Dois métodos para o crowdsourcing de dados




Passo a maior parte dos meus dias visualizando dados que colegas compartilham comigo, mas, às vezes, o mundo tem planos diferentes para você. Sem qualquer aviso, recebemos uma enxurrada de dados brutos e precisamos entendê-los rapidamente. Ou então vemos claramente que há uma história por trás dos dados, mas nenhum conjunto de dados parece ser capaz de revelá-la. Como resolver esse problema sozinho, quando há centenas, milhares ou milhões de pontos de dados para coletar antes das etapas de exploração e visualização? Com o crowdsourcing de dados, é óbvio!
Fazer um crowdsourcing de dados significa criar um conjunto de dados em colaboração com outras pessoas. Cada participante contribui com seus próprios pontos de dados para criar um conjunto de dados que todos possam usar.
Aproveitando a comoção causada pela Marcha das Mulheres, que ocorreu simultaneamente em várias partes do mundo, decidi me aventurar a reunir um conjunto de dados via crowdsourcing. Pensei: quais são as principais questões que estão motivando as pessoas a participar dessa marcha? Para descobrir isso, criei uma pesquisa, que é um dos dois métodos possíveis para fazer um crowdsourcing de dados.
Método 1: Pesquisas
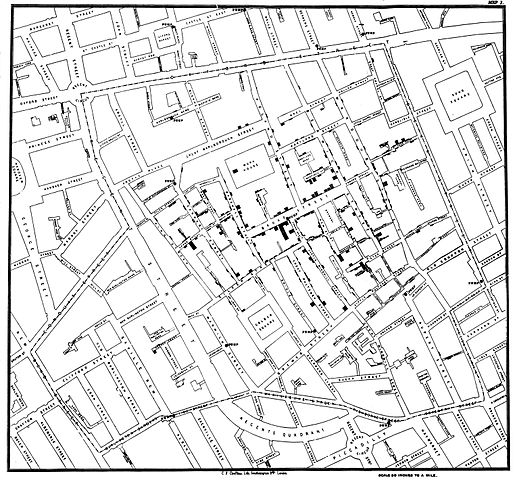
A pesquisa é uma ferramenta usada para coletar dados individualmente. Uma vez reunidos, esses dados contam uma história maior. Cientistas e acadêmicos têm usado dados de pesquisa há centenas de anos. John Snow foi um dos primeiros a nos fornecer uma visão mais clara sobre a epidemia de cólera em Londres realizando uma pesquisa de campo. Ele entrevistou pessoalmente os moradores das áreas afetadas e registrou os dados de seus relatos: quantas pessoas de uma residência contraíram a doença, quantas ficaram doentes e por quanto tempo. Dados puros e simples.
Estudos científicos rigorosos exigem que as pesquisas sejam minuciosamente examinadas para eliminar qualquer tipo de parcialidade, mas isso não significa que uma pesquisa rápida e informal não tenha o seu valor. Afinal, uma enquete também é um tipo de pesquisa. E, embora pesquisas contenham dados genéricos, generalizações desse tipo também podem proporcionar descobertas.
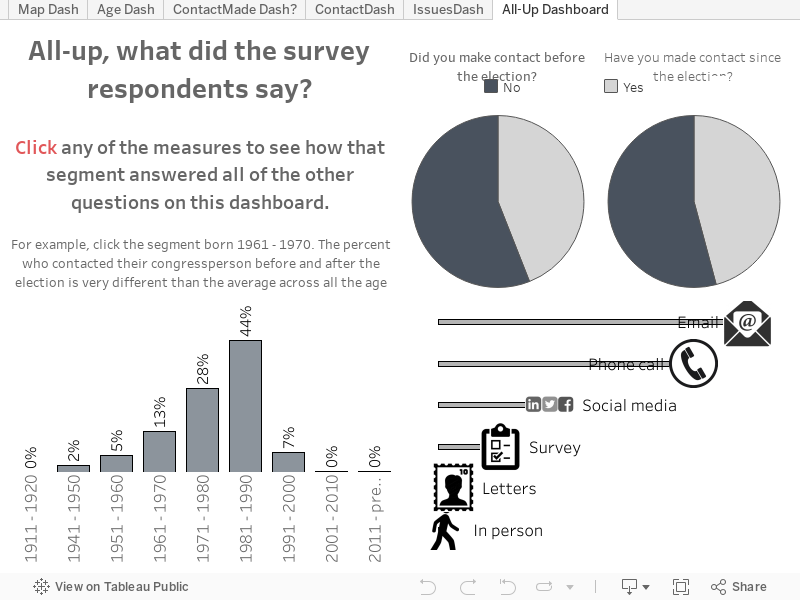
Ferramentas on-line, como o Formulários Google e o SurveyMonkey, nos permitem elaborar e distribuir pesquisas rapidamente e sem custos, mas têm algumas armadilhas. No fim de semana passado, criei uma pesquisa rápida com seis perguntas no Formulários Google. Eu queria criar uma visualização que fosse atualizada à medida que as respostas fossem fornecidas. Então, adicionei poucas perguntas e respostas curtas. Eu achava que tinha elaborado uma pesquisa que resultaria em um conjunto de dados organizado e com o qual poderia criar uma visualização facilmente. Estava enganada.
A estrutura das perguntas e as opções à minha disposição foram a minha ruína. Fiz estas seis perguntas para as participantes da Marcha das Mulheres, que ocorreu simultaneamente em várias partes do mundo:
- Selecione os três principais motivos que levaram você a participar da marcha. (Escolha até três opções da lista, incluindo "Outro")
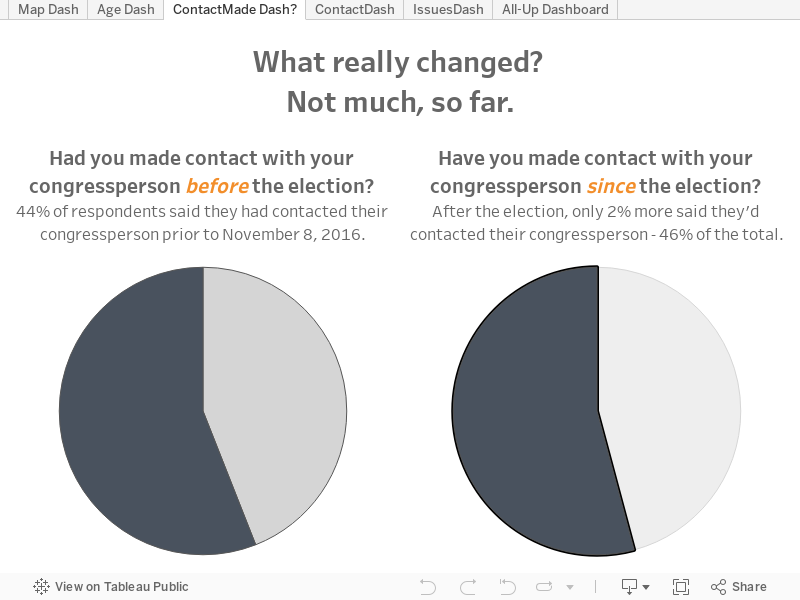
- Você entrou em contato com seu representante no congresso após a eleição? (Sim/Não)
- Caso tenha entrado em contato com seu representante no congresso, como você fez isso? (Selecione todas as opções aplicáveis, incluindo "Outro")
- Você entrou em contato com seu representante no congresso antes da eleição? (Sim/Não)
- Em que década você nasceu? (Selecione uma opção da lista)
- Qual é o seu código postal?
Quando abri a planilha com os resultados, fiquei surpresa.
Meus dados precisavam de muita, muita limpeza. Por quê? A primeira e a terceira perguntas eram o problema, e é claro que elas continham as respostas em que eu mais estava interessada. Onde eu tinha errado?
- Perguntas que admitem mais de uma resposta (escolha até três opções, selecione todas as opções aplicáveis etc.) geram uma única coluna com os valores separados por vírgula ou ponto e vírgula. Isso significa que, antes de poder visualizar as respostas para essas duas perguntas, eu precisava separar as respostas em colunas diferentes, o que impediria a atualização automática da visualização. (As perguntas Sim/Não, por outro lado, funcionaram perfeitamente, bem como os códigos postais e os anos de nascimento.)
- Separar as respostas em várias colunas também gera outro problema. Isso sugere que há uma sequência de seleção (por exemplo, este item foi selecionado primeiro, depois este e, por fim, este). Também significa que o caminho de cada respondente (A, B, C não é o mesmo que B, C, A) é único e que, portanto, eu não poderia agrupá-los pelas respostas mais comuns de todos os participantes.
- Queria que minha pesquisa fosse bastante simples de responder, por isso, “outro” também foi uma escolha natural. No entanto, como uma pessoa que lida com dados, sei que usar a opção “outro” não é uma boa ideia. Permitir essa opção como uma resposta por extenso exigiria que eu ajustasse esses dados também.
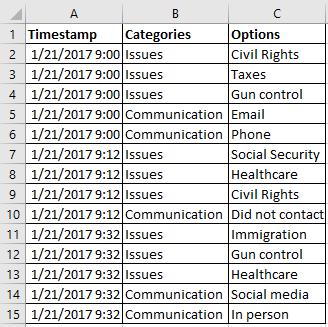
A solução para as perguntas com mais de uma resposta possível? Dinamizar os dados. Isso significa que, em vez de expandir os dados horizontalmente, colocando cada resposta em uma única coluna, eu precisava expandi-los verticalmente e manter dados semelhantes na mesma coluna.
Em vez disto:

Eu precisava disto:
Steve Wexler publicou um excelente texto sobre como dinamizar dados no Tableau; vale a leitura!
Devido à estrutura da minha pesquisa, eu estava tentando coletar dados em tempo real com o Formulários Google, enquanto dinamizava e analisava os dados. Coletei os dados em um arquivo estático para visualizá-los, o que não era ideal.
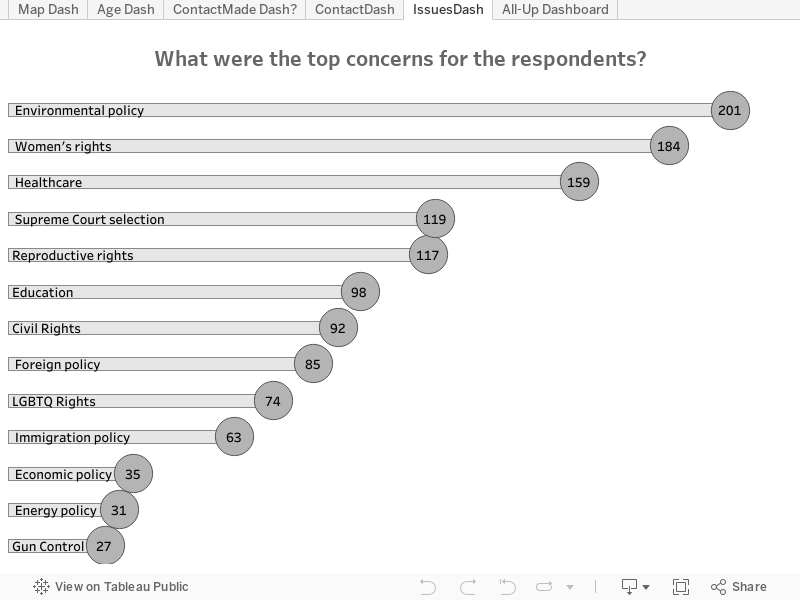
Mais tarde no projeto, eu tinha 456 respostas para a pesquisa (e o número de respostas vêm aumentando desde então). Filtrei as perguntas que tinham apenas uma resposta selecionada (geralmente a opção “Outro”) e fiquei surpresa ao ver que a política ambiental era uma das questões mais citadas entre os respondentes. Isso pode estar direitamente relacionado ao fato de a maioria das respostas ter vindo do noroeste do Pacífico, onde moro.
Minhas visualizações agora são totalmente independentes da pesquisa, que ainda está coletando dados. Não estou satisfeita com isso, mas aprendi uma lição importante sobre como estruturar as perguntas de uma pesquisa. Da próxima vez, simplificarei ainda mais ou usarei o segundo método.
Método 2: Planilhas compartilhadas
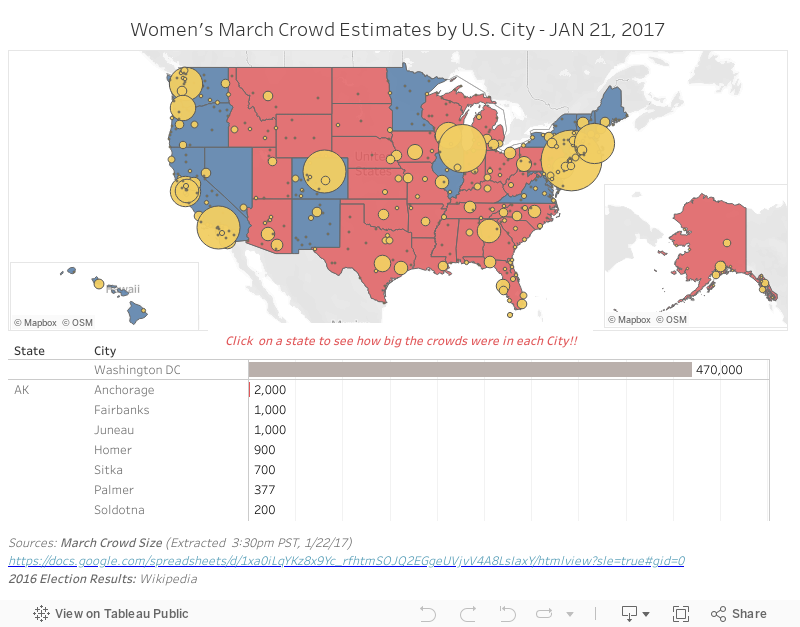
O segundo método para o crowdsourcing de dados envolve o compartilhamento de planilhas. Já fazemos isso desde o início da Internet, mas essa prática se consolidou há alguns anos apenas. Enquanto eu coletava dados para minha pesquisa, Erica Chenoweth (@EricaChenoweth) e Jeremy Pressman (@djpressman) criaram uma planilha compartilhada no Planilhas Google com instruções bastante simples. Eles queriam uma estimativa para o público das marchas em 21 de janeiro de 2017. A planilha tinha instruções simples: incluir os números junto com a cidade, o estado (se aplicável), o país e uma origem verificável dos dados. Eles divulgaram a planilha nas mídias sociais, e ela decolou. Pessoas do mundo inteiro adicionaram dados e, em apenas 24 horas, eles tinham um conjunto de dados que todos poderiam usar.

Era a maneira perfeita de visualizar os dados? Não, mas, do seu jeito rápido e improvisado, atendia à necessidade imediata. Em 24 horas, alguns usuários do Tableau Public já tinham organizado os dados o suficiente para visualizá-los em um painel com os resultados das eleições logo abaixo. Nunca vi a mídia aproveitar dados tão rápido, mas isso não é novidade para quem lida com dados.
Continuar a conversa
Uma das maiores vantagens do crowdsourcing de dados é que você gera interesse e todos se tornam colaboradores. Trabalhando juntos, especialistas de uma determinada área, organizações de divulgação de dados e cientistas de dados ajudam as pessoas a explorar os dados mais a fundo.
Quais tipos de dados e projetos você já viu serem beneficiados pelo crowdsourcing? Quais são algumas das vantagens e desvantagens desse tipo de dados? Já estou trabalhando em meu próximo próximo conjunto de dados via crowdsourcing, então vamos continuar essa conversa!
Histórias relacionadas

Data Literacy for All: Free data skills training for individuals and organizations
How to Spot Misleading Charts, a Checklist
 15 Novembro, 2023
15 Novembro, 2023

Destaque-se em sua busca de emprego com um currículo interativo no Tableau
 8 Dezembro, 2022
8 Dezembro, 2022
Os recrutadores dedicam apenas 6 segundos a uma leitura dinâmica de cada currículo. Demonstre suas habilidades de visualização de dados e destaque-se no processo seletivo ao torná-lo visual e interativo no Tableau.
Subscribe to our blog
Receba em sua caixa de entrada as atualizações mais recentes do Tableau.