Announcing real-time analytics with SQL Server 2016: Our performance test results




Today, Microsoft announced the launch of its latest version of its SQL Server product, SQL Server 2016. Microsoft asked us to run some early performance tests on Tableau and the results were pretty impressive, so we thought we’d share a little more detail with you here.
What did we test?
We ran through a subset of the TPC-H battery of tests, which are designed to “examine large volumes of data, execute queries with a high degree of complexity, and give answers to critical business questions,” comparing SQL Server 2016 and its new Clustered Columnstore Index for transactional databases vs. SQL 2012 and a row store schema. We also used the flight info data set—that’s a 285GB data set with the largest table containing 157,089,894 flight records—to compare SQL Server 2016 Clustered Columnstore Index vs SQL Server 2014 row store schemas.
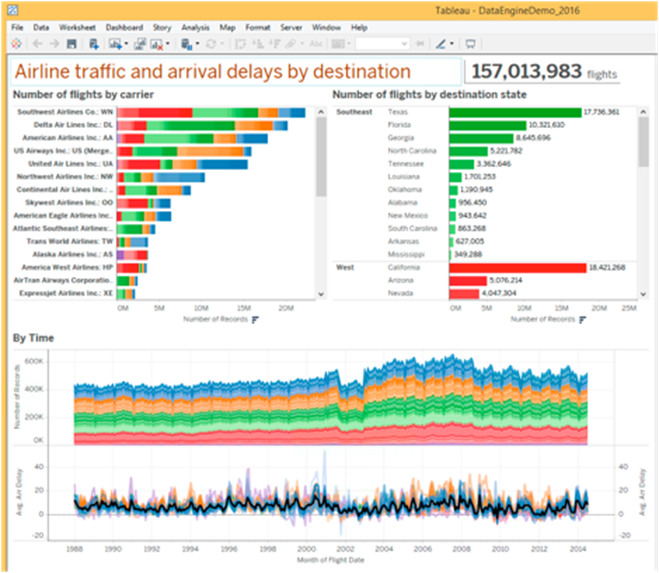
What were the results?
Overall, we saw an average query performance increase of over 190 percent, but the longest-running, most complex queries were also the ones where we saw the biggest gains. The longest-running query ran in 3.83 seconds in SQL Server 2016 compared to 3048 seconds in SQL Server 2014—that’s a 795x performance improvement! Here is the full set of test results by query:
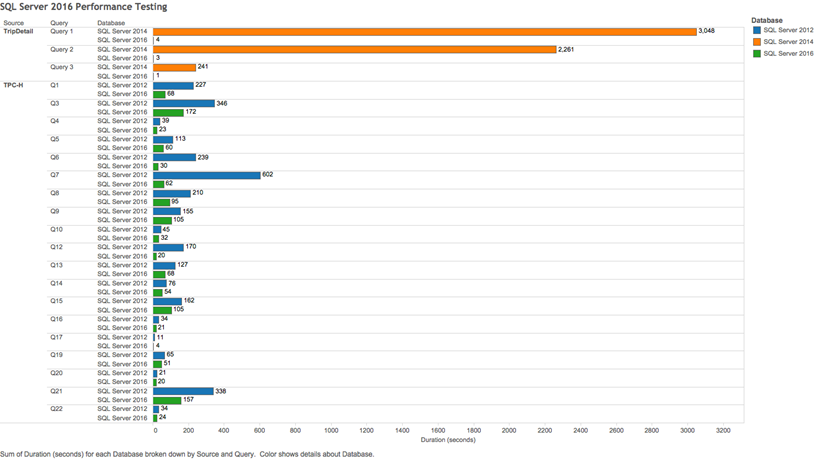
What does this mean to you?
If you use SQL Server as your data source, you’re going to be able to explore your data much more quickly. But even more than that, you can actually do real-time analytics against your operational data store running SQL Server 2016 as well whereas in the past, it would have been much more likely that data was being moved from the transactional store to another data store optimized for reporting and analytics.
Caveat: Your mileage will vary
While these are great results, do keep in mind: 1) not every query we tested saw a performance improvement and your unique scenarios will likely see different results than we saw here, and 2) the performance gains were most pronounced on large data sets. If you have a smaller data set, the performance gains may not be as noticeable for you. That said, we’re impressed with what we’ve seen from this latest version of SQL Server and see great increasing value for the many joint Tableau and SQL Server customers.
To learn more about Tableau and SQL Server, see our SQL Server technology page.
相关故事
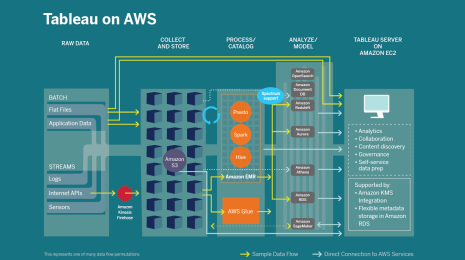
Tableau + AWS: Accelerating your digital transformation with Modern Cloud Analytics
 2023/11/27
2023/11/27
Tableau and AWS help customers digitally transform with Modern Cloud Analytics, combining technical resources and expertise with our vast partner networks.
Streaming Analytics with Tableau and Databricks
 2023/07/04
2023/07/04

4 Actions Business Leaders Can Take to Scale Data and Analytics in the Cloud with Tableau and Snowflake
Subscribe to our blog
在您的收件箱中获取最新的 Tableau 更新。