Excavating Data Gems from Wikipedia




It wasn't that long ago that I was in college being warned by my teachers not to use Wikipedia to do research for papers. Believing that academics were often too cautious and afraid when it comes to technology, I ignored them. The trick was looking at the footnotes of the Wikipedia article when you are going to pull a fact off of there and referencing whatever they referenced as the source...sneaky right?
These days, I'm sure it's hard for many of us to imagine a world where we couldn't receive instant gratification when suddenly filled with the burning desire to know what year Twinkies were invented. Or looking up who originally sang a song that you love and ending up falling into a musical rabbit hole and coming out the other side realizing that you really respect the work of Burt Bacharach.

I really love the song "I Just Don't Know What to Do with Myself"
Wikipedia is perceived to be so important that an article in Wired magazine titled "Why Wikipedia is as Important as the Pyramids" stated:
The site’s monumental compilation of 19 million entries in 282 languages has already had a greater cultural impact worldwide than most of the other 936 sites recognized for “outstanding universal value” on the World Heritage List...
But Wikipedia isn't just a cultural treasure or a great research source for procrastinating college students...it's also a really great place to find datasets. Just ask Peter Gilks, who often uses Wikipedia as a source for his excellent vizzes like this one on the World's Largest Stadiums:

Take a look at the link for Wikipedia page on the world's largest stadiums. With the data neatly arranged in a table like that, it's easy to just copy that table and paste it directly into Excel for cleanup, or even directly into Tableau!
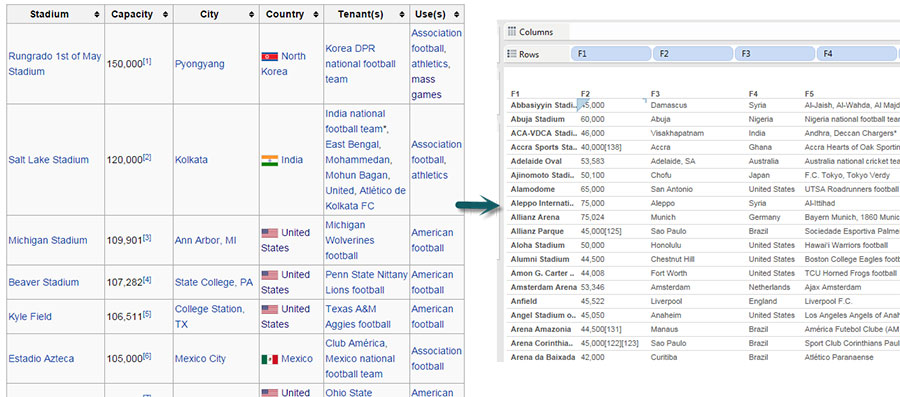
The results of a direct copy/paste from Wikipedia into Tableau
As much fun as it can be to dig through random articles until something interesting comes up, Wikipedia
actually has a very handy list of featured lists, many of which are already in a usable table format like the Stadiums page.
Another cool thing you can do with all the information out there on Wikipedia is combine tables to dig deeper into a topic. For example, you could take this table of guest stars on The Simpsons and use the production code to join it to these tables of all the episodes to see how certain guest stars correlated with number of U.S. viewers.
Just because the data in a Wikipedia article isn't in a table doesn't mean it's impossible to get besides by hand. I was looking at a list of Glee episodes and noticed that when you click through the links of each episode, you get a page that's pretty standard across all the episodes and always has this box in the corner:
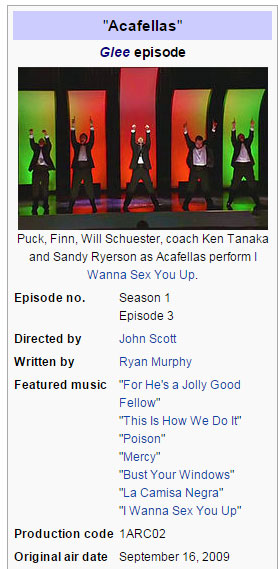
This episode was awesome because I love new jack swing.
There's some additional information here that wasn't in the original table: featured music. I used import.io to automatically visit each of these episode pages and pull the songs. I could even take it a step further and scrape info about the songs themselves from the links on the episode pages:
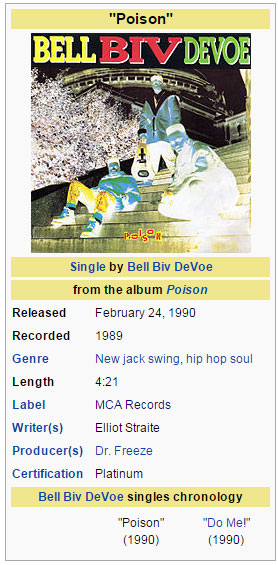
It's NOT drivin' me out of my mind! Because this data wasn't hard for me to find.
Speaking of musical TV shows, I was delighted when I found out that the Wikipedia pages for Dancing with the Stars contained not only information on episodes, but all the scores for every dance that's ever been judged on that show! Using a combo of import.io, copy/paste, and some cleaning up in Excel, I was able to get a pretty cool dataset about the show's performances over the past 19 seasons. I've only barely scratched the surface of exploring the data, but here's some preliminary findings:

Hopefully you are starting to get ideas of data you can get off of Wikipedia. A little birdie told me it might be a good idea to start putting together an interesting Wikipedia dataset...
관련 스토리
Meet Iron Viz 2024 Finalist Chris Westlake
 2024/04/22
2024/04/22
Visualizing Climate Change: Expert Tips from #TheSDGVizProject Leaders
 2024/04/22
2024/04/22
Meet Iron Viz 2024 Finalist Jessica Moon
2024/04/15
Subscribe to our blog
받은 편지함에서 최신 Tableau 업데이트를 받으십시오.