Tableau
Com o Tableau, você tem acesso a dados para tomar decisões confiáveis. Forneça a todas as equipes informações relevantes na hora certa, para que elas possam avançar com maior rapidez e inteligência. Promova a inovação a cada etapa com uma plataforma de análise conectada e adaptável.
O que é o Tableau? Avalie gratuitamente
Assista agoraConfira o portfólio de produtos da Tableau
Tableau Cloud
Com uma plataforma de análise totalmente hospedada e baseada em nuvem, você pode se conectar aos dados, analisá-los usando análises visuais avançadas e compartilhar informações com segurança, sem a necessidade de gerenciar servidores ou infraestruturas.
Tableau Server
Com uma plataforma de análise auto-hospedada, você tem controle total sobre os dados e a implantação de análises, seja na sua própria infraestrutura ou na nuvem (instâncias privadas e públicas).
Tableau Next
Com uma plataforma de análise aberta que combina IA, dados confiáveis, arquitetura modular e integração direta no fluxo de trabalho, você tem acesso a informações para tomar decisões da maneira mais rápida e inteligente possível.
Tableau Desktop
Com um ambiente governado e flexível, você pode explorar, modelar e visualizar dados a qualquer hora e em qualquer lugar, mesmo off-line. Você também pode descobrir informações inteligentes para tomar decisões com rapidez.
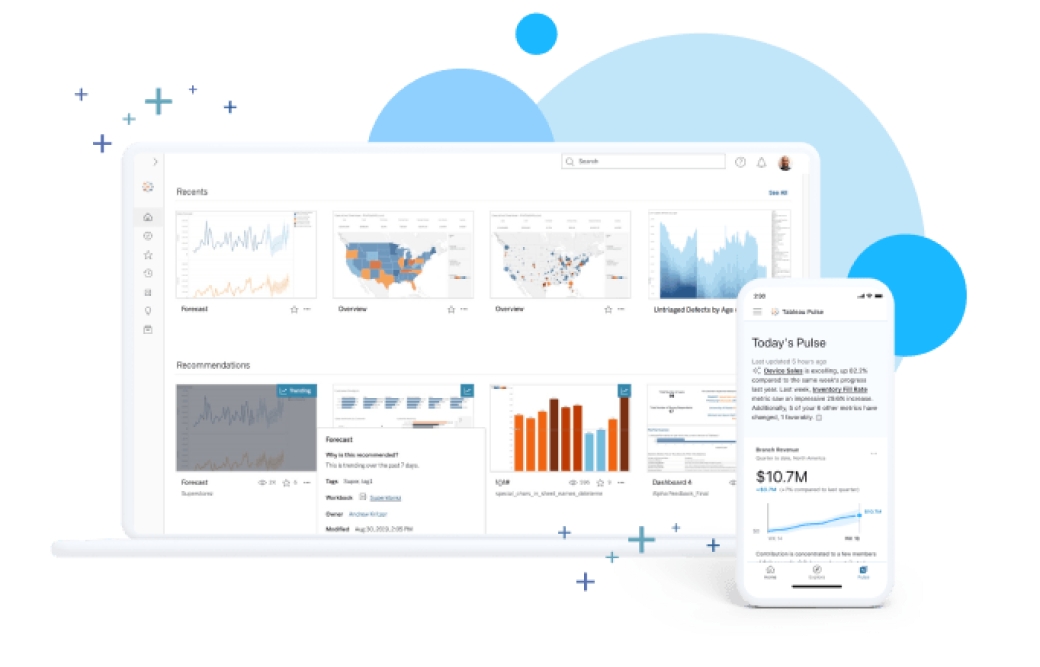
Comece com os dados. Siga em frente com o Tableau.
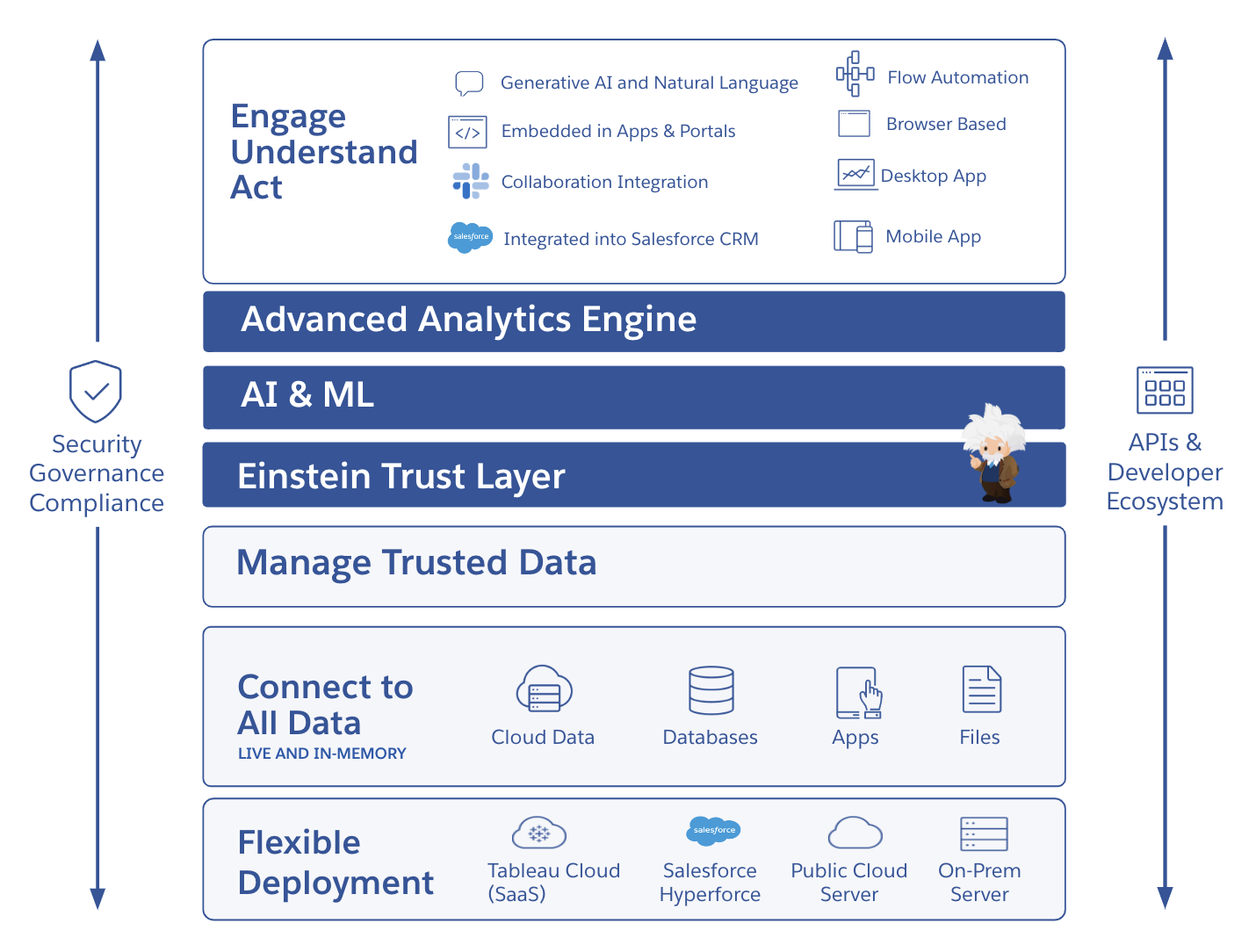
O Tableau oferece uma plataforma de análise na nuvem com autoatendimento e fácil de usar, projetada para fornecer informações onde o seu trabalho acontece. Implemente a IA confiável rapidamente para casos de uso de dados e análises com o Salesforce Einstein, que se estende profundamente na camada semântica e nos fluxos de trabalho. Com a integração da governança de dados, da segurança e da conformidade, o Tableau oferece mais opções e flexibilidade para acompanhar a evolução da sua tecnologia e estratégia de IA.
A Tableau está comprometida em dar suporte às necessidades de organizações ao redor do mundo com o maior ecossistema de parceiros e sucessos, incluindo a incrível Comunidade do Tableau, que pode oferecer ensinamentos, suporte, desafios e motivação a você em cada estágio da jornada de IA.
Principais recursos
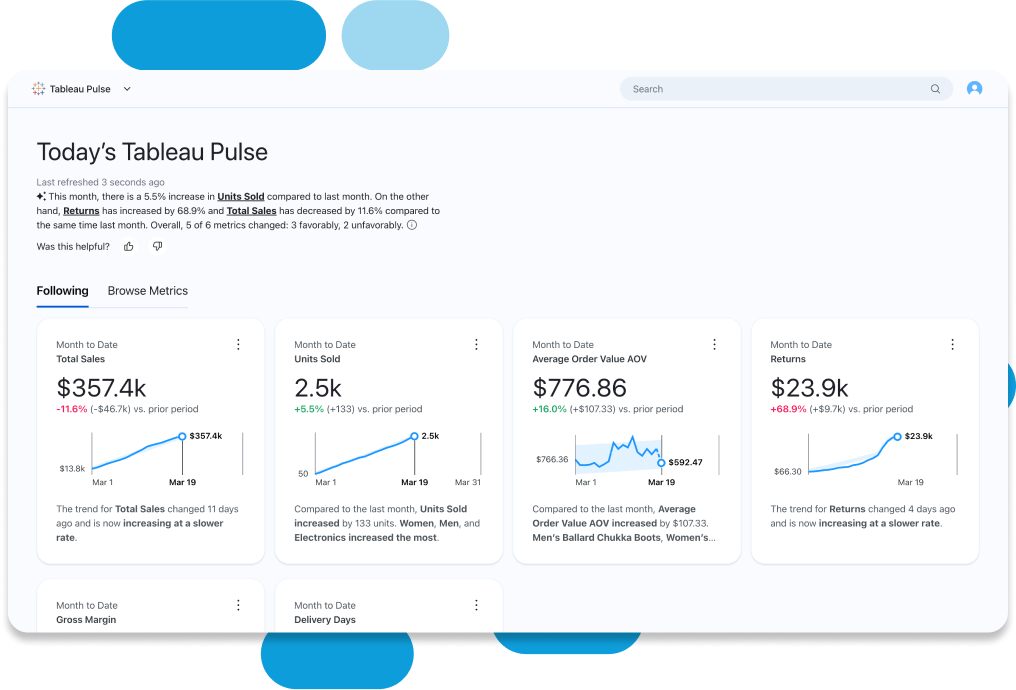
Experiências de dados intuitivas para todos
Comece a explorar dados com facilidade e realize a integração das informações fornecidas pelo Einstein para tomar decisões melhores. Com uma representação visual rápida dos dados e a adoção da automação, o Tableau enriquece automaticamente os dados de análise com contexto e significado empresariais, o que ajuda você a descobrir e entender as informações relevantes. Com o VizQL, a exploração de dados pode ser tão fácil quanto arrastar e soltar ícones. Torne as análises mais rápidas adicionando narrativas automatizadas e fáceis de entender aos painéis, use linguagem natural para explorar e responder a perguntas empresariais fundamentais e personalize métricas usando o Tableau Pulse.
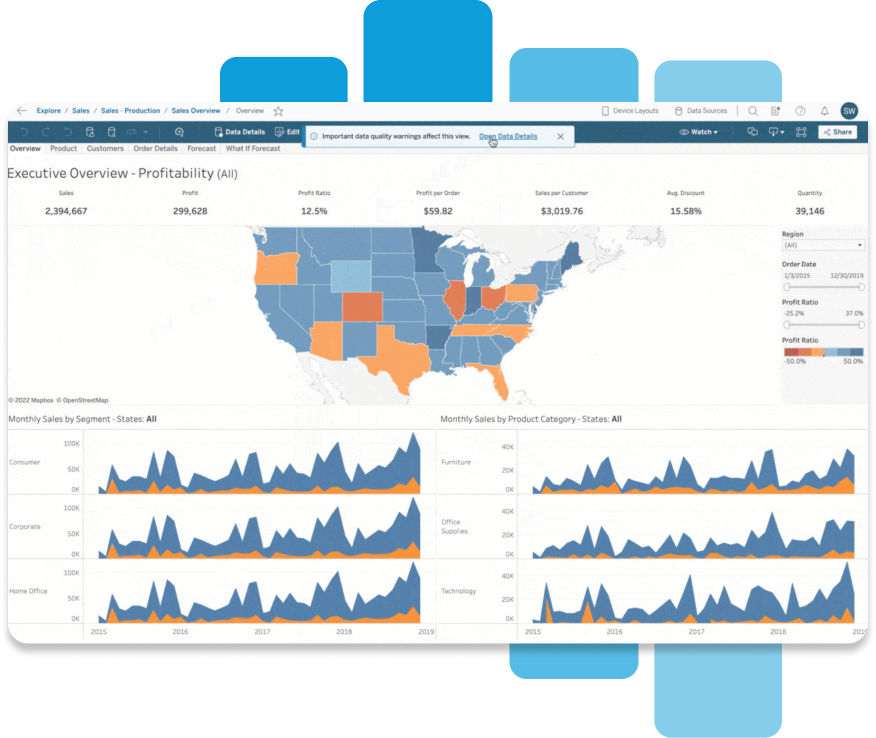
Confie em todos os seus dados
Disponibilize dados seguros e confiáveis onde for necessário, garantindo a visibilidade, a governança e o controle. Faça a integração com seu logon único (SSO) ou provedor de identidade. Monitore o uso em um ambiente para manter a conformidade com mais eficiência. Aproveite uma infraestrutura atualizada com os melhores padrões de certificação de segurança da categoria, como o SOCII e o ISO. Os recursos do Tableau Data Management podem disponibilizar dados confiáveis em escala de maneira simples e replicável para o Tableau Cloud Enterprise, o Tableau+ ou o Tableau Server Enterprise.
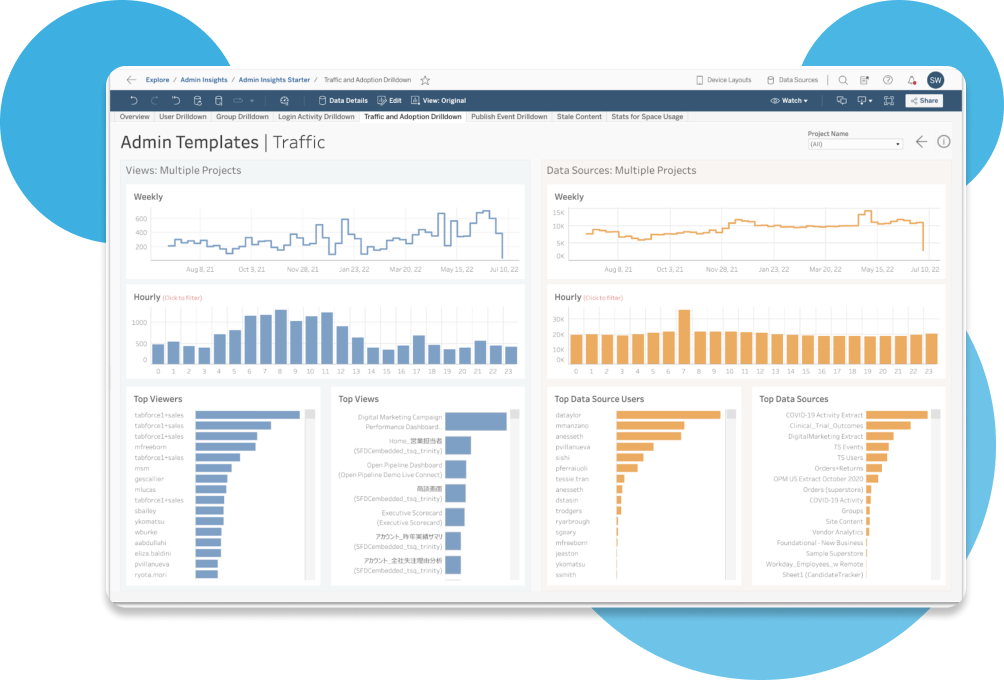
Escalone facilmente usando uma plataforma aberta e flexível
Crie e escalone a arquitetura de dados como preferir com modelos e análises reutilizáveis. Nunca mais será preciso configurar servidores, gerenciar atualizações de software ou escalonar a capacidade do hardware, o que poupa tempo e dinheiro. Turbine o trabalho em equipe ao descobrir, compartilhar, colaborar e explorar dados com o Tableau em seu celular, tablet ou computador. Crie e escalone análises essenciais com facilidade e mantenha o controle dos recursos do Advanced Management, que oferece escalonabilidade ilimitada, eficiência otimizada e segurança simplificada. Crie uma definição padrão dos seus dados para potencializar informações e análises com a camada de métricas do Tableau Pulse. Obtenha acesso a aplicativos nativos para começar suas análises com aceleradores, conectores, extensões e muito mais.
Utilize o Tableau e aumente em 33% a tomada de decisões baseada em informações.
![]()
![]()
![]()
![]()

À medida que a organização se expandiu em termos de dados, os requisitos também aumentaram e ficaram mais caros. Nós precisávamos de uma plataforma que pudesse ser escalonada a fim de atender às nossas necessidades crescentes.

Participe da comunidade do Tableau
Participe de uma comunidade que ajuda você em sua jornada de dados e análise, aprimora suas habilidades de visualização de dados e cultiva conexões importantes. Quando as pessoas estão unidas pelos dados, tudo é possível.
Participe agoraPlanos e preços
Comece hoje mesmo a contar histórias com dados.
| Economize agora | Use o código promocional: TABCREATOR10 |
*Novos clientes da Tableau ganham 10% de desconto na compra de duas ou mais licenças Creator do Tableau. Consulte os termos e condições.
Tableau Creator
Conecte-se a seus dados, crie visualizações e publique painéis no Tableau Desktop.
Cobrança anual
Inclui: Tableau Desktop, Tableau Prep Builder e uma licença Creator do Tableau Cloud.
Tableau Explorer
Edite painéis já existentes. Disponível para equipes e organizações.
Cobrança anual
Inclui: Uma licença Explorer do Tableau Cloud.
Tableau Viewer
Acesse painéis já existentes. Disponível para equipes e organizações.
Cobrança anual
Inclui: Uma licença Viewer do Tableau Cloud.