Dos métodos para el crowdsourcing de datos




Dedico la mayor parte de mis días a visualizar datos que me envían. Sin embargo, en ocasiones, el mundo tiene planes diferentes para mí. A veces, sin ningún tipo de advertencia, nos vemos inundados de datos que debemos interpretar rápidamente. Otras veces, sabemos que hay una historia esperando ser descubierta, pero ningún conjunto de datos la proporciona por sí solo. Como individuos, ¿cómo podemos afrontar esta situación cuando hay cientos (miles, incluso millones) de puntos de datos que se deben recopilar antes de explorarlos y visualizarlos? Por supuesto, la respuesta está en el crowdsourcing de conjuntos de datos.
El crowdsourcing implica trabajar colaborativamente con otras personas. En este caso, se trata de generar conjuntos de datos. Cada uno aporta sus propios puntos de datos para crear un conjunto de datos que otros puedan usar.
Debido a la repercusión que tuvo la Women's March (Marcha de las mujeres), con manifestaciones en todo el mundo, intenté recopilar un conjunto de datos a través del crowdsourcing. Me hice la siguiente pregunta: ¿cuáles son los problemas principales que motivaron la marcha? Para averiguarlo, generé una encuesta, que es una de las dos formas de recopilar datos mediante el crowdsourcing.
Método 1: encuestas
Si se pone a pensarlo, una encuesta es una herramienta que se utiliza para recopilar datos de individuos, cada uno de los cuales ofrece una pequeña parte de algo más grande. Los científicos y los académicos vienen utilizando datos de encuestas desde hace cientos de años. Por ejemplo, John Snow fue el primero en proporcionar un panorama general claro de la epidemia del cólera mediante una encuesta realizada en Londres. De manera personal, entrevistó a los residentes de la zona afectada y, uno por uno, recopiló los datos que ellos compartieron: cantidad de enfermos por hogar, cantidad de enfermos en total, duración de la enfermedad, etc. Datos puros y simples.
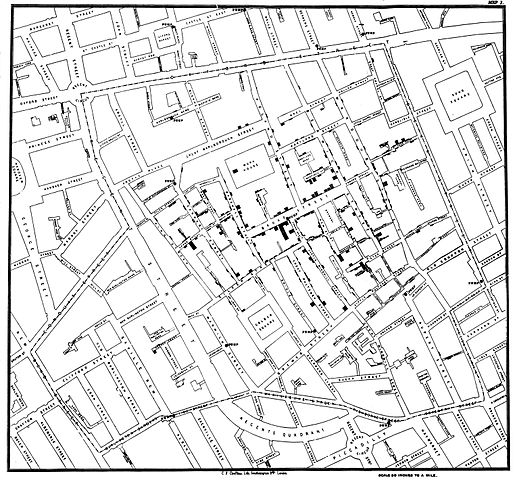
Los estudios científicos más rigurosos exigen que las encuestas se revisen cuidadosamente para que no sean tendenciosas, pero eso no quiere decir que una encuesta rápida e informal no nos pueda proporcionar algo de valor. De hecho, los sondeos no son más que encuestas. Y, aunque las encuestas proporcionen datos generalizados, dichas generalizaciones pueden ofrecer información valiosa.
Las herramientas en línea, como Formularios de Google y SurveyMonkey, nos permiten generar y distribuir encuestas de manera rápida y económica. Sin embargo, se deben tener algunas precauciones. El fin de semana pasado, generé una encuesta rápida de seis preguntas con Formularios de Google. Quería producir una visualización que se actualizara a medida que llegaran nuevas respuestas. Por ese motivo, me aseguré de que las preguntas fueran cortas y las respuestas, concisas. Creía haber generado una encuesta que produciría un conjunto de datos organizado y fácil de visualizar. Estaba equivocada.
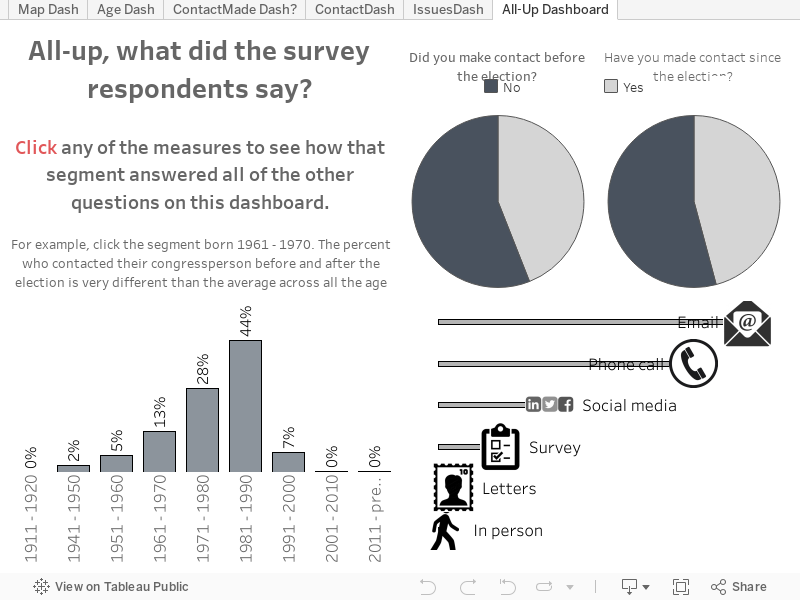
La formulación de las preguntas (junto con las opciones de encuesta disponibles) fue mi perdición. Hice las siguientes seis preguntas a participantes estadounidenses de la Women's March, evento que tuvo lugar en diferentes partes del mundo:
- Identifique las tres preocupaciones principales que lo motivan a marchar. (No seleccione más de tres opciones de la lista. La opción “Otra” se encuentra disponible).
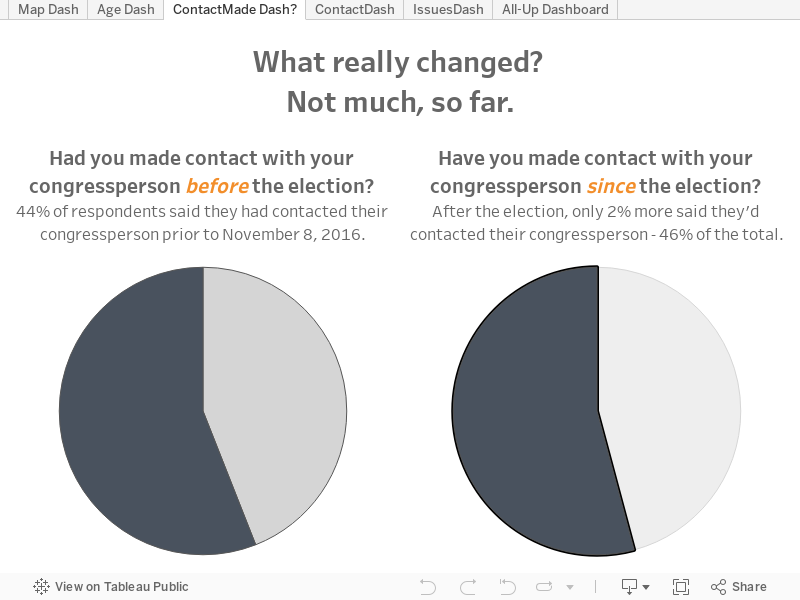
- ¿Se puso en contacto con su diputado desde las elecciones? (Sí/No).
- Si lo hizo, ¿qué métodos utilizó para ponerse en contacto con él? (Seleccione tantas opciones de la lista como prefiera. La opción “Otra” se encuentra disponible).
- ¿Se puso en contacto con su diputado antes las elecciones? (Sí/No).
- ¿En qué década nació? (Seleccione una opción de la lista).
- ¿Cuál es su código postal?
Al abrir la hoja de cálculo con los resultados, me sorprendí un poco.
Era necesario organizar los datos. Era muy necesario. ¿Por qué? Los problemas provenían de las preguntas 1 y 3, que, por supuesto, contenían las respuestas más interesantes para mí. ¿Qué había hecho mal?
- Las preguntas de selección múltiple generan una columna individual con las respuestas separadas por coma o punto y coma. Antes de que pudiera visualizar esas dos preguntas, debía separar primero las respuestas en diferentes columnas. Además, las visualizaciones tampoco podrían actualizarse de manera automática. (Por otro lado, las preguntas cerradas [sí/no] funcionaron perfectamente, al igual que la de los códigos postales y la de los años de nacimiento).
- La separación de las respuestas en columnas múltiples también genera un problema. Sugiere que hay una secuencia en la selección (es decir, los elementos se disponen por orden). Esto implica que el orden de selección de cada encuestado es único (por ejemplo, [A, B, C] no es lo mismo que [B, C, A]). Por lo tanto, no podía agruparlos según las selecciones más comunes entre todos los encuestados.
- Quería que no hubiera ningún tipo de dificultad, de manera que todos pudiesen contestar mi encuesta. Por ese motivo, pensé que la opción “Otra” sería apropiada. Sin embargo, desde el punto de vista de los datos, la opción “Otra” no es una buena idea. Puesto que la opción “Otra” permitía la inclusión de respuestas alternativas, también tuve la necesidad de conciliar esos datos.
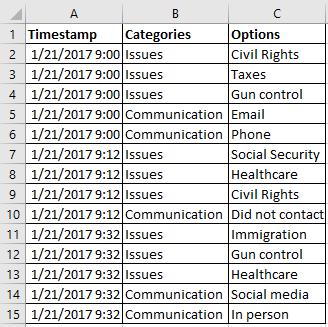
¿Cuál fue la solución para las preguntas de selección múltiple? Tuve que hacer una tabla dinámica con mis datos. En vez de mostrar mis datos de manera horizontal, con cada respuesta en una columna individual, fue necesario disponerlos verticalmente. De este modo, todos los datos relacionados estarían en una sola columna.
En vez de esto:

Fue necesario esto:
Steve Wexler tiene una publicación maravillosa acerca de cómo generar tablas dinámicas con sus datos en Tableau. Vale la pena leerla.
Debido a la forma en que había generado la encuesta, intentaba recopilar datos en vivo con Formularios de Google al mismo tiempo que generaba las tablas dinámicas y las analizaba. Como último recurso, capturé los datos en un archivo estático para visualizarlos, lo cual no es ideal.
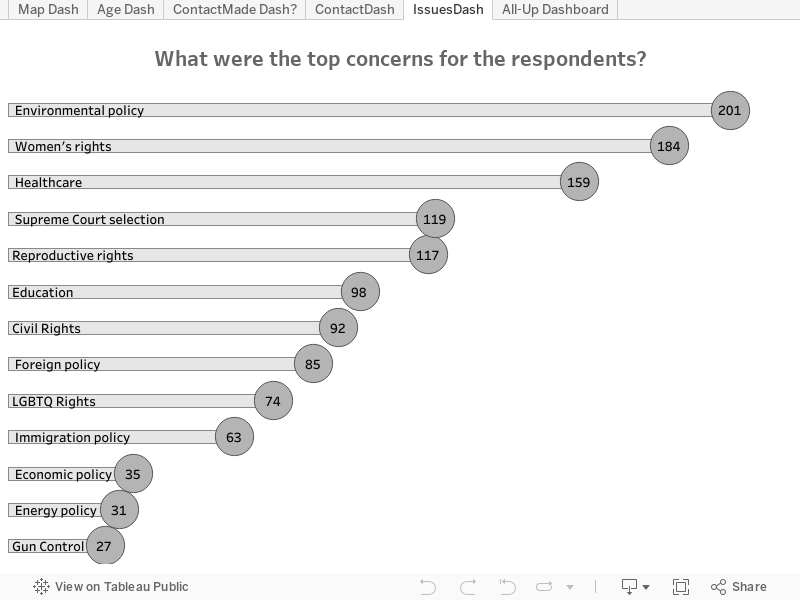
Mucho después de iniciado el proyecto, la encuesta tenía 456 respuestas (aunque el número ha aumentado desde entonces). Filtré las preocupaciones con una sola respuesta (que, a menudo, eran las provenientes de la opción “Otra”). Me sorprendió un poco descubrir que las políticas medioambientales fuesen la preocupación de mayor peso entre los encuestados. Seguramente eso tenía que ver con el hecho de que la mayor parte de los encuestados estaban ubicados en la zona noroeste del Pacífico, es decir, mi región.
Ahora, mis visualizaciones están completamente separadas de la encuesta, que aún sigue recopilando datos. No estoy conforme con esto, pero aprendí una lección importante acerca de cómo estructurar las preguntas de una encuesta. La próxima vez, lo simplificaré aún más o utilizaré el método siguiente.
Método 2: hojas de cálculo compartidas
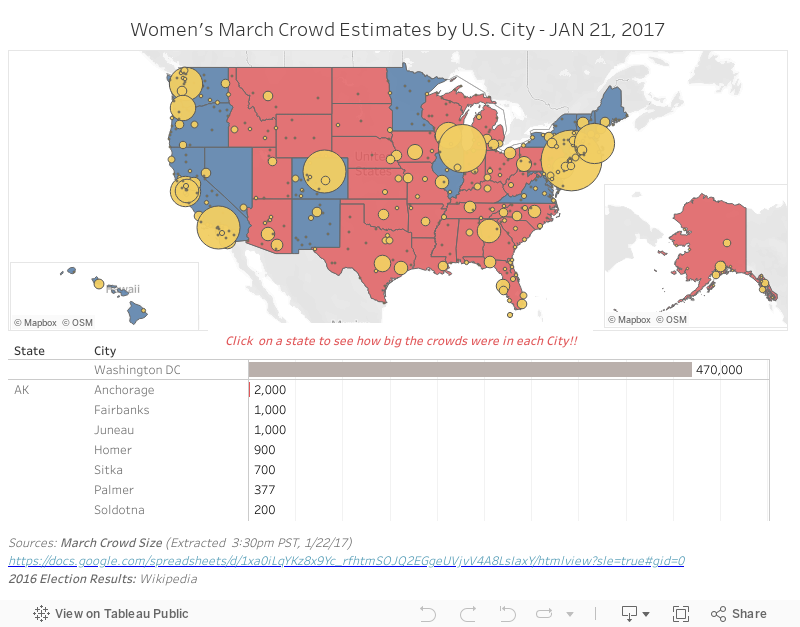
El segundo método para el crowdsourcing de conjuntos de datos implica compartir hojas de cálculo. Venimos haciendo esto desde el comienzo de Internet, pero ha cobrado vigencia desde hace poco tiempo. Simultáneamente a la recopilación de datos a través de mi encuesta, Erica Chenoweth (@EricaChenoweth) y Jeremy Pressman (@djpressman) crearon una Hoja de cálculo de Google compartida con instrucciones muy simples. Solicitaron cifras aproximadas sobre las multitudes que habían asistido a las marchas del 21 de enero de 2017. Las instrucciones eran sencillas: incluir la cifra, la ciudad, el estado (si corresponde), el país y una fuente de datos verificable. Compartieron la hoja de cálculo a través de las redes sociales y se propagó rápidamente. Personas de todo el mundo agregaron datos y, en menos de 24 horas, contaban con un conjunto de datos que todos podían usar.

¿Era perfecta para la visualización? No. El método era rápido y desorganizado, pero respondía a una necesidad inmediata. En menos de 24 horas, una persona de la comunidad de Tableau Public ya había organizado los datos lo suficiente como para visualizarlos, con los resultados de las elecciones por debajo. Los medios no recopilan información con esta velocidad, pero las personas que trabajan habitualmente con datos sí lo logran.
Seguir dialogando
Una de las ventajas principales del crowdsourcing de datos es que se genera interés. Todo el mundo contribuye. Expertos en la materia, organizaciones de datos abiertos y científicos de datos, por igual, trabajan de manera colaborativa para ayudar a personas como yo a explorar en profundidad.
¿Qué tipos de datos y proyectos conoce que se hayan vinculado a través del crowdsourcing? ¿Cuáles son algunas de las ventajas y desventajas de este tipo de datos? Ya estoy trabajando en mi próximo conjunto de datos recopilado a través del crowdsourcing. Me encantaría seguir con esta conversación.
Historias relacionadas

Data Literacy for All: Free data skills training for individuals and organizations
How to Spot Misleading Charts, a Checklist
 15 Noviembre, 2023
15 Noviembre, 2023

Diferénciese de los demás candidatos con un currículum interactivo hecho en Tableau
 8 Diciembre, 2022
8 Diciembre, 2022
Los reclutadores dedican solo 6 segundos a revisar cada currículum. Demuestre sus habilidades de visualización de datos creando una visualización y haciéndola interactiva en Tableau y destáquese entre los candidatos.
Suscribirse a nuestro blog
Obtenga las últimas actualizaciones de Tableau en su bandeja de entrada.