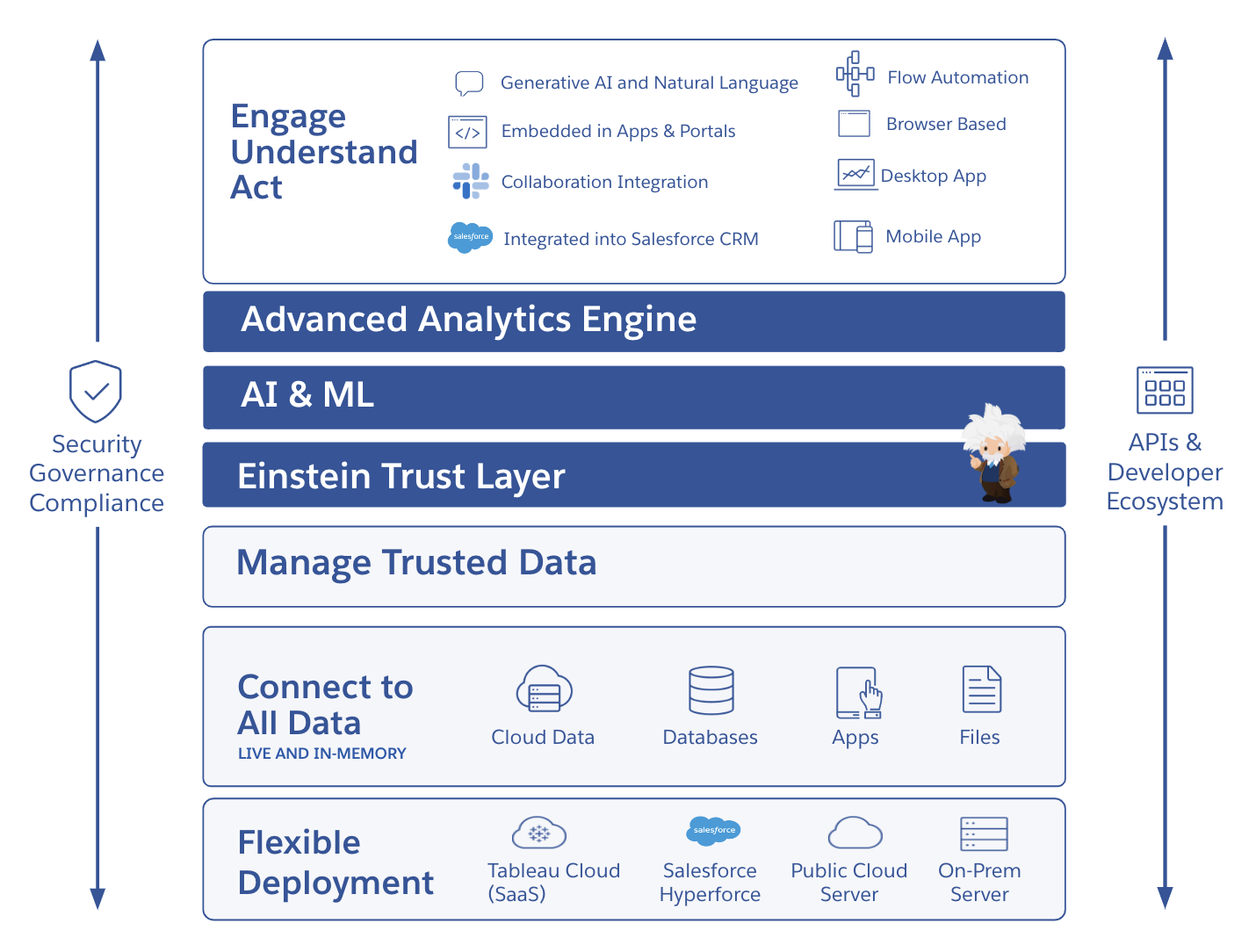
Tableau は、業務を行っている場所でインサイトを得られるよう設計された、使いやすいセルフサービス分析クラウドプラットフォームを提供しています。Salesforce Einstein でスピーディに導入可能な信頼できる AI は、データ、分析ユースケース、さらにはセマンティックレイヤーやワークフローでもお客様を支援します。また、データガバナンス、セキュリティ、コンプライアンスの機能が組み込まれており、ご利用のテクノロジー環境や AI 戦略の発展に追従する、豊富な選択肢と極めて高い柔軟性を備えています。
世界中の組織のニーズを支援することに力を注いでいる Tableau。パートナーと成功のエコシステムは業界最大級です。その一端を担う活発な Tableau コミュニティは、AI の取り組みのあらゆる段階にわたって指導、支援、チャレンジ、称賛という形でお客様をサポートします。
主な機能
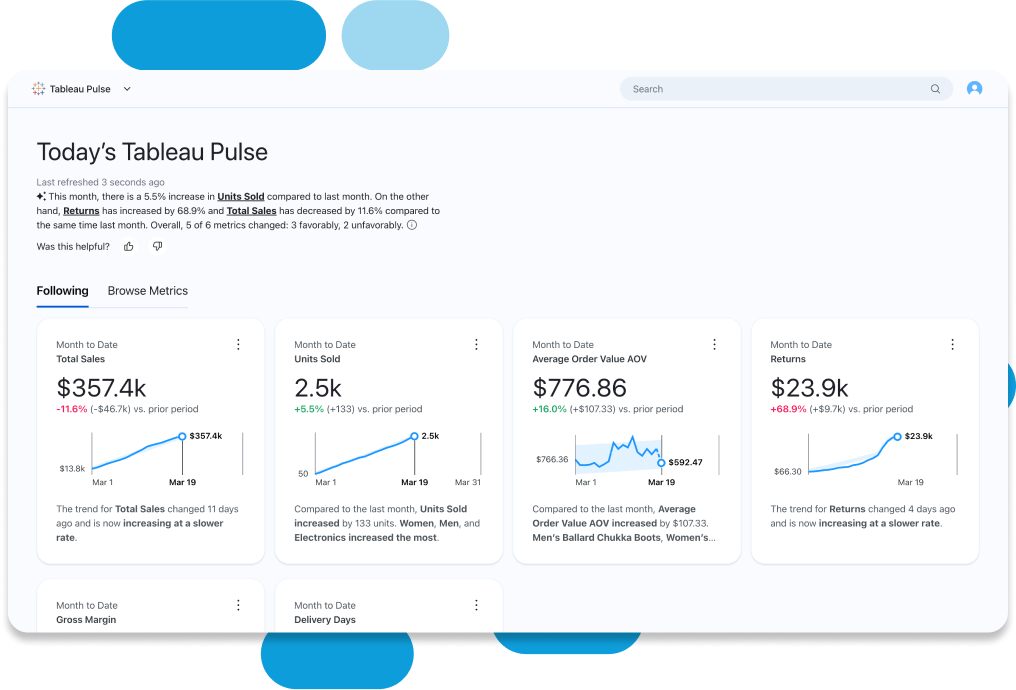
直感的なデータエクスペリエンスをすべての人に
組み込まれている Einstein インサイト機能を使った容易なデータ探索を始めて、意思決定の質を高めましょう。一目でわかるようにデータを視覚的に表示するとともに、裏側では自動化を行うことで、Tableau は分析データにビジネスコンテキストと意味を自動的に付加。適切なデータを見出して理解できるように支援します。また、VizQL により、簡単なドラッグ & ドロップ操作でデータ探索を行えます。ダッシュボードにわかりやすいナラティブを自動的に追加して分析をスピードアップし、自然言語で重要なビジネス課題を分析して答えを導き出し、Tableau Pulse を利用してメトリクスをパーソナライズすることも可能です。
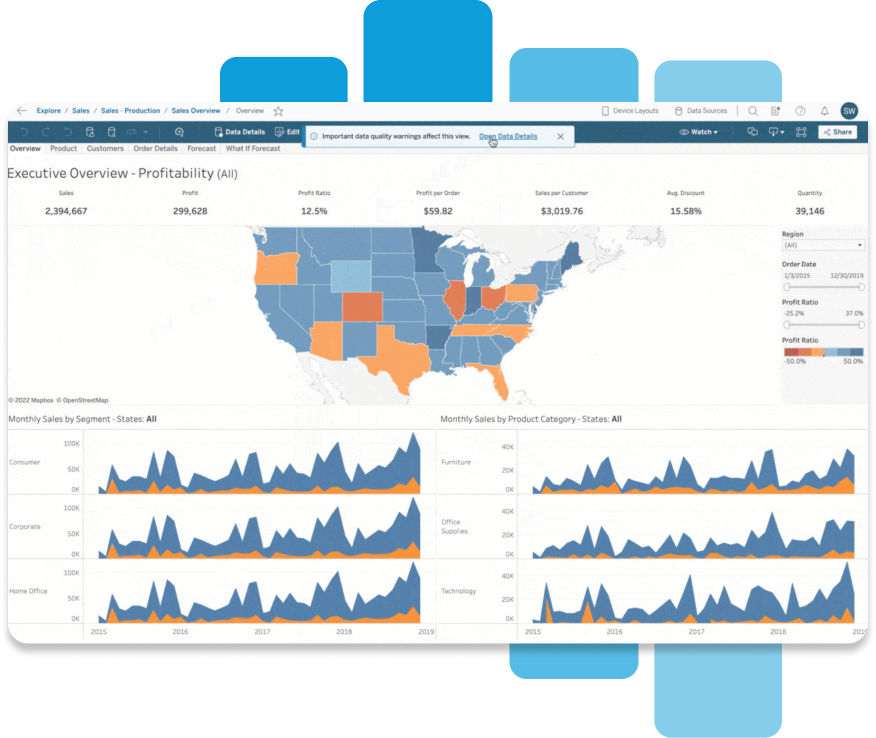
全データに対する信頼と信用
可視性、ガバナンス、コントロールとともに、信頼の置けるセキュアなデータを必要な場所で利用できる環境も実現できます。ご利用のシングルサインオン (SSO) プロバイダーや ID プロバイダーとの統合が可能です。1 つの環境で使用状況をモニタリングして、コンプライアンスを効率的に維持しましょう。SOC 2 や ISO などの最高クラスのセキュリティ認証規格に対応した、最新のインフラストラクチャをご利用いただけます。また、Tableau Cloud Enterprise、Tableau+、Tableau Server Enterprise では Data Management 機能により、信頼できるデータをシンプルに、繰り返して拡張することもできます。
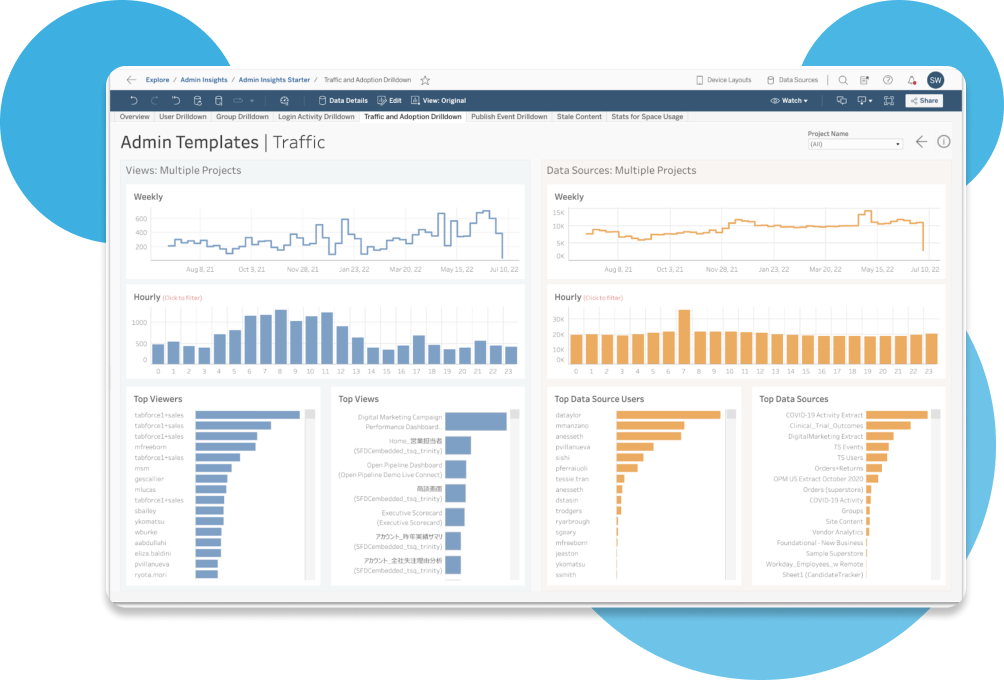
柔軟性の高いオープンなプラットフォームで規模拡大を簡単に
再利用可能なモデルと分析結果を使って、独自にデータアーキテクチャを構築、規模拡大しましょう。サーバーの構成、ソフトウェアのアップグレード管理、ハードウェアのキャパシティ拡張が不要になり、時間と費用を削減することができます。データのディスカバリ、共有、コラボレーション、探索も、Tableau ならモバイルデバイスやタブレット、PC で行えるため、チームの連携が加速します。制限のないスケーラビリティ、最大の効率性、セキュリティのシンプル化を実現する Advanced Management 機能で管理しながら、ミッションクリティカルな分析環境の容易な構築、規模拡大が可能です。また、Tableau Pulse のメトリクスレイヤーでデータの標準的な定義を作成して、インサイトと分析を強化することもできます。ネイティブアプリケーションから、アクセラレーター、コネクタ、拡張機能などを利用して分析をすぐ始めましょう。
インサイトに基づく意思決定を 33% 増加させる Tableau
![]()
![]()
![]()
![]()

データの面で組織が成長するにしたがい、要件も増えて高コスト化したため、当社はニーズに合わせて成長する、つまり拡張できるプラットフォームを必要としていました。

第一歩は Tableau コミュニティへの参加から
Tableau コミュニティに参加しましょう。データと分析の取り組みで支援を得て、データビジュアライゼーションのスキルをレベルアップすることができます。データを通じた強いつながりで、新たな可能性が広がります。
今すぐ参加プランと価格
Tableau Creator
Tableau Desktop でデータへの接続、ビジュアライゼーションの作成、ダッシュボードのパブリッシュを行えます。
年間契約
利用できる製品: Tableau Desktop、Tableau Prep Builder、Tableau Cloud の Creator 1 ライセンス。
Tableau Explorer
既存のダッシュボードの編集。チームと組織のためのライセンスプログラムです。
Tableau Viewer
既存のダッシュボードの利用。チームと組織のためのライセンスプログラムです。