Easy Empty Local Extracts
Learn how to quickly define extracts in Tableau Desktop and have Server do all the retrieval work.



The modern Tableau Server offers Creators a Desktop-like experience for establishing database connections and drawing extracts. A Server’s resources and network position typically give it advantages over Desktop for this task in particular.
For a variety of reasons though, it remains common practice to create extracts within Desktop, which can be time-consuming for large datasets or slow sources. Customers often ask if there’s a way, even when defining extracts from a workstation, to “just have Server do it.” Sure there is. Here’s one straightforward method.
The first step is to establish a Boolean parameter to control things:
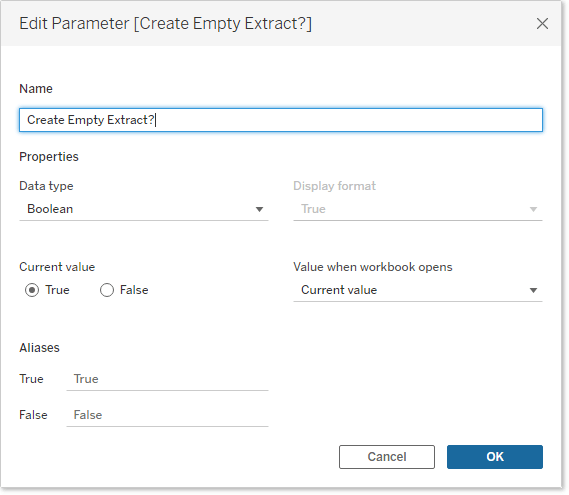
Show the parameter control in the workspace for easy toggling.
Next, we’ll need a calculated field to expose the parameter value:
![Image of a Tableau user creating a calculated field labeled "Create Empty Extract?" with [Create Empty Extract?] entered in the Calculated Field box](/sites/default/files/2023-01/createempty.png)
Now we define our extract, using the above calculation as a filter:
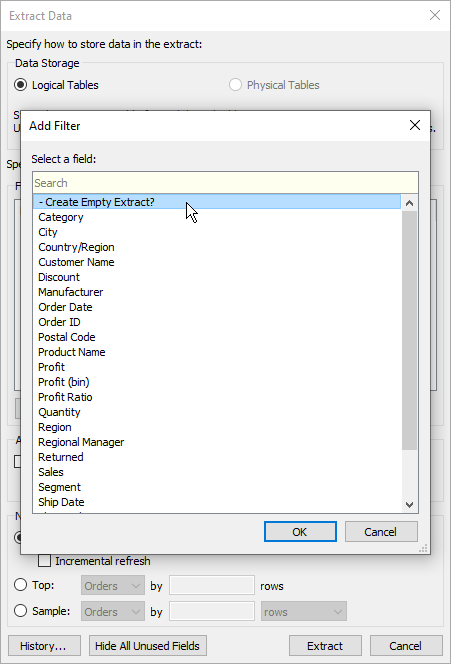
The trick here is to exclude the exposed parameter value (“True”, in this case), because we need this condition to evaluate false for all rows. The goal, after all, is for no data to be returned.
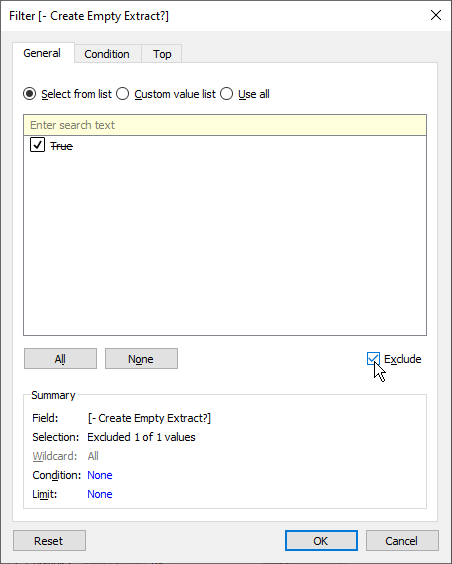
Our extract definition now looks like this:
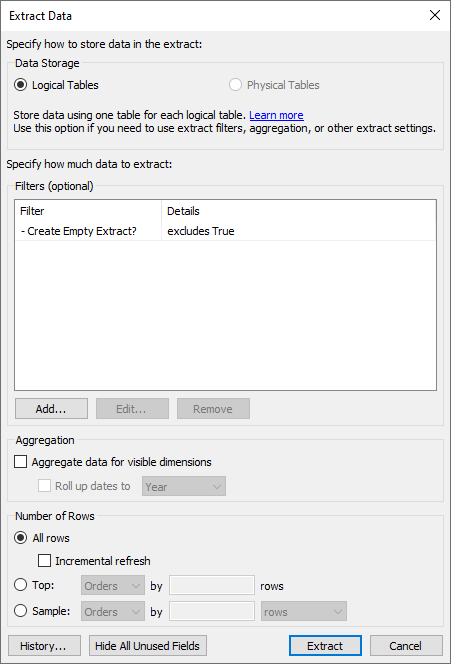
Add any other necessary filters, click Extract, and the process should be finished in seconds. We now have an extract with no data in it at all.
Next, we'll move this content—perhaps in the form of a reusable data source—to the server. The critical step is to flip the parameter, like so…
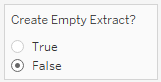
…and publish.
The published version doesn't contain the forced fail condition in the extract filter, so any refresh–immediate or on a schedule–will populate the extract in full.
This technique may be more appropriate for a published data source than for an embedded workbook connection, as you’ll need populated data to even begin viz development. However, you could also publish a workbook to have its extract populated, then download it again to continue visualizing.
Historias relacionadas
Who is Einstein Copilot for Tableau for?
 10 Abril, 2024
10 Abril, 2024

Securely Access and Analyze All of Your Data with Data Connect for Tableau Cloud
How Can I Trust Einstein Copilot for Tableau?
 2 Abril, 2024
2 Abril, 2024
Suscribirse a nuestro blog
Obtenga las últimas actualizaciones de Tableau en su bandeja de entrada.