Como unir o Tableau e o Python para possibilitar análises prescritivas com o TabPy



Uma versão deste artigo do blog foi publicada originalmente no Medium.
O TabPy é um pacote do Python que permite executar código do Python dinamicamente e exibir os resultados em visualizações do Tableau. Assim, você pode implantar aplicativos de análise avançada com mais rapidez. Graças à abordagem segmentada que o TabPy oferece, os usuários podem aproveitar o melhor das duas tecnologias: recursos de visualização de dados líderes do mercado, com o respaldo de algoritmos sofisticados de ciência de dados. Um grande benefício de trazer algoritmos do Python para o Tableau é permitir que os usuários ajustem parâmetros e avaliem seu impacto na análise em tempo real à medida que o painel é atualizado.
Para tornar isso possível, o TabPy emprega principalmente uma abordagem de entrada/saída em que os dados são agregados de acordo com a visualização atual e ambos os parâmetros de ajuste são transferidos para o Python. Os dados são processados, e uma saída é enviada para o Tableau para atualizar a visualização atual. Vamos supor que você precise de todo o conjunto de dados subjacente para um cálculo, mas seu painel está apresentando uma medida agregada, ou você deseja mostrar vários níveis de agregação ao mesmo tempo. Além disso, talvez você queira usar várias fontes de dados em um único cálculo sem comprometer a capacidade de resposta do painel.
Neste artigo, explicarei uma abordagem que ajudará você a aproveitar todo o potencial do TabPy nos seguintes cenários:
- Interação em tempo real: você quer uma interface do usuário que funcione em tempo real, minimizando o tempo de processamento e a latência entre a alteração de um parâmetro e a atualização da visualização.
- Vários níveis de agregação: você deseja mostrar (vários) níveis de agregação nos mesmos painéis do Tableau, mas precisa fazer todos os cálculos no nível mais específico e granular, que contém todas as informações.
- Várias fontes de dados: o cálculo no backend depende de mais de uma fonte de dados e/ou banco de dados
- Dados transferidos entre o Tableau e o Python: uma grande quantidade de dados é necessária para cada etapa de otimização, de modo que muitos dados devem ser transferidos entre o Tableau e o backend do Python.
Uma nova abordagem do TabPy para análises prescritivas: instruções passo a passo
Para implementar o TabPy, pressupondo que tanto o Python quanto o TabPy já estejam instalados, você precisará seguir três etapas:
- Preparar um rascunho do painel do Tableau
- Criar o backend das rotinas de cálculo no Python
- Fazer o design do frontend do Tableau integrando o backend
Para explicar as três etapas, elaborei um caso de uso centrado na redução da complexidade por meio da otimização do portfólio de produtos.
O caso de uso: redução da complexidade
O candidato para a otimização é um atacadista que teve um crescimento decorrente principalmente de fusões e aquisições. Devido a esse crescimento não orgânico, o atacadista enfrenta um alto nível de complexidade, opera em vários mercados e tem um portfólio composto por mil SKUs (unidades de manutenção de estoque) divididas em várias categorias e subcategorias. Para complicar, as SKUs são criadas em várias fábricas.
A gerência sênior da empresa quer aumentar as margens de lucro eliminando as SKUs menos rentáveis, mas está disposta a continuar vendendo produtos de baixo desempenho para manter sua participação em determinados mercados. Ela também está disposta a manter as fábricas operando acima dos limites de utilização de recursos, pois sabe que uma redução excessiva da utilização prejudicaria a base de custos fixos de cada fábrica.
Os dados disponíveis neste exemplo consistem em um banco de dados de SKUs em que os volumes, custos e receitas anuais são registrados. As SKUs são organizadas nos níveis hierárquicos Categoria e Subcategoria.
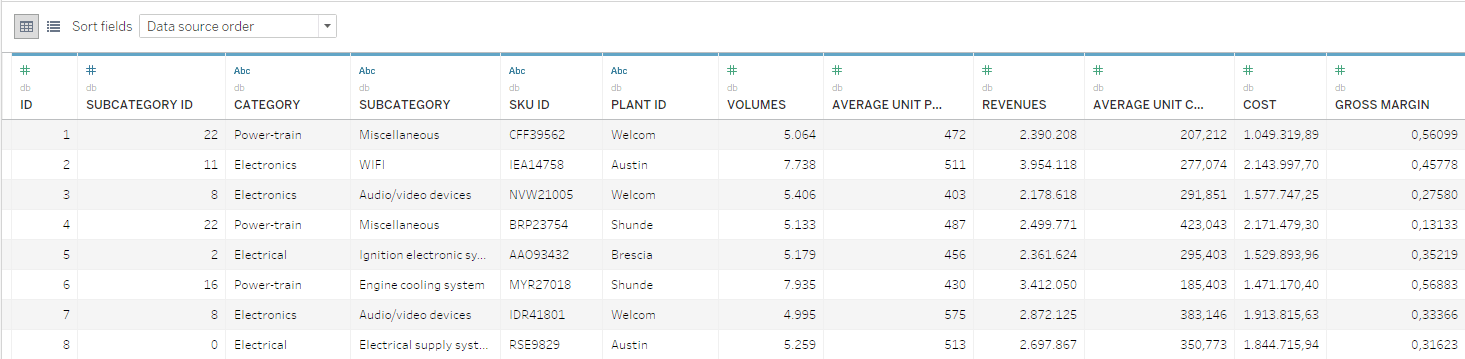
De um ponto de vista matemático, a tarefa de gerenciar a otimização do portfólio de produtos é bastante simples. Porém, a otimização também deve considerar todas as nuances estratégicas e incluir a participação de diversas pessoas que têm acesso às informações e ferramentas necessárias para tomar decisões embasadas.
A abordagem do TabPy descrita a seguir atende a todos esses requisitos:
1. Preparar um rascunho do painel do Tableau
Primeiramente, é importante chegar a um consenso sobre o problema que precisa ser resolvido. Neste exemplo, o algoritmo de otimização simples removerá as SKUs de acordo com sua margem bruta, avaliando cada SKU individual.
-
Defina os parâmetros interativos no Tableau: observe que defini um segundo parâmetro complementar. Esse é o diretório onde será armazenado o pacote do Python com as rotinas de otimização. Esse tipo de parâmetro é muito útil para definir os cálculos personalizados, como veremos na próxima seção.
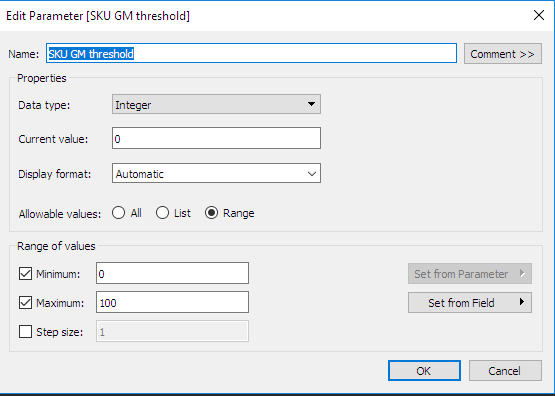
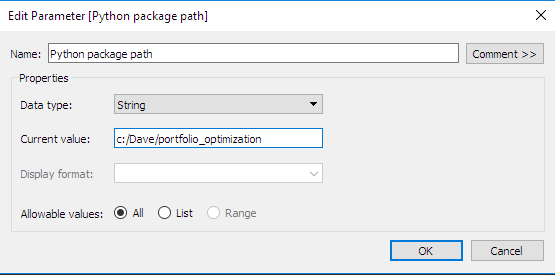
- Defina as exibições/os níveis de agregação: aqui estabelecemos dois níveis de agregação: o nível da SKU e o nível da subcategoria. A definição dos níveis de agregação é fundamental, pois determina as assinaturas das funções do backend do Python. Uma função específica deve ser definida por cálculo e por nível de agregação. Para cada nível de agregação, é necessário definir os seguintes parâmetros: margens otimizadas, receitas otimizadas e volumes otimizados.
-
Defina os ganchos dos cálculos (retornos de chamada) no Tableau: após definir os parâmetros de entrada, níveis de agregação e cálculos de saída necessários, será possível definir cálculos personalizados. Para fins de praticidade, todas as rotinas de otimização foram estruturadas em um pacote do Python chamado portfolio_optimization (otimização de portfólio), em que definimos funções que retornam as quantidades selecionadas para os níveis de agregação específicos. É importante observar que o parâmetro definido anteriormente (o caminho do pacote do Python) é passado para a função e usado no script para indicar onde o pacote de otimização de portfólio é armazenado. Além disso, o indexador do nível de agregação atual (por exemplo, para o nível de agregação de subcategoria, a própria subcategoria) sempre é enviado ao backend do Python para garantir que os resultados sejam retornados na ordem adequada. O parâmetro de entrada, o limiar de margem bruta de SKU, também é passado.
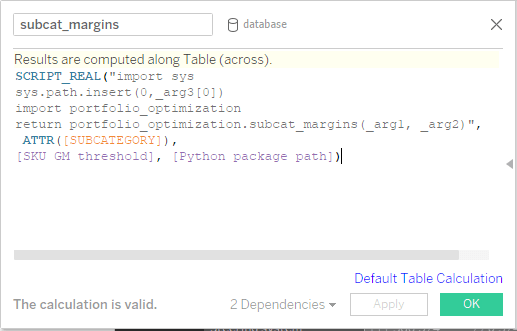
2. Criar o backend das rotinas de cálculo no Python
O backend do Python é dividido em duas classes de função, agrupadas de acordo com seu contexto de execução: as funções que são executadas uma única vez e as que se repetem várias vezes. Por exemplo, na primeira classe, estão as operações de extração, transformação e carregamento do banco de dados. Essas funções são chamadas de “funções únicas”. Já as outras são funções que se repetem várias vezes, como todos os retornos de chamada do Tableau:
- Operações únicas: neste exemplo, o banco de dados é carregado somente uma vez, quando o script é executado pela primeira vez. Em seguida, o banco de dados é armazenado em uma variável global para ser disponibilizado a todas as outras funções. Para detectar se o banco de dados já foi carregado ou não, o Python verifica o espaço de nomes local para ver se há uma cópia existente dele. Sem essa precaução, o banco de dados seria carregado sempre que um cálculo fosse solicitado pelo Tableau, o que prejudicaria a velocidade de execução.
- Retornos de chamada do Tableau: todos os ganchos definidos anteriormente devem ter uma função que dê acesso a eles. Em nosso caso, fazemos isso criando cálculos separados para receitas, volumes e margens e usando o indexador passado como a entrada da função para indexar a função groupby do Pandas, que é então usada para agregar os resultados da otimização. Vale notar que, para melhorar a velocidade da execução, os retornos de chamada implementam um detector de alteração de parâmetro. Uma nova otimização só será gerada se o parâmetro for alterado, e seu resultado estará disponível para todos os retornos de chamada que usarem uma variável global. A detecção da alteração de parâmetro é implementada por meio de uma variável persistente usada para armazenar seu valor na execução anterior. Essa abordagem garante o uso do mínimo possível de operações onerosas, melhorando a velocidade de execução.
3. Definir o design do frontend do Tableau
Nesta etapa, já definimos todos os elementos fundamentais, incluindo os níveis de agregação, parâmetros a serem ajustados e colunas de saída retornadas pelo backend dos cálculos.
Para facilitar as discussões sobre a otimização, crie duas planilhas separadas que representem o portfólio antes e depois do processo de otimização. Mostre as duas planilhas lado a lado.
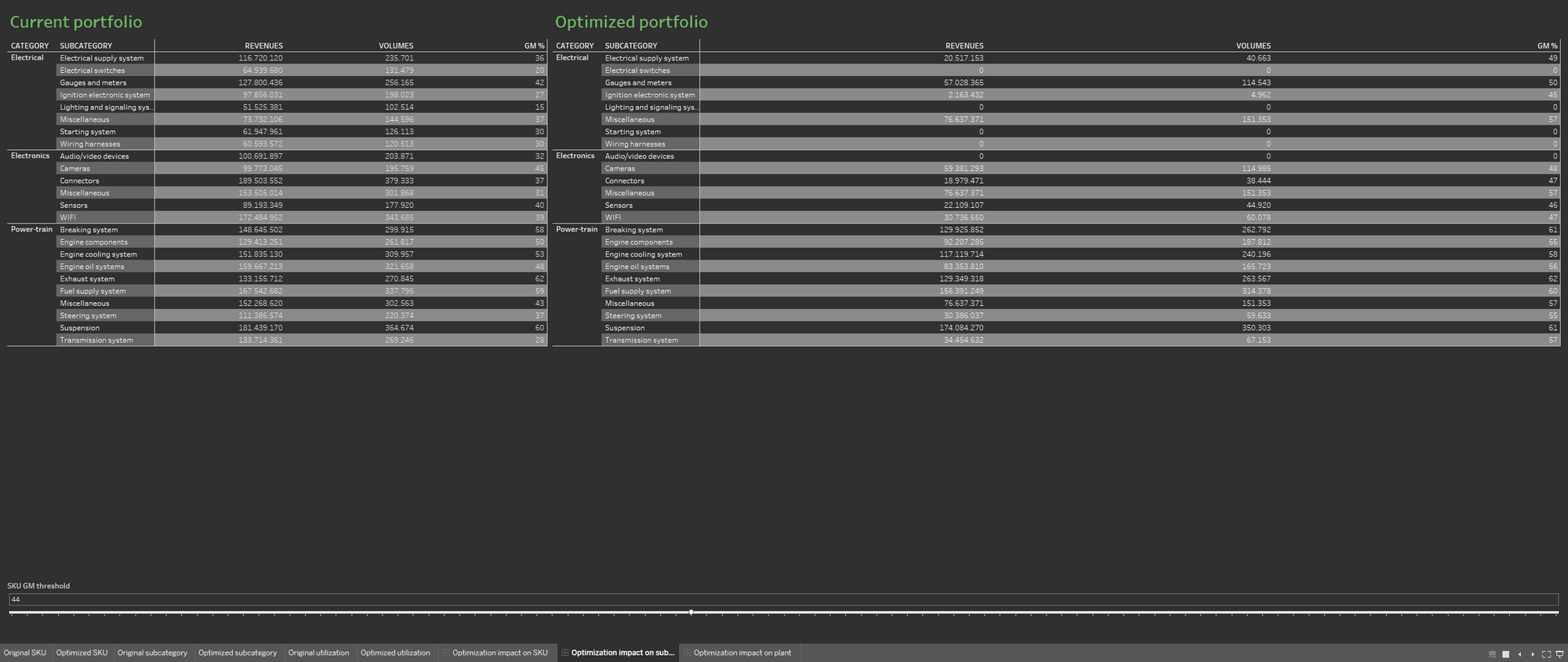
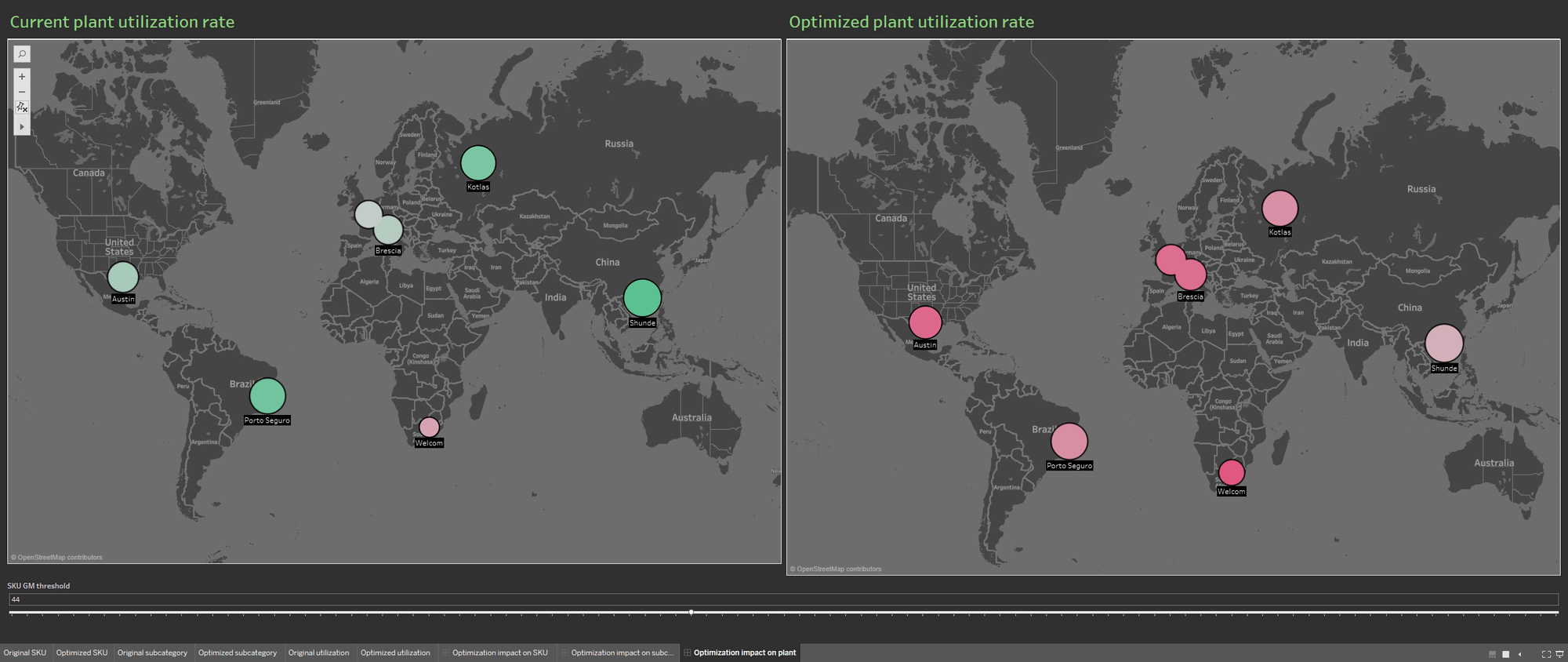
A disponibilidade de várias fontes de dados enriquece o banco de dados do portfólio trazendo para a visualização informações sobre a taxa atual de utilização da fábrica e sobre a taxa resultante do portfólio otimizado. Reiteramos que o ideal é apresentar as visualizações de informações lado a lado para demonstrar o impacto da otimização nas fábricas de produção.
Mais benefícios de usar o TabPy nas equipes
Além do alto valor comercial alcançado quando as equipes podem interagir em tempo real com técnicas sofisticadas de ciência de dados, esta nova abordagem também traz benefícios significativos para o backend. Muitas outras técnicas de visualização de dados requerem a participação de cientistas de dados durante todo o processo, o que custa caro. Porém, com essa abordagem, os cientistas de dados são necessários apenas para preparar o rascunho do painel do Tableau e criar as rotinas de cálculo do Python para o backend. A facilidade de uso do Tableau proporciona uma variedade maior de recursos para criar o design do frontend, testá-lo com os usuários finais e fazer sua manutenção.
O design do frontend geralmente é um processo demorado e iterativo que envolve várias discussões com os usuários finais. Ao permitir que os gerentes variem a composição da equipe durante a execução do projeto, a nova abordagem do TabPy pode trazer mais economia. Essa abordagem também garante a alta reusabilidade do backend subjacente, permitindo que um amplo grupo de usuários crie seus próprios painéis personalizados no Tableau adaptados a contextos, situações e públicos-alvo específicos. Essa reutilização da lógica de cálculo e dos elementos fundamentais subjacentes é outra forma de otimizar o custo da visualização de dados de modo geral.
Caso você tenha interesse em explorar mais a fundo o exemplo, tanto o painel do Tableau como o backend do Python estão disponíveis aqui. Para conferir informações adicionais sobre essa abordagem, consulte o repositório oficial do TabPy no Github ou visite este tópico da comunidade do Tableau.
Histórias relacionadas
VizQL Data Service from Tableau: Use Your Data, Your Way
 8 Agosto, 2024
8 Agosto, 2024

When and How to Use Multi-fact Relationships in Tableau
 1 Agosto, 2024
1 Agosto, 2024

