Deux méthodes de crowdsourcing pour les données




Je passe la plupart de mes journées à créer des visualisations à partir des données que l'on m'envoie. Mais parfois, l'univers en décide autrement. Parfois, un volume énorme de données brutes débarque sans crier gare, et je dois lui donner du sens rapidement. Ou alors, je sais qu'une tendance peut être dégagée des données, mais aucun des ensembles de données que j'utilise ne contient toutes les informations dont j'ai besoin. Comment gérer de telles situations lorsque l'on travaille seul et qu'il y a des centaines, des milliers ou des millions de données à collecter avant de pouvoir commencer à explorer et créer des visualisations ? En appliquant le crowdsourcing aux ensembles de données.
Le crowdsourcing implique de concevoir quelque chose avec l'aide d'autres personnes. Ici, en l'occurrence, c'est un ensemble de données. Chacun y contribue en ajoutant ses propres données, pour créer un ensemble de données que les autres pourront utiliser.
Avec le mouvement récent de la marche des femmes, qui a suscité une forte mobilisation partout dans le monde, j'ai décidé de tenter le crowdsourcing pour obtenir un ensemble de données. Je me suis demandé quelles raisons pouvaient motiver les gens à participer à cet évènement. Pour le savoir, j'ai créé une enquête, qui constitue l'une des deux manières de faire du crowdsourcing pour réunir des données.
Méthode 1 : enquêtes
Si l'on y réfléchit bien, une enquête est un outil servant à collecter des données auprès d'individus dont les expériences s'inscrivent dans un récit global. Les scientifiques et universitaires utilisent les données issues d'enquêtes depuis des centaines d'années. John Snow fut l'un des premiers à nous donner une vue d'ensemble sur l'épidémie de choléra qui a frappé Londres, en menant une étude sur le terrain. Il s'est personnellement entretenu avec les résidents d'une zone touchée par la maladie, puis a collecté les informations obtenues, notamment le nombre de personnes touchées par foyer, le nombre de malades, la durée de leur maladie. Il a donc constitué son propre ensemble de données.
Toute étude scientifique rigoureuse s'appuie sur des enquêtes menées avec soin pour éliminer tout préjugé. Néanmoins, cela ne veut pas dire que les enquêtes rapides et informelles n'ont pas de valeur. Après tout, des données de sondage constituent une enquête en soi. Et même si les enquêtes offrent simplement des données généralisées, ces dernières peuvent révéler des informations exploitables.
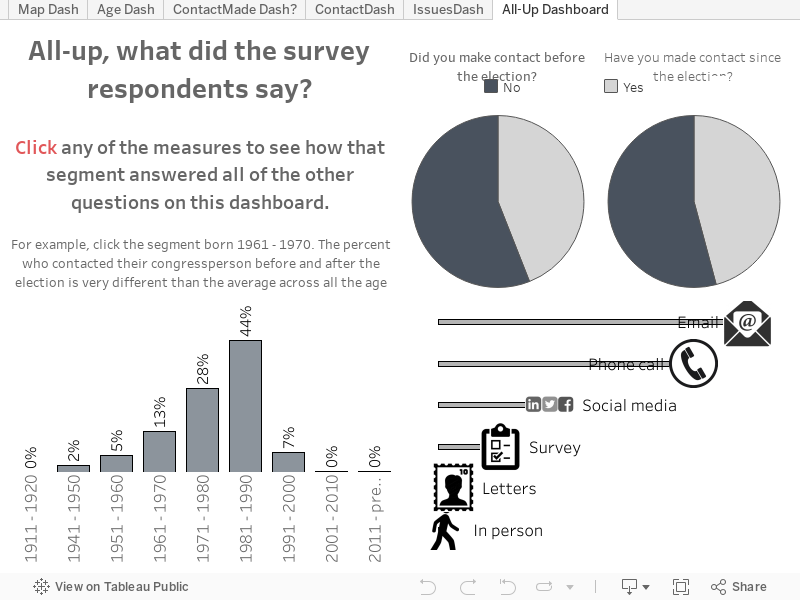
Des outils en ligne comme Google Forms ou SurveyMonkey permettent de créer et de distribuer des enquêtes rapidement, mais il y a quelques pièges à éviter. Le week-end dernier, j'ai rapidement créé une enquête de six questions dans Google Forms. Je voulais créer une visualisation se mettant à jour au fur et à mesure que les réponses sont ajoutées, et j'ai donc opté pour des questions courtes et des réponses concises. Je pensais avoir créé une enquête générant un ensemble de données propre et facile à exploiter dans une visualisation. J'avais tort.
C'est la manière dont j'ai construit les questions et utilisé les options de l'enquête à disposition qui posait problème. J'ai posé les six questions suivantes aux participants américains des marches des femmes, même si d'autres marches ont par ailleurs eu lieu dans le monde :
- Identifiez les trois principales raisons pour lesquelles vous participez à cette marche. Sélectionnez un maximum de trois options dans la liste (« Autre » compte comme une option).
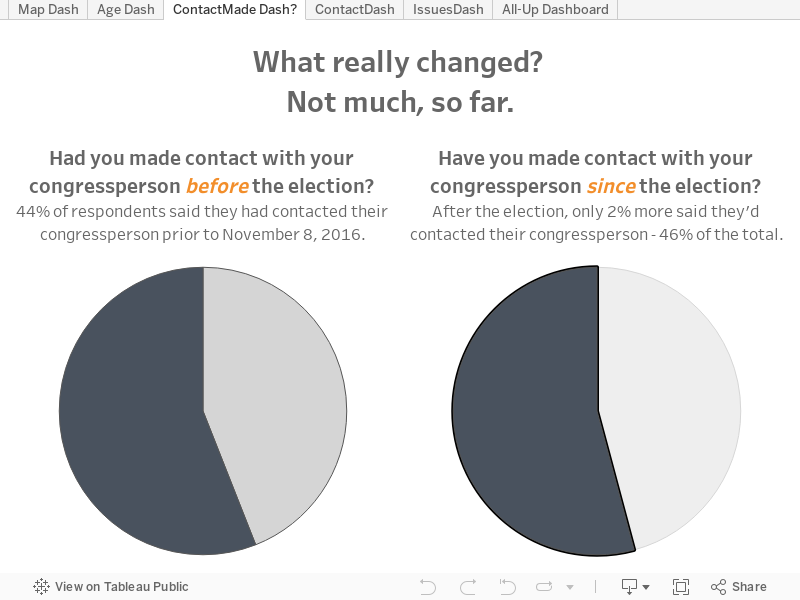
- Avez-vous contacté votre député depuis les élections ? (Oui/Non)
- Si oui, par quel moyen avez-vous contacté votre député ? Sélectionnez autant de réponses que nécessaire dans la liste (« Autre » compte comme une option).
- Avez-vous contacté votre député avant les élections ? (Oui/Non)
- Dans quelle décennie êtes-vous né(e) ? Sélectionnez une option dans la liste.
- Où habitez-vous ?
Lorsque j'ai ouvert la feuille de calcul contenant les résultats, j'ai eu une drôle de surprise.
Mes données avaient besoin d'un bon nettoyage. Pourquoi ? Les questions 1 et 3 étaient problématiques, et pourtant ce sont celles dont les réponses m'intéressaient le plus. Qu'est-ce qui n'allait pas ?
- Les questions à réponses multiples créent une colonne unique, dans laquelle les réponses sont séparées par une virgule ou un point-virgule. Cela signifie qu'avant de pouvoir créer une visualisation à partir de ces réponses, je devais d'abord les séparer en plusieurs colonnes, et que les visualisations créées à partir de ces questions ne se mettaient pas à jour automatiquement. En revanche, les questions fermées (réponse par oui ou par non) ou les questions sur la date de naissance et le lieu de résidence ne posaient pas de problème.
- Le fait de séparer ces réponses en plusieurs colonnes crée un autre problème. Cette répartition sous-entend à tort qu'il existe un ordre dans la sélection des réponses (cette option a été sélectionnée en premier, celle-ci en second, etc.) Le chemin suivi par chaque participant pour donner les réponses (A, B, C ou B, C, A) étant unique, il m'était impossible de regrouper les réponses les plus fréquemment données.
- Je voulais placer la barre suffisamment bas pour permettre à tout le monde de donner une réponse, et j'ai donc ajouté l'option « Autre ». Pourtant, une telle option est une très mauvaise idée sur le plan des données. Ce type de réponse a également nécessité des manipulations pour rapprocher les données.
Comment résoudre le problème des questions à choix multiples ? En permutant les données. Au lieu de présenter mes données en largeur, avec chaque réponse dans une colonne unique, je devais les présenter verticalement et garder les réponses similaires dans la même colonne.
Au lieu de ce tableau :

J'avais besoin de ce tableau :
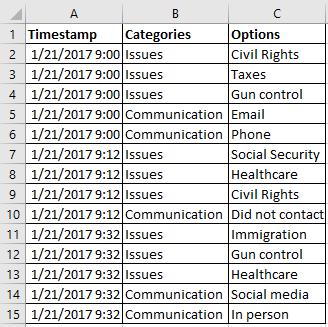
Steve Wexler a publié un article très utile sur la permutation des données dans Tableau, que je recommande fortement.
En raison de la manière dont j'avais conçu mon enquête, j'essayais de collecter des données en direct avec Google Forms, tout en les permutant et en les analysant. J'ai fini par enregistrer les données dans un fichier statique à utiliser pour créer la visualisation, ce qui n'était pas idéal.
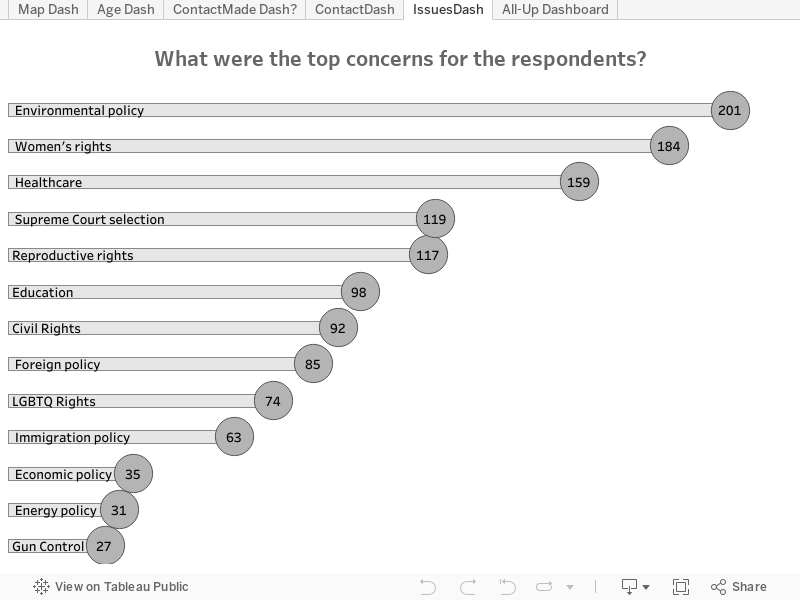
Plus tard dans mon projet, je me suis retrouvée avec 456 réponses à mon enquête. Ce nombre a encore augmenté depuis, malheureusement. J'ai filtré les réponses uniques (généralement les réponses « Autre ») de sorte qu'elles n'apparaissent pas, et j'ai été surprise de constater que la politique écologique était la raison la plus souvent citée par les participants. C'est peut-être lié au fait que la plupart des participants viennent du nord-ouest de la côte du Pacifique, la région d'où je suis originaire.
Désormais, mes visualisations sont donc complètement déconnectées de l'enquête, qui continue de collecter des données. Je ne suis pas très satisfaite de cette situation, mais elle m'a permis de retenir quelque chose de très important sur la manière de structurer les questions d'une enquête. La prochaine fois, je simplifierai mes questions encore plus, ou j'utiliserai la méthode détaillée ci-dessous.
Méthode 2 : feuilles de calcul partagées
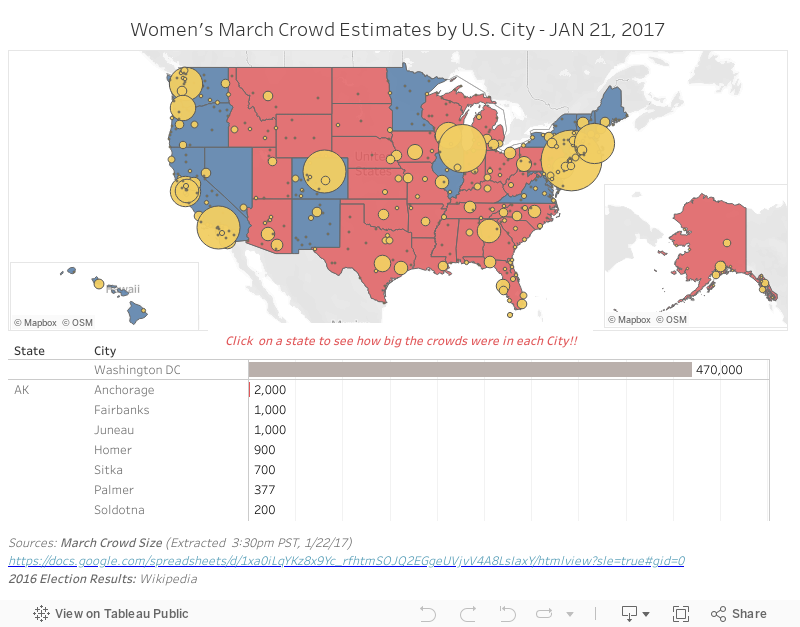
La seconde méthode de crowdsourcing des ensembles de données est le partage de feuille de calcul. C'est une pratique qui existe depuis les débuts d'Internet, mais qui a réellement décollé ces dernières années. Pendant que je collectais des données avec mon enquête, Erica Chenoweth (@EricaChenoweth) et Jeremy Pressman (@djpressman) ont créé une feuille Google Sheets partagée avec des instructions très simples. Ils ont demandé des estimations du nombre de participants aux marches du 21 janvier 2017. Les instructions étaient simples : indiquer le chiffre, avec le nom de la ville, le nom de l'État (le cas échéant), le pays et une source vérifiable pour ces données. Ils ont publié la feuille sur les médias sociaux, et les internautes ont répondu présent. Des participants du monde entier ont ajouté leurs données à la feuille, qui s'est transformée en moins de 24 heures en un ensemble de données que chacun pouvait utiliser.

S'agissait-il d'un ensemble de données parfait pour une visualisation ? Pas vraiment, mais c'était une solution rapide et sommaire répondant à un besoin immédiat. En moins de 24 heures, quelqu'un sur Tableau Public avait déjà nettoyé suffisamment de ces données pour créer une visualisation en les combinant aux résultats des élections. J'ai l'impression que les mordus de données sont bien plus rapides à réagir à ces évènements que les médias eux-mêmes.
Mettons nos expériences en commun
L'un des principaux avantages des données collectées par crowdsourcing est que vous suscitez de l'intérêt, et que chacun peut contribuer. En collaborant, les spécialistes, les structures open data et les data scientists peuvent venir en aide à des gens comme moi qui explorent les données.
Quel type de données ou de projets avez-vous pu concrétiser grâce au crowdsourcing ? Quels sont les avantages et les inconvénients de ce type de données ? Je suis déjà en train de travailler à mon prochain ensemble de données en crowdsourcing et j'ai hâte de pouvoir échanger avec vous à ce sujet.
Autres sujets pertinents
Data Literacy Basics Everyone Should Know
 15 août, 2024
15 août, 2024

Data Literacy for All: Free data skills training for individuals and organizations
How to Spot Misleading Charts, a Checklist
 15 novembre, 2023
15 novembre, 2023
Abonnez-vous à notre blog
Recevez toute l'actualité de Tableau.