Building Serverless Prototypes



At the Tableau Prototyping team, our mission is to drive innovation through exploring and prototyping new ideas. Often these are most easily proven out through simple web apps that allow users to explore our ideas and allow us to verify our projects’ usefulness. We want to build fast and stay flexible — spending large amounts of time to set up a bespoke infrastructure for each of our new projects takes away from the time we have to work on core algorithms or project innovations.
When designing our prototyping systems, we needed to find an infrastructure solution that allowed us to adapt where necessary, but have a fairly consistent and maintainable setup. Crucially, we also did not want to sink much time into upkeep after a prototype is built. Ideally any prototyping project can stay “on the shelf” for anyone to find and work with after we’ve wrapped up the initial engineering. Our goal was to set up a repeatable infrastructure for prototypes that would meet these projects’ recurring needs: always on, low cost, and low maintenance.
A Serverless Architecture
The wide variety of potential projects and expected usage means running our own server-side code is inefficient. Amore traditional setup might make sense, if building a single app or new product, but is unwieldy for our purposes. Running the app in an EC2 instance means not running the server ourselves however it still requires the team to patch the instance OS. We would also need to carefully manage instance lifetimes or pay for always-on.
Instead, our requirements made using serverless computing an obvious choice. With these guidelines we settled on a simple AWS architecture based on Lambdas using the Serverless Framework. The basic infrastructure with Lambdas, S3, and DynamoDB is as follows:
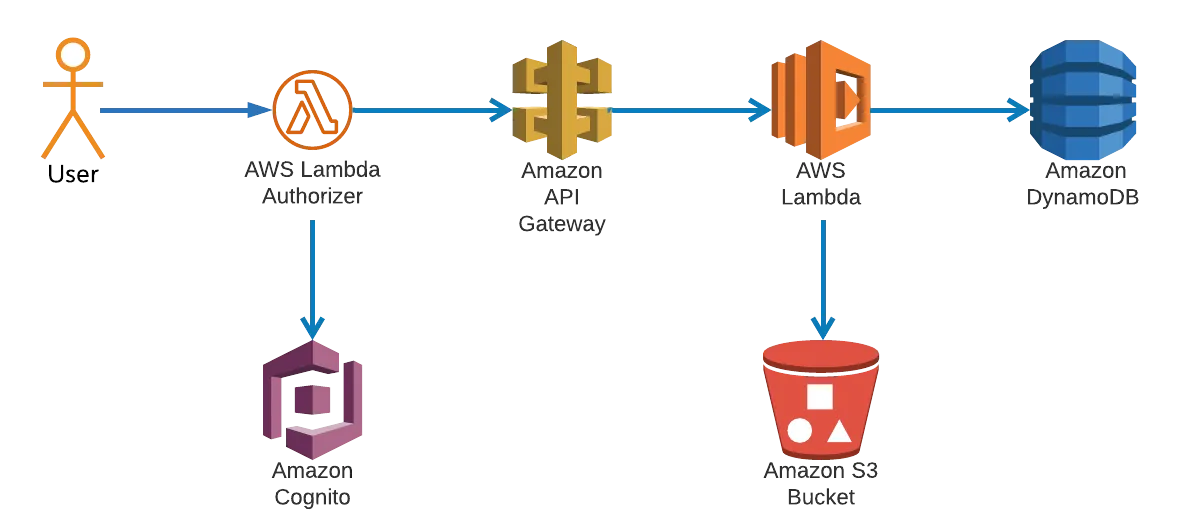
In this setup, a user is verified through a lambda authorizer (connecting to a Cognito user pool in our example) and then makes calls through an API gateway. Any of our prototypes can have a custom set of functions that may read from and write data to a DynamoDB table and/or read from and write files to an S3 bucket. This infrastructure is simple and repeatable — the code the functions themselves run differs from prototype to prototype, but the fundamental structure can remain the same.
The Serverless Framework, in particular, is well-suited for our prototyping. It lets us set up our infrastructure as code, making it much easier to turn over the prototype to any interested consumer/team in the future, or for our team to pick it back up after significant time away from the project. Serverless also makes it simple to clean up resources automatically or remove old CloudFormation stacks, making our maintenance costs even lower. While these things can be accomplished with basic CloudFormation templates, as a team we found Serverless files less verbose and more readable. Serverless made writing and deploying infrastructure code much faster than it otherwise might have been. It is easy to have a repeatable serverless.yml file for each project where just the names of resources are changed. These can all refer to one Cognito User Pool for authorization, while allowing customization in the actual function code or in adding multiple S3 buckets or DynamoDB tables if the project requires it. In addition, there are many useful plugins for development with Serverless, including serverless-offline to enable quick iterations on local development.
This setup hits our main goals:
- Always On: AWS allows us to easily set up an always-on system, and Serverless provides many features that help simply start and maintain such a system.
- Low Maintenance: This infrastructure also gives us auto-scaling, allowing the team to be more hands-off on project upkeep, particularly with expected periods of low usage and then spikes as new users explore the prototype.
- Reasonable Cost: None of these features are storage-intensive, and AWS allows us to keep costs low for these systems that do not expect heavy usage in most cases.
Where this doesn’t work
We’ve found that this simplified approach works very well for most of our prototypes. In the majority of cases, we just need a basic infrastructure set up and do not want to worry about fine-tuning the capabilities of that infrastructure. There are some drawbacks to the system that we’ve found.
- Cold starts: The overhead in spinning up a lambda invocation on first request increases the response time, and is particularly noticeable with lambdas written in Java (to a lesser degree with JavaScript and Python). We’ve found that, while annoying, this is acceptable in almost all prototyping cases.
- Deploying ML models: In order to fully prove out ideas in this space we’ve found it necessary to maintain an always-on backend. AWS Lambda has limitations on deployment package size and memory that are restrictive for larger models. The described set up does not work very well by default here, though the same general serverless architecture described above can be set up to communicate with a backend deployed in an EC2 container.
- Orchestrating parallelization: Making simple calls from an AWS Lambda out to S3 or Dynamo works without stress, but orchestrating a parallel response becomes quite challenging. Parallelized computations from a simple approach of invoking many functions and waiting for them to return varies from run to run in both overall timing and the aggregated results. Calling many functions at once to access the same AWS resources can quickly run up against AWS rate limits.
Parallelization is particularly important to process massive amounts of data, a not-infrequent challenge at Tableau and for our prototypes. In our next post, we will discuss some alternative approaches to solve this issue.
Autres sujets pertinents

Which Model Speaks Your Data Language? A User-Centered Approach to Evaluating LLMs for Conversational Visual Analytics
 14 avril, 2026
14 avril, 2026
Rethinking How Data Workers Revisit Analytical Conversations and Communicate Insights
 10 avril, 2026
10 avril, 2026
Stepping through Charted Territory: Creating Interactive Step-by-Step Dashboards Tours
 8 juin, 2025
8 juin, 2025