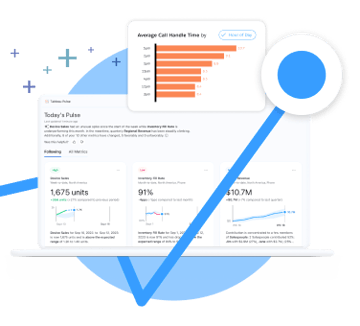
Explore data, deliver insights, and take action with Tableau AI.
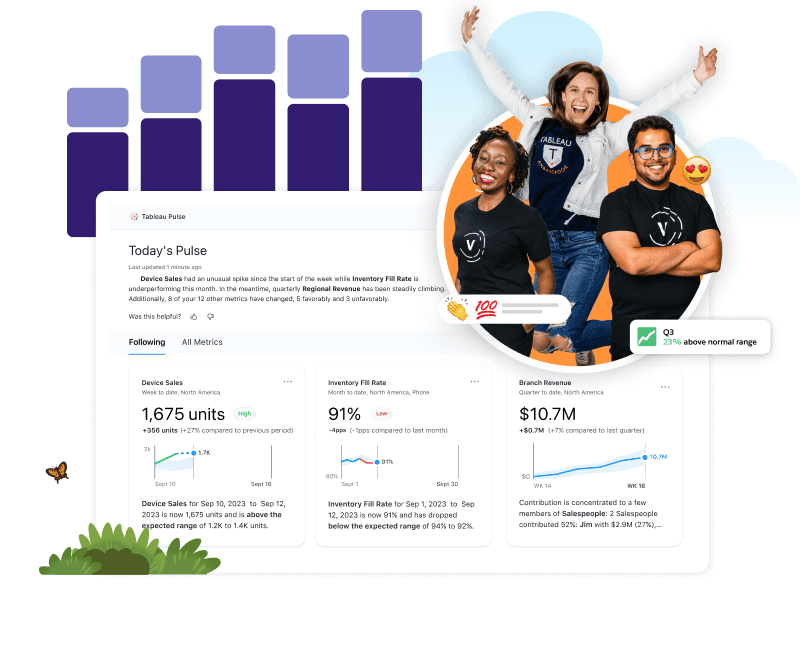
Accelerate decision-making and eliminate repetitive tasks with Tableau Pulse and Einstein Copilot for Tableau. Intelligent analytics at scale.
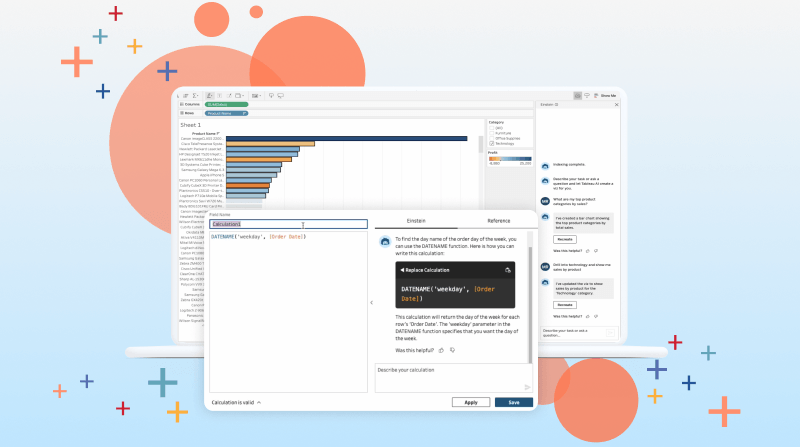
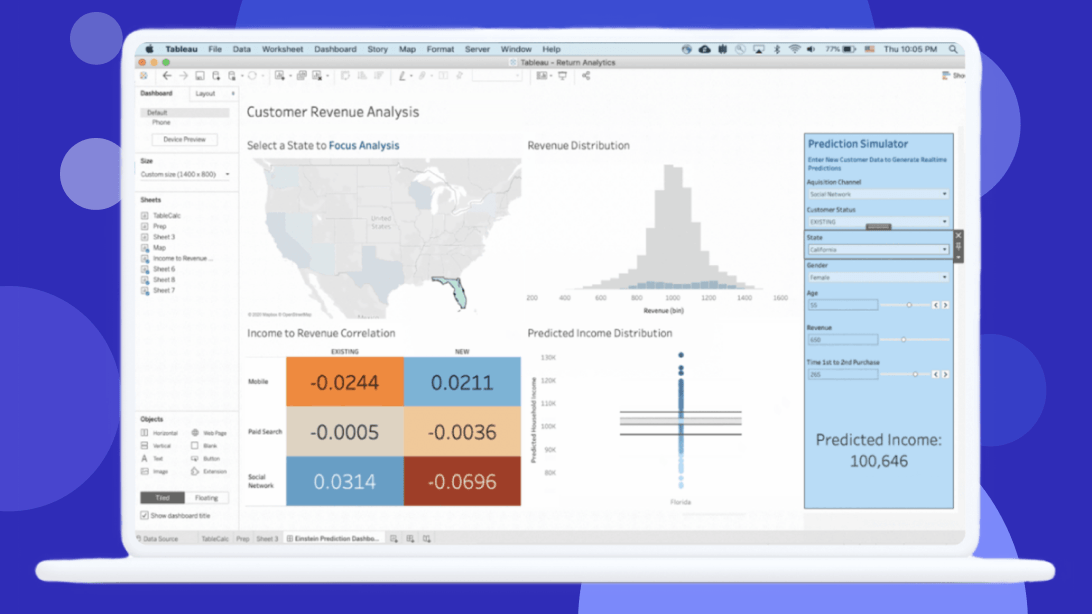
Create data visualizations with a trusted AI assistant.
Einstein Copilot for Tableau reduces the barrier to entry when creating data visualizations in Tableau. It uses trusted AI to guide you through viz creation so you can prep your data, explore it, uncover trends, and share insights with ease.
Watch the demo and sign up for the beta
Learn more about Tableau’s AI offerings

Ride the data wave.
Join the DataFam on Salesforce+ to watch all the Tableau Conference highlights — for free, from anywhere.
Register for Salesforce+ April 30–May 1, 2024 | Salesforce+


Create and share on Tableau Public
Join the newsletter and find daily inspiration with the Viz of the Day. Yours could be featured next!
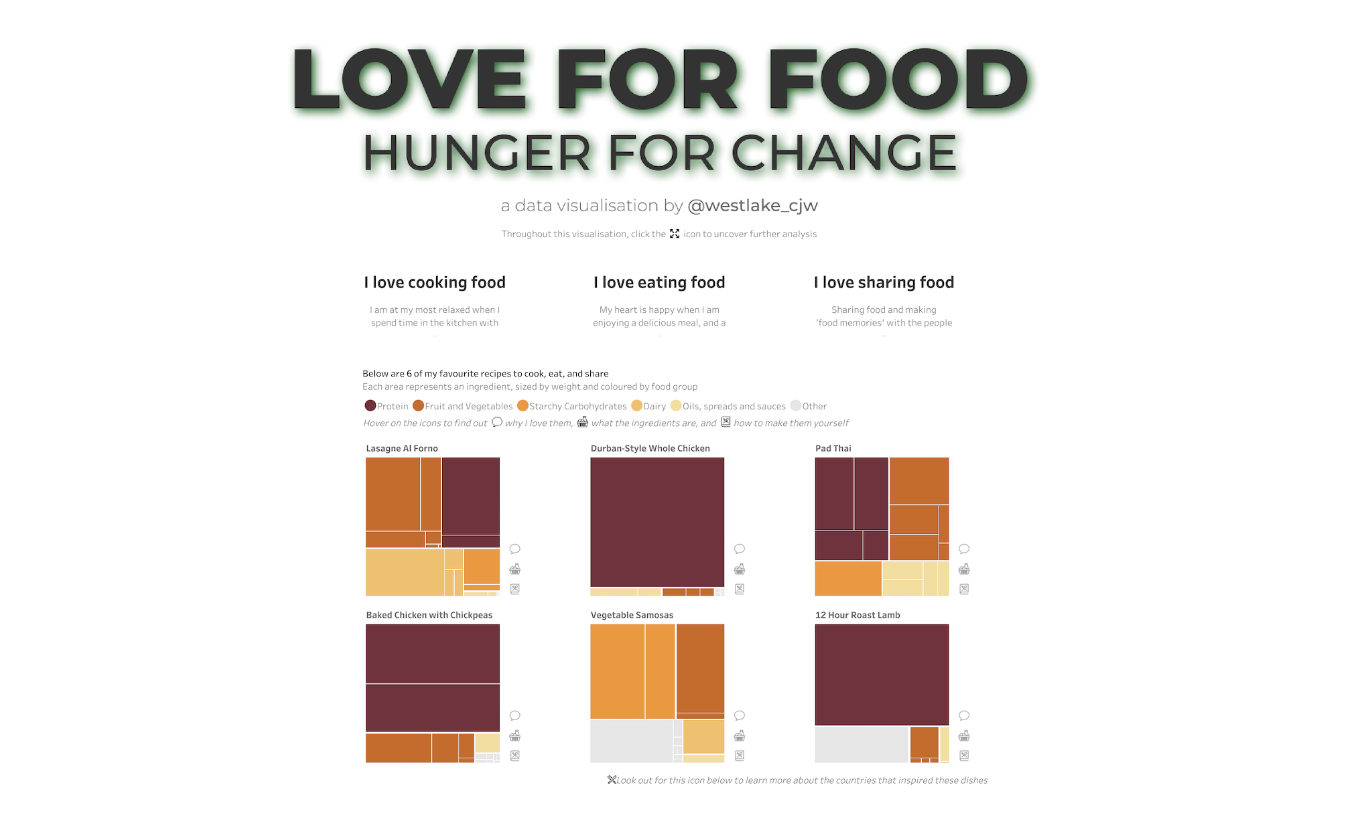
Love For Food: Hunger For Change
Explore this #VizOfTheDay by #IronViz 2024 finalist Chris Westlake visualizing global hunger data and initiatives for food security. With a love for food and a hopeful message, Chris shares his favorite recipes. Catch him on stage at #Data24!
Interact with the viz
DataFam Explained
The #DataFam is your gateway to unlimited learning, inspiration and connection. Discover four tips to connect with other Tableau users passionate about data visualization, analytics, and data storytelling.
Watch NowAnalytics for everyone
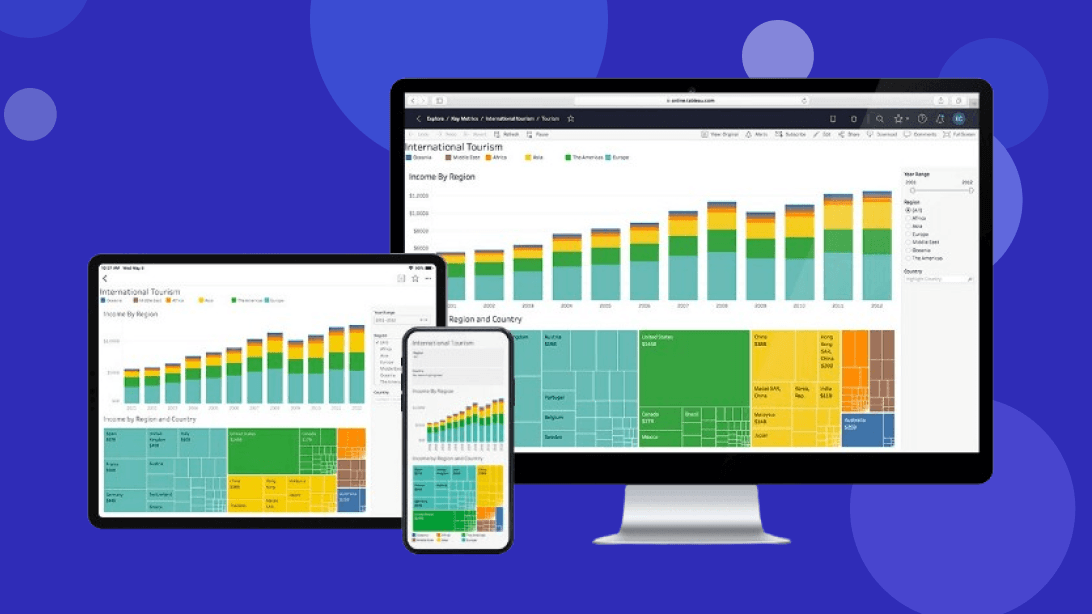
With any data, from anywhere.




Get AI-powered analytics with Tableau’s latest product release.
New in 24.1: Tableau Pulse GA, Amazon Marketplace availability, and Viz Navigation for Text Table.