Easy Empty Extracts op lokaal niveau
‘Easy Empty Extracts' Dit klinkt haast als een kinderrijmpje. Maar het is eigenlijk een belangrijke Tableau-tip van onze eigen Ryan Stryker, Senior Business Consultant bij Tableau Professional Services. Bedankt, Ryan! Extracten zijn niet moeilijk te verkopen. Bij de lokale materialisatie van de dataweergaven worden de prestaties meestal drastisch verbeterd. En Tableau Server biedt ons een handig platform om alles automatisch te vernieuwen. Bij grote extracten kan het echter behoorlijk tijdrovend zijn om een desktopversie te maken voordat deze op de server wordt gepubliceerd. Begrijpelijkerwijs vragen klanten vaak of er geen manier is om het ‘gewoon door Server te laten doen’. Natuurlijk wel.



Extracten zijn niet moeilijk te verkopen. Bij de lokale materialisatie van de dataweergaven worden de prestaties meestal drastisch verbeterd. En Tableau Server biedt ons een handig platform om alles automatisch te vernieuwen.
Bij grote extracten kan het echter behoorlijk tijdrovend zijn om een desktopversie te maken voordat deze op de server wordt gepubliceerd. Begrijpelijkerwijs vragen klanten vaak of er geen manier is om het ‘gewoon door Server te laten doen’.
Natuurlijk wel.

We hebben al een paar blogposts gezien (met dank aan Russell) met technieken voor het genereren van kleine extracten in Desktop, die vervolgens volledig kunnen worden ingevuld nadat ze zijn gepubliceerd.
Ik heb gebruikgemaakt van een iets flexibelere versie waarbij je alles direct laat bouwen door Server. Ik denk dat een aantal van jullie dit zeer nuttig gaan vinden.
Als eerste stap stel je een booleaanse parameter in, zodat je wat meer controle behoudt:

Geef het besturingselement voor de parameter weer in de werkruimte om gemakkelijk te kunnen schakelen.

Vervolgens hebben we een berekend veld nodig om de gekozen waarde weer te geven.

Nu definiëren we ons extract, waarbij we bovenstaande berekening als filter gebruiken.
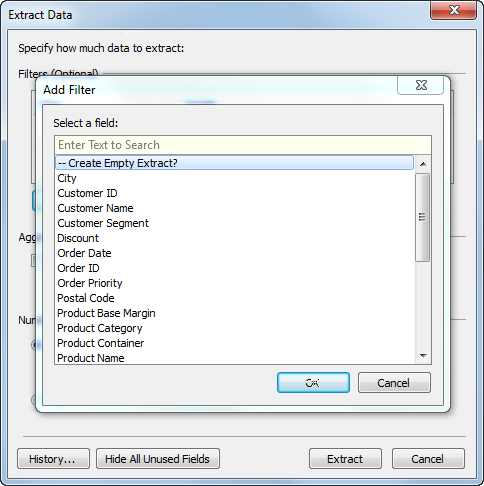
De truc hier is dat je de weergegeven waarde moet uitsluiten ('True' in dit geval), omdat deze voorwaarde direct moet worden geëvalueerd als 'False'. Het doel is immers dat er geen rijen worden geretourneerd.

De definitie van ons extract is dan als volgt:

Tik op Extraheren en selecteer een locatie voor het .tde-bestand. Het proces wordt dan in enkele seconde voltooid. We hebben nu een extract zonder data.
Vervolgens verplaatsen we deze inhoud, misschien in de vorm van een herbruikbare databron, naar de server. De kritische stap is om de parameter om te draaien ...

... en te publiceren.
De gepubliceerde versie bevat niet de geforceerde foutdefinitie die is opgenomen in het extract, dus bij elke vernieuwing (direct of volgens schema) wordt het extract volledig ingevuld.
De bovenstaande techniek is meer geschikt voor een extract dat deel uitmaakt van een gedeelde databron dan voor een extract binnen de context van een werkmap. Dit komt omdat we het extract waarschijnlijk nodig hebben aan het begin van de ontwikkelingscyclus, waarbij het voor de hand ligt om Data Server te gebruiken in onze workflow.
Daarnaast leidt een leeg extract in een werkmap, zelfs als we weergaven hebben ontwikkeld met een liveverbinding, ertoe dat er geen data aanwezig zijn op het moment van publicatie en dat de gegenereerde miniaturen leeg zijn.
Verwante verhalen
Who is Einstein Copilot for Tableau for?
 10 april, 2024
10 april, 2024

Securely Access and Analyze All of Your Data with Data Connect for Tableau Cloud
Tableau Prep Conductor Supports Custom Schedules
 15 maart, 2024
15 maart, 2024
Subscribe to our blog
Ontvang de nieuwste updates van Tableau in je inbox.